 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal discovery with endogenous context variables
Dec 06, 2024



Causal systems often exhibit variations of the underlying causal mechanisms between the variables of the system. Often, these changes are driven by different environments or internal states in which the system operates, and we refer to context variables as those variables that indicate this change in causal mechanisms. An example are the causal relations in soil moisture-temperature interactions and their dependence on soil moisture regimes: Dry soil triggers a dependence of soil moisture on latent heat, while environments with wet soil do not feature such a feedback, making it a context-specific property. Crucially, a regime or context variable such as soil moisture need not be exogenous and can be influenced by the dynamical system variables - precipitation can make a dry soil wet - leading to joint systems with endogenous context variables. In this work we investigate the assumptions for constraint-based causal discovery of context-specific information in systems with endogenous context variables. We show that naive approaches such as learning different regime graphs on masked data, or pooling all data, can lead to uninformative results. We propose an adaptive constraint-based discovery algorithm and give a detailed discussion on the connection to structural causal models, including sufficiency assumptions, which allow to prove the soundness of our algorithm and to interpret the results causally. Numerical experiments demonstrate the performance of the proposed method over alternative baselines, but they also unveil current limitations of our method.
Causal Modeling in Multi-Context Systems: Distinguishing Multiple Context-Specific Causal Graphs which Account for Observational Support
Oct 27, 2024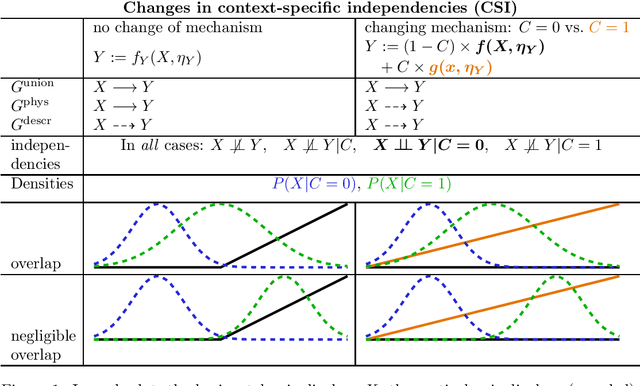
Causal structure learning with data from multiple contexts carries both opportunities and challenges. Opportunities arise from considering shared and context-specific causal graphs enabling to generalize and transfer causal knowledge across contexts. However, a challenge that is currently understudied in the literature is the impact of differing observational support between contexts on the identifiability of causal graphs. Here we study in detail recently introduced [6] causal graph objects that capture both causal mechanisms and data support, allowing for the analysis of a larger class of context-specific changes, characterizing distribution shifts more precisely. We thereby extend results on the identifiability of context-specific causal structures and propose a framework to model context-specific independence (CSI) within structural causal models (SCMs) in a refined way that allows to explore scenarios where these graph objects differ. We demonstrate how this framework can help explaining phenomena like anomalies or extreme events, where causal mechanisms change or appear to change under different conditions. Our results contribute to the theoretical foundations for understanding causal relations in multi-context systems, with implications for generalization, transfer learning, and anomaly detection. Future work may extend this approach to more complex data types, such as time-series.
Conditional Independence Testing with Heteroskedastic Data and Applications to Causal Discovery
Jun 20, 2023



Conditional independence (CI) testing is frequently used in data analysis and machine learning for various scientific fields and it forms the basis of constraint-based causal discovery. Oftentimes, CI testing relies on strong, rather unrealistic assumptions. One of these assumptions is homoskedasticity, in other words, a constant conditional variance is assumed. We frame heteroskedasticity in a structural causal model framework and present an adaptation of the partial correlation CI test that works well in the presence of heteroskedastic noise, given that expert knowledge about the heteroskedastic relationships is available. Further, we provide theoretical consistency results for the proposed CI test which carry over to causal discovery under certain assumptions. Numerical causal discovery experiments demonstrate that the adapted partial correlation CI test outperforms the standard test in the presence of heteroskedasticity and is on par for the homoskedastic case. Finally, we discuss the general challenges and limits as to how expert knowledge about heteroskedasticity can be accounted for in causal discovery.
Risk Assessment for Machine Learning Models
Nov 09, 2020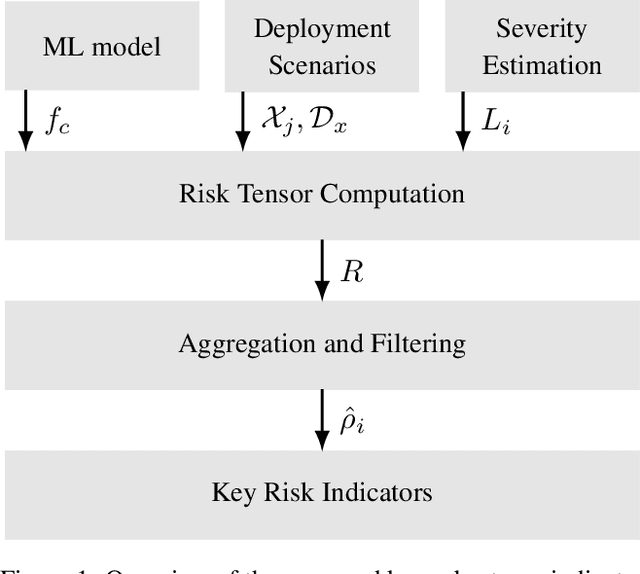
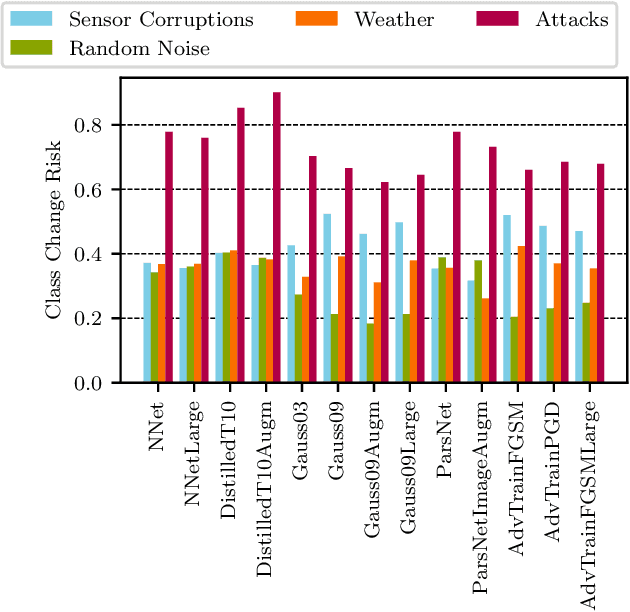
In this paper we propose a framework for assessing the risk associated with deploying a machine learning model in a specified environment. For that we carry over the risk definition from decision theory to machine learning. We develop and implement a method that allows to define deployment scenarios, test the machine learning model under the conditions specified in each scenario, and estimate the damage associated with the output of the machine learning model under test. Using the likelihood of each scenario together with the estimated damage we define \emph{key risk indicators} of a machine learning model. The definition of scenarios and weighting by their likelihood allows for standardized risk assessment in machine learning throughout multiple domains of application. In particular, in our framework, the robustness of a machine learning model to random input corruptions, distributional shifts caused by a changing environment, and adversarial perturbations can be assessed.
Understanding the Decision Boundary of Deep Neural Networks: An Empirical Study
Feb 05, 2020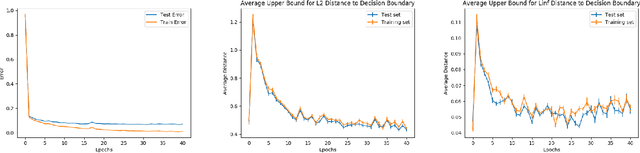
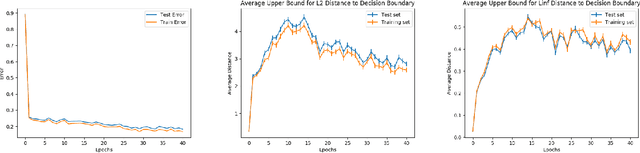
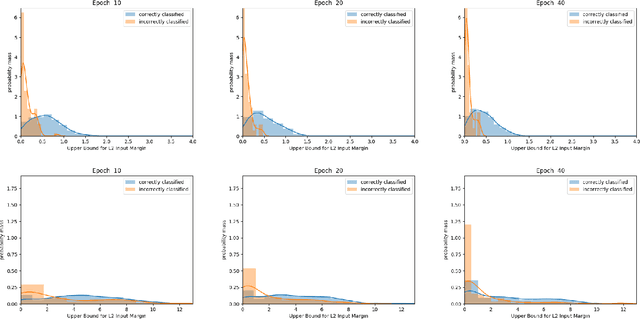
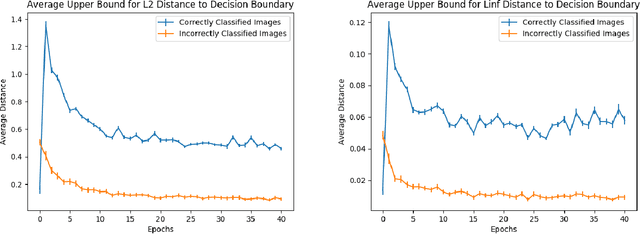
Despite achieving remarkable performance on many image classification tasks, state-of-the-art machine learning (ML) classifiers remain vulnerable to small input perturbations. Especially, the existence of adversarial examples raises concerns about the deployment of ML models in safety- and security-critical environments, like autonomous driving and disease detection. Over the last few years, numerous defense methods have been published with the goal of improving adversarial as well as corruption robustness. However, the proposed measures succeeded only to a very limited extent. This limited progress is partly due to the lack of understanding of the decision boundary and decision regions of deep neural networks. Therefore, we study the minimum distance of data points to the decision boundary and how this margin evolves over the training of a deep neural network. By conducting experiments on MNIST, FASHION-MNIST, and CIFAR-10, we observe that the decision boundary moves closer to natural images over training. This phenomenon even remains intact in the late epochs of training, where the classifier already obtains low training and test error rates. On the other hand, adversarial training appears to have the potential to prevent this undesired convergence of the decision boundary.
The Attack Generator: A Systematic Approach Towards Constructing Adversarial Attacks
Jun 17, 2019

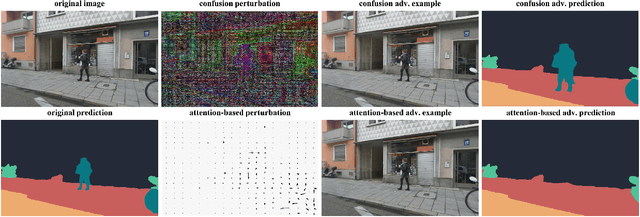
Most state-of-the-art machine learning (ML) classification systems are vulnerable to adversarial perturbations. As a consequence, adversarial robustness poses a significant challenge for the deployment of ML-based systems in safety- and security-critical environments like autonomous driving, disease detection or unmanned aerial vehicles. In the past years we have seen an impressive amount of publications presenting more and more new adversarial attacks. However, the attack research seems to be rather unstructured and new attacks often appear to be random selections from the unlimited set of possible adversarial attacks. With this publication, we present a structured analysis of the adversarial attack creation process. By detecting different building blocks of adversarial attacks, we outline the road to new sets of adversarial attacks. We call this the "attack generator". In the pursuit of this objective, we summarize and extend existing adversarial perturbation taxonomies. The resulting taxonomy is then linked to the application context of computer vision systems for autonomous vehicles, i.e. semantic segmentation and object detection. Finally, in order to prove the usefulness of the attack generator, we investigate existing semantic segmentation attacks with respect to the detected defining components of adversarial attacks.