 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Verification of Wasserstein Adversarial Robustness
Oct 13, 2021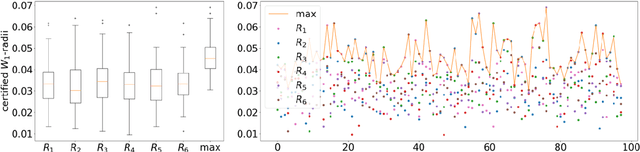


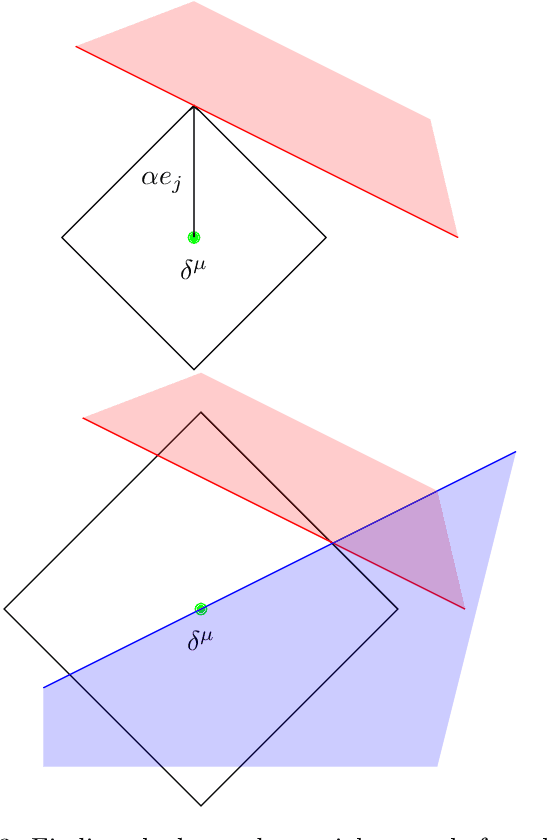
Machine learning image classifiers are susceptible to adversarial and corruption perturbations. Adding imperceptible noise to images can lead to severe misclassifications of the machine learning model. Using $L_p$-norms for measuring the size of the noise fails to capture human similarity perception, which is why optimal transport based distance measures like the Wasserstein metric are increasingly being used in the field of adversarial robustness. Verifying the robustness of classifiers using the Wasserstein metric can be achieved by proving the absence of adversarial examples (certification) or proving their presence (attack). In this work we present a framework based on the work by Levine and Feizi, which allows us to transfer existing certification methods for convex polytopes or $L_1$-balls to the Wasserstein threat model. The resulting certification can be complete or incomplete, depending on whether convex polytopes or $L_1$-balls were chosen. Additionally, we present a new Wasserstein adversarial attack that is projected gradient descent based and which has a significantly reduced computational burden compared to existing attack approaches.
Risk Assessment for Machine Learning Models
Nov 09, 2020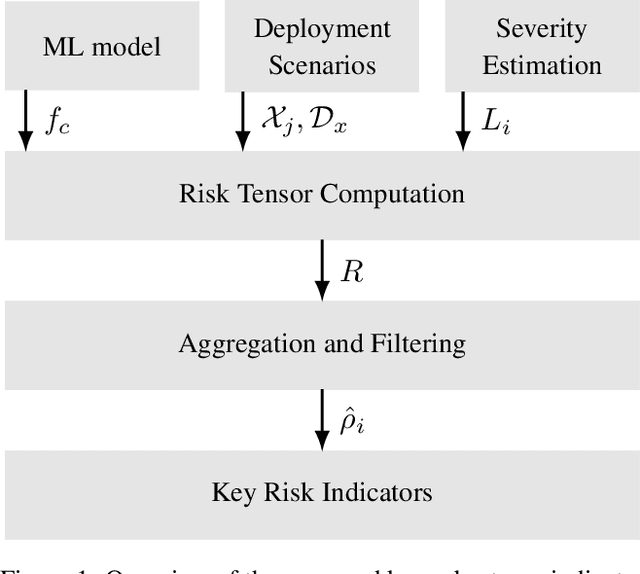
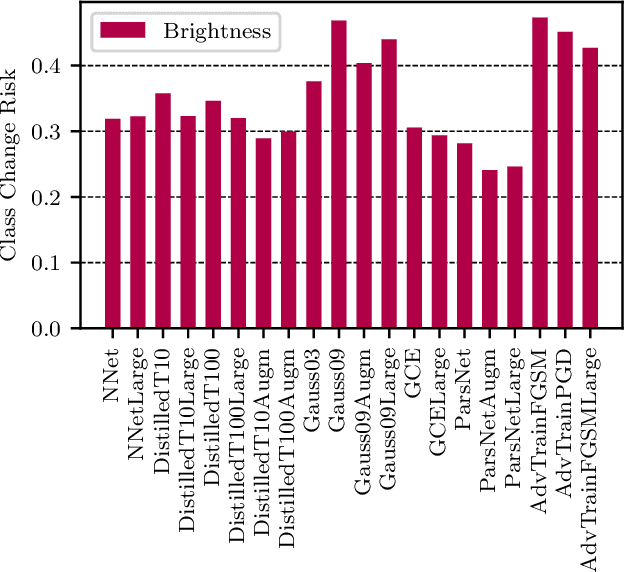
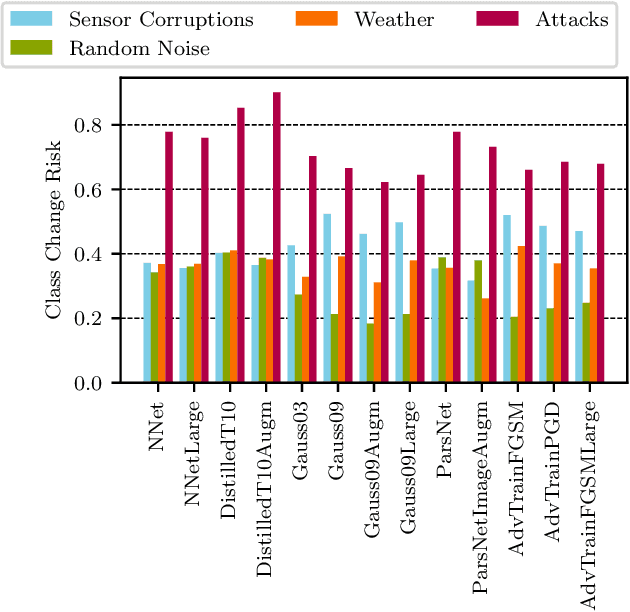
In this paper we propose a framework for assessing the risk associated with deploying a machine learning model in a specified environment. For that we carry over the risk definition from decision theory to machine learning. We develop and implement a method that allows to define deployment scenarios, test the machine learning model under the conditions specified in each scenario, and estimate the damage associated with the output of the machine learning model under test. Using the likelihood of each scenario together with the estimated damage we define \emph{key risk indicators} of a machine learning model. The definition of scenarios and weighting by their likelihood allows for standardized risk assessment in machine learning throughout multiple domains of application. In particular, in our framework, the robustness of a machine learning model to random input corruptions, distributional shifts caused by a changing environment, and adversarial perturbations can be assessed.
Understanding the Decision Boundary of Deep Neural Networks: An Empirical Study
Feb 05, 2020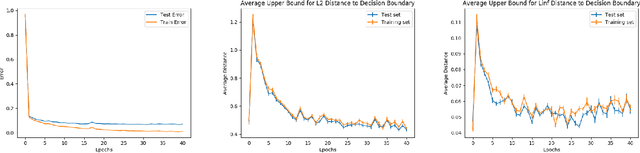
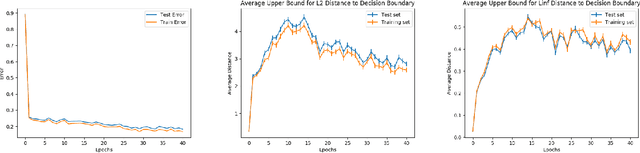
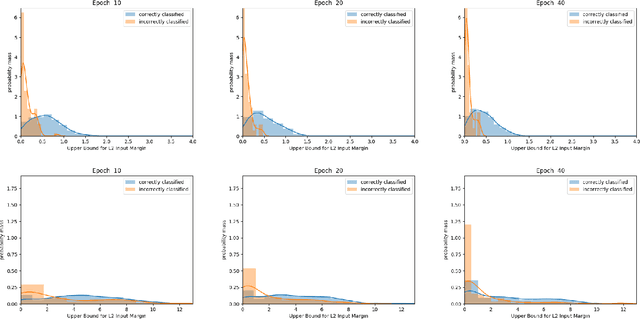
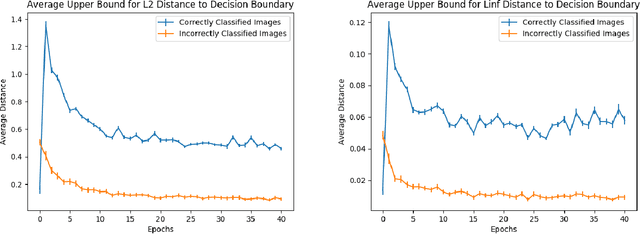
Despite achieving remarkable performance on many image classification tasks, state-of-the-art machine learning (ML) classifiers remain vulnerable to small input perturbations. Especially, the existence of adversarial examples raises concerns about the deployment of ML models in safety- and security-critical environments, like autonomous driving and disease detection. Over the last few years, numerous defense methods have been published with the goal of improving adversarial as well as corruption robustness. However, the proposed measures succeeded only to a very limited extent. This limited progress is partly due to the lack of understanding of the decision boundary and decision regions of deep neural networks. Therefore, we study the minimum distance of data points to the decision boundary and how this margin evolves over the training of a deep neural network. By conducting experiments on MNIST, FASHION-MNIST, and CIFAR-10, we observe that the decision boundary moves closer to natural images over training. This phenomenon even remains intact in the late epochs of training, where the classifier already obtains low training and test error rates. On the other hand, adversarial training appears to have the potential to prevent this undesired convergence of the decision boundary.
The Attack Generator: A Systematic Approach Towards Constructing Adversarial Attacks
Jun 17, 2019

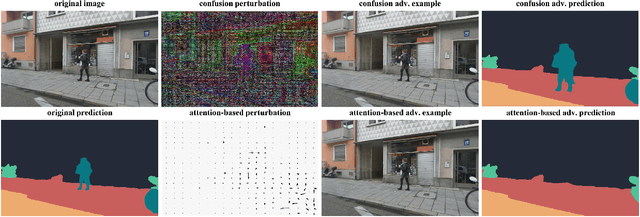
Most state-of-the-art machine learning (ML) classification systems are vulnerable to adversarial perturbations. As a consequence, adversarial robustness poses a significant challenge for the deployment of ML-based systems in safety- and security-critical environments like autonomous driving, disease detection or unmanned aerial vehicles. In the past years we have seen an impressive amount of publications presenting more and more new adversarial attacks. However, the attack research seems to be rather unstructured and new attacks often appear to be random selections from the unlimited set of possible adversarial attacks. With this publication, we present a structured analysis of the adversarial attack creation process. By detecting different building blocks of adversarial attacks, we outline the road to new sets of adversarial attacks. We call this the "attack generator". In the pursuit of this objective, we summarize and extend existing adversarial perturbation taxonomies. The resulting taxonomy is then linked to the application context of computer vision systems for autonomous vehicles, i.e. semantic segmentation and object detection. Finally, in order to prove the usefulness of the attack generator, we investigate existing semantic segmentation attacks with respect to the detected defining components of adversarial attacks.