 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL4AD: Vision-Language Models Improve Pixel-wise Anomaly Detection
Sep 25, 2024Semantic segmentation networks have achieved significant success under the assumption of independent and identically distributed data. However, these networks often struggle to detect anomalies from unknown semantic classes due to the limited set of visual concepts they are typically trained on. To address this issue, anomaly segmentation often involves fine-tuning on outlier samples, necessitating additional efforts for data collection, labeling, and model retraining. Seeking to avoid this cumbersome work, we take a different approach and propose to incorporate Vision-Language (VL) encoders into existing anomaly detectors to leverage the semantically broad VL pre-training for improved outlier awareness. Additionally, we propose a new scoring function that enables data- and training-free outlier supervision via textual prompts. The resulting VL4AD model, which includes max-logit prompt ensembling and a class-merging strategy, achieves competitive performance on widely used benchmark datasets, thereby demonstrating the potential of vision-language models for pixel-wise anomaly detection.
What should AI see? Using the Public's Opinion to Determine the Perception of an AI
Jun 09, 2022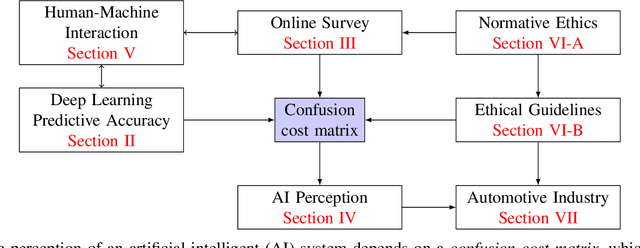

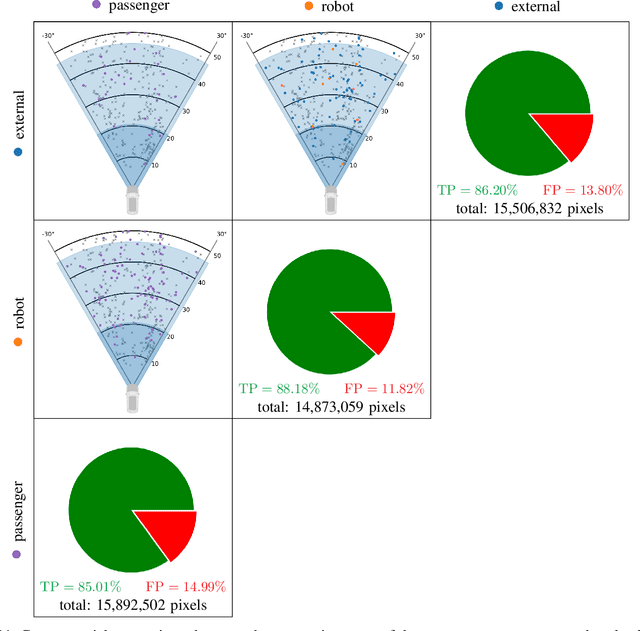
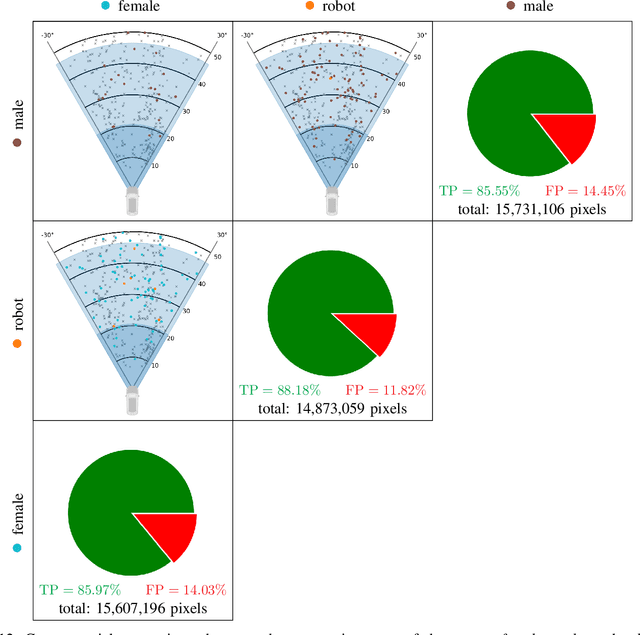
Deep neural networks (DNN) have made impressive progress in the interpretation of image data, so that it is conceivable and to some degree realistic to use them in safety critical applications like automated driving. From an ethical standpoint, the AI algorithm should take into account the vulnerability of objects or subjects on the street that ranges from "not at all", e.g. the road itself, to "high vulnerability" of pedestrians. One way to take this into account is to define the cost of confusion of one semantic category with another and use cost-based decision rules for the interpretation of probabilities, which are the output of DNNs. However, it is an open problem how to define the cost structure, who should be in charge to do that, and thereby define what AI-algorithms will actually "see". As one possible answer, we follow a participatory approach and set up an online survey to ask the public to define the cost structure. We present the survey design and the data acquired along with an evaluation that also distinguishes between perspective (car passenger vs. external traffic participant) and gender. Using simulation based $F$-tests, we find highly significant differences between the groups. These differences have consequences on the reliable detection of pedestrians in a safety critical distance to the self-driving car. We discuss the ethical problems that are related to this approach and also discuss the problems emerging from human-machine interaction through the survey from a psychological point of view. Finally, we include comments from industry leaders in the field of AI safety on the applicability of survey based elements in the design of AI functionalities in automated driving.
Tailored Uncertainty Estimation for Deep Learning Systems
Apr 29, 2022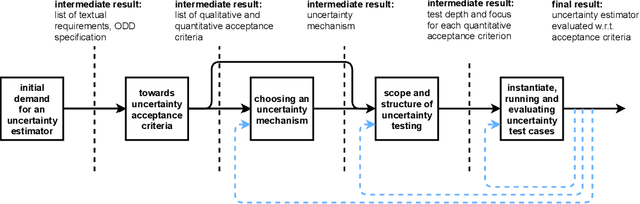

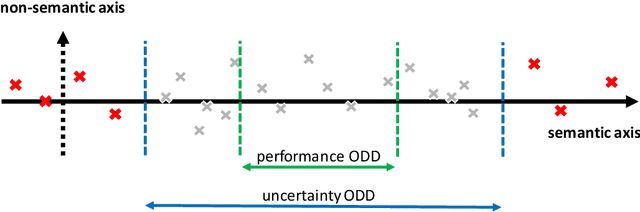
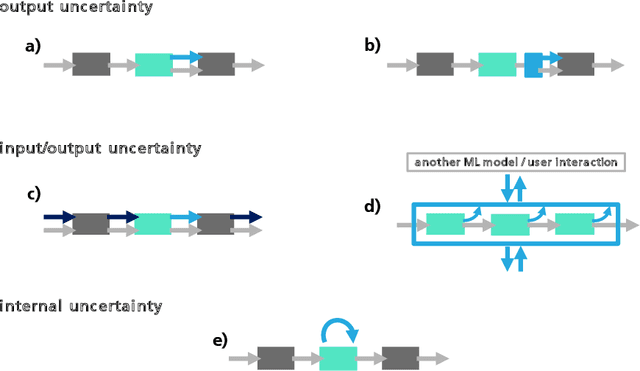
Uncertainty estimation bears the potential to make deep learning (DL) systems more reliable. Standard techniques for uncertainty estimation, however, come along with specific combinations of strengths and weaknesses, e.g., with respect to estimation quality, generalization abilities and computational complexity. To actually harness the potential of uncertainty quantification, estimators are required whose properties closely match the requirements of a given use case. In this work, we propose a framework that, firstly, structures and shapes these requirements, secondly, guides the selection of a suitable uncertainty estimation method and, thirdly, provides strategies to validate this choice and to uncover structural weaknesses. By contributing tailored uncertainty estimation in this sense, our framework helps to foster trustworthy DL systems. Moreover, it anticipates prospective machine learning regulations that require, e.g., in the EU, evidences for the technical appropriateness of machine learning systems. Our framework provides such evidences for system components modeling uncertainty.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021
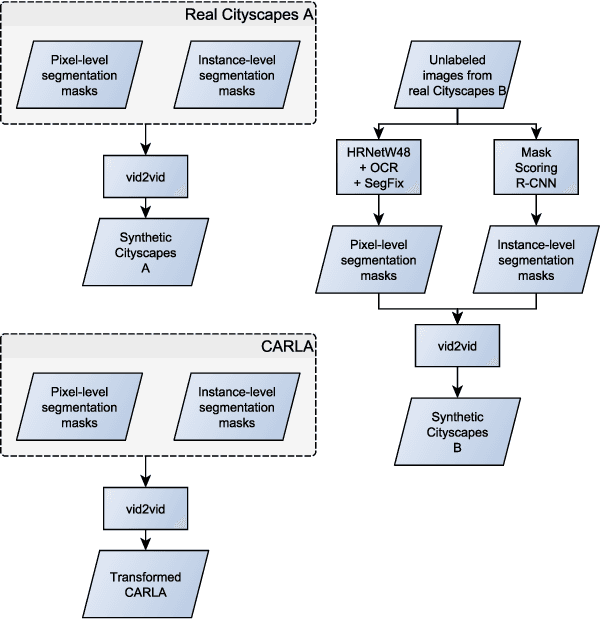


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
The Vulnerability of Semantic Segmentation Networks to Adversarial Attacks in Autonomous Driving: Enhancing Extensive Environment Sensing
Jan 13, 2021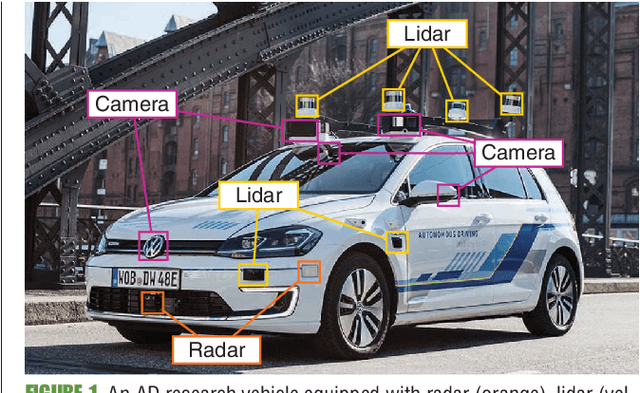

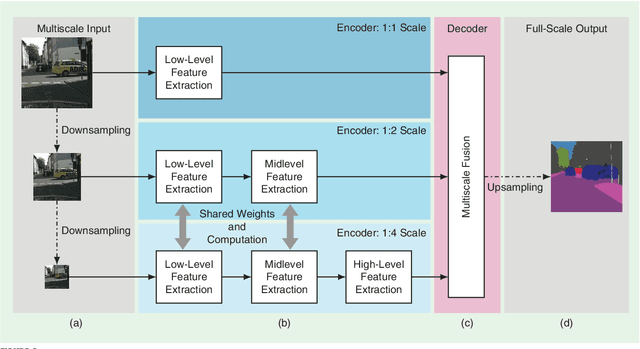
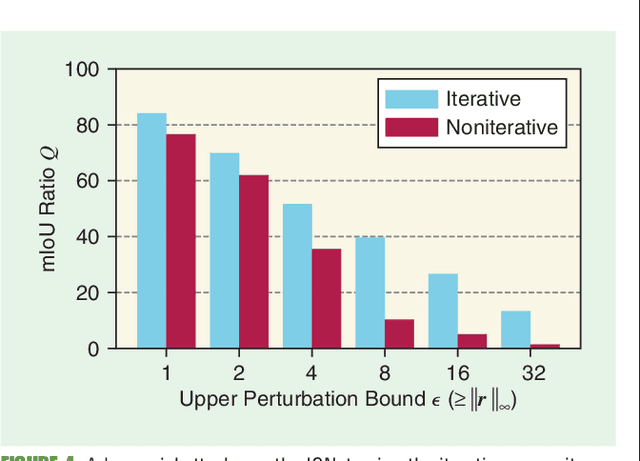
Enabling autonomous driving (AD) can be considered one of the biggest challenges in today's technology. AD is a complex task accomplished by several functionalities, with environment perception being one of its core functions. Environment perception is usually performed by combining the semantic information captured by several sensors, i.e., lidar or camera. The semantic information from the respective sensor can be extracted by using convolutional neural networks (CNNs) for dense prediction. In the past, CNNs constantly showed state-of-the-art performance on several vision-related tasks, such as semantic segmentation of traffic scenes using nothing but the red-green-blue (RGB) images provided by a camera. Although CNNs obtain state-of-the-art performance on clean images, almost imperceptible changes to the input, referred to as adversarial perturbations, may lead to fatal deception. The goal of this article is to illuminate the vulnerability aspects of CNNs used for semantic segmentation with respect to adversarial attacks, and share insights into some of the existing known adversarial defense strategies. We aim to clarify the advantages and disadvantages associated with applying CNNs for environment perception in AD to serve as a motivation for future research in this field.
Approaching Neural Network Uncertainty Realism
Jan 08, 2021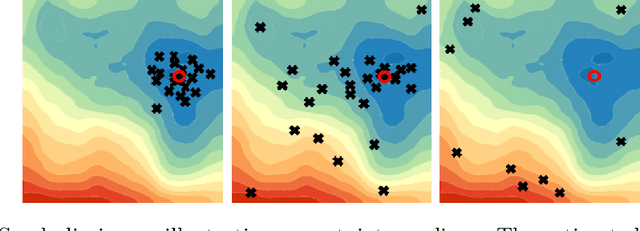
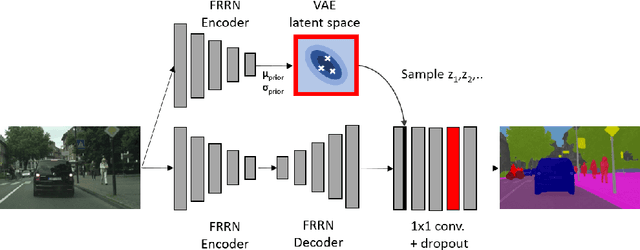
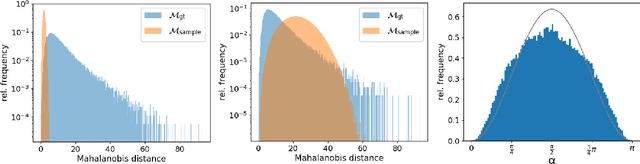
Statistical models are inherently uncertain. Quantifying or at least upper-bounding their uncertainties is vital for safety-critical systems such as autonomous vehicles. While standard neural networks do not report this information, several approaches exist to integrate uncertainty estimates into them. Assessing the quality of these uncertainty estimates is not straightforward, as no direct ground truth labels are available. Instead, implicit statistical assessments are required. For regression, we propose to evaluate uncertainty realism -- a strict quality criterion -- with a Mahalanobis distance-based statistical test. An empirical evaluation reveals the need for uncertainty measures that are appropriate to upper-bound heavy-tailed empirical errors. Alongside, we transfer the variational U-Net classification architecture to standard supervised image-to-image tasks. We adopt it to the automotive domain and show that it significantly improves uncertainty realism compared to a plain encoder-decoder model.
Improving Video Instance Segmentation by Light-weight Temporal Uncertainty Estimates
Dec 14, 2020

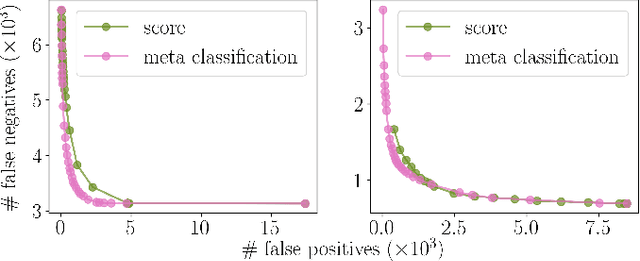

Instance segmentation with neural networks is an essential task in environment perception. However, the networks can predict false positive instances with high confidence values and true positives with low ones. Hence, it is important to accurately model the uncertainties of neural networks to prevent safety issues and foster interpretability. In applications such as automated driving the detection of road users like vehicles and pedestrians is of highest interest. We present a temporal approach to detect false positives and investigate uncertainties of instance segmentation networks. Since image sequences are available for online applications, we track instances over multiple frames and create temporal instance-wise aggregated metrics of uncertainty. The prediction quality is estimated by predicting the intersection over union as performance measure. Furthermore, we show how to use uncertainty information to replace the traditional score value from object detection and improve the overall performance of instance segmentation networks.
From a Fourier-Domain Perspective on Adversarial Examples to a Wiener Filter Defense for Semantic Segmentation
Dec 02, 2020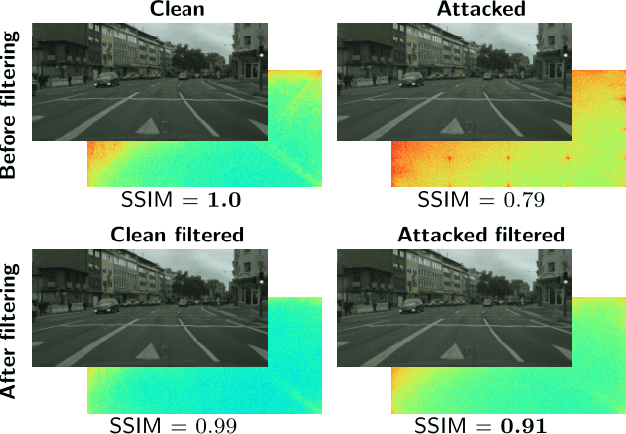
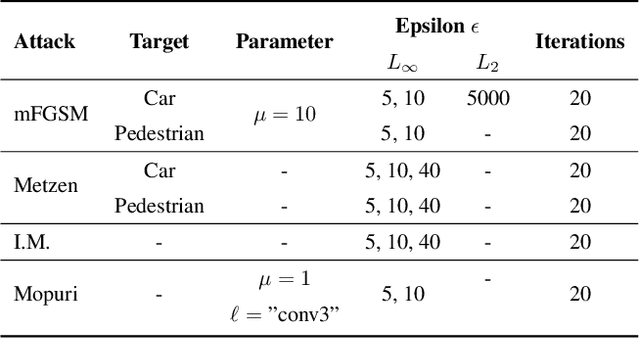
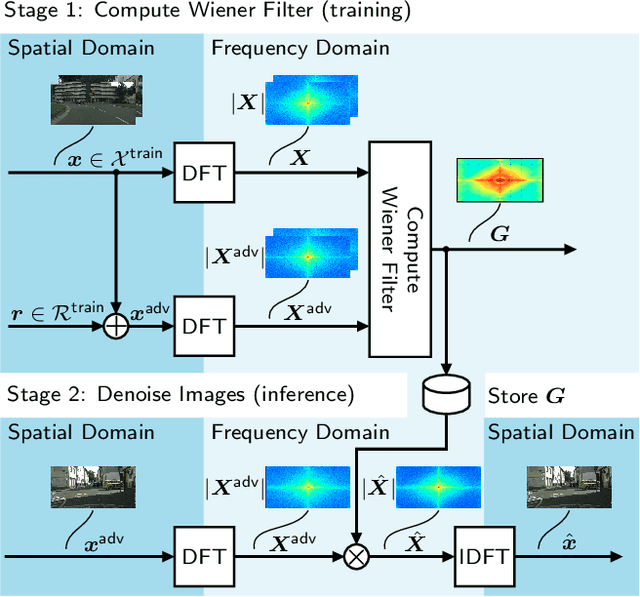
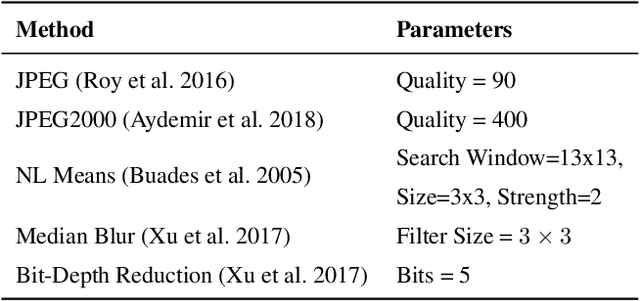
Despite recent advancements, deep neural networks are not robust against adversarial perturbations. Many of the proposed adversarial defense approaches use computationally expensive training mechanisms that do not scale to complex real-world tasks such as semantic segmentation, and offer only marginal improvements. In addition, fundamental questions on the nature of adversarial perturbations and their relation to the network architecture are largely understudied. In this work, we study the adversarial problem from a frequency domain perspective. More specifically, we analyze discrete Fourier transform (DFT) spectra of several adversarial images and report two major findings: First, there exists a strong connection between a model architecture and the nature of adversarial perturbations that can be observed and addressed in the frequency domain. Second, the observed frequency patterns are largely image- and attack-type independent, which is important for the practical impact of any defense making use of such patterns. Motivated by these findings, we additionally propose an adversarial defense method based on the well-known Wiener filters that captures and suppresses adversarial frequencies in a data-driven manner. Our proposed method not only generalizes across unseen attacks but also beats five existing state-of-the-art methods across two models in a variety of attack settings.
A Self-Supervised Feature Map Augmentation (FMA) Loss and Combined Augmentations Finetuning to Efficiently Improve the Robustness of CNNs
Dec 02, 2020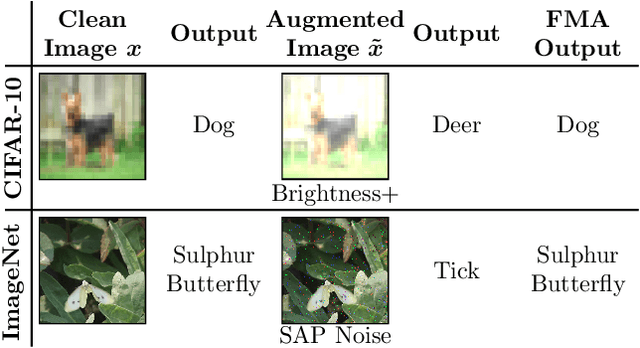
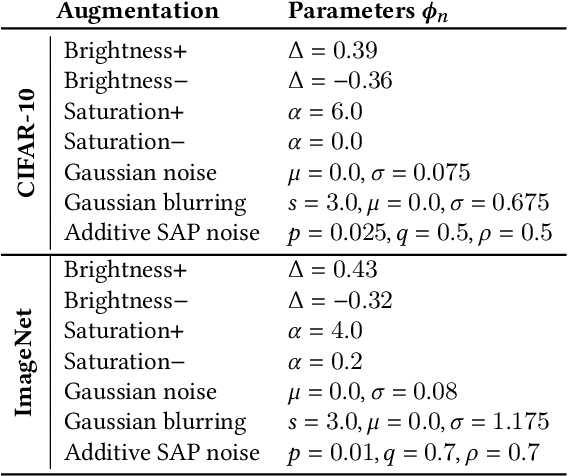
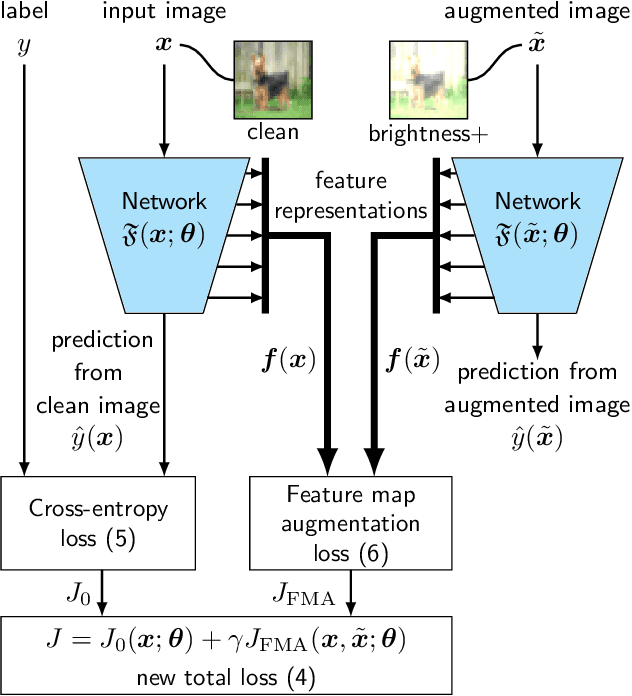
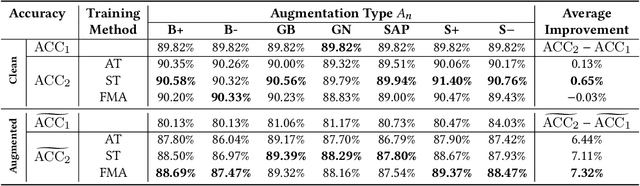
Deep neural networks are often not robust to semantically-irrelevant changes in the input. In this work we address the issue of robustness of state-of-the-art deep convolutional neural networks (CNNs) against commonly occurring distortions in the input such as photometric changes, or the addition of blur and noise. These changes in the input are often accounted for during training in the form of data augmentation. We have two major contributions: First, we propose a new regularization loss called feature-map augmentation (FMA) loss which can be used during finetuning to make a model robust to several distortions in the input. Second, we propose a new combined augmentations (CA) finetuning strategy, that results in a single model that is robust to several augmentation types at the same time in a data-efficient manner. We use the CA strategy to improve an existing state-of-the-art method called stability training (ST). Using CA, on an image classification task with distorted images, we achieve an accuracy improvement of on average 8.94% with FMA and 8.86% with ST absolute on CIFAR-10 and 8.04% with FMA and 8.27% with ST absolute on ImageNet, compared to 1.98% and 2.12%, respectively, with the well known data augmentation method, while keeping the clean baseline performance.
Risk Assessment for Machine Learning Models
Nov 09, 2020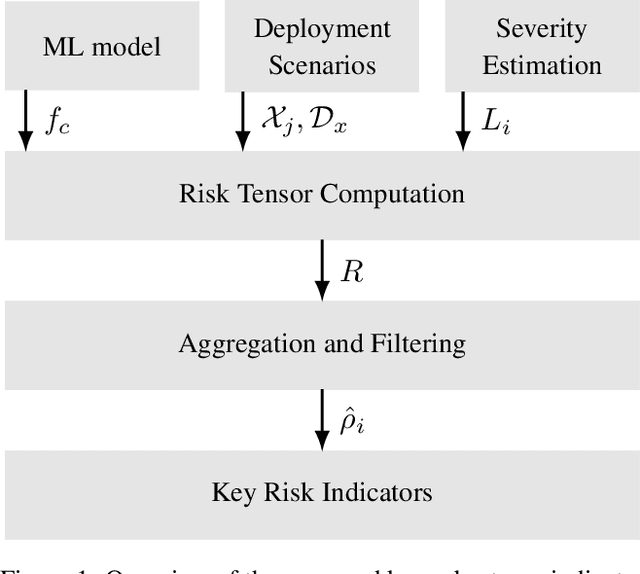
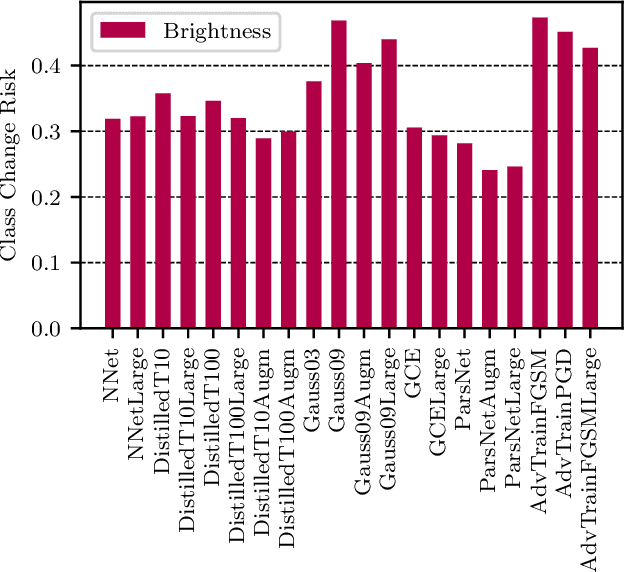
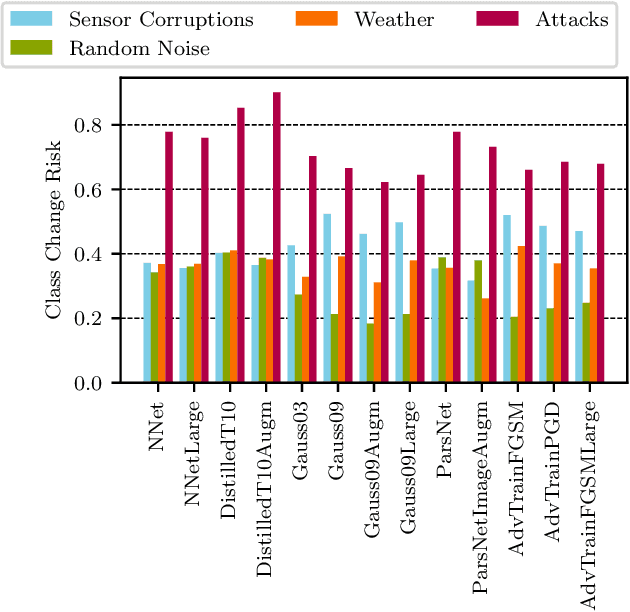
In this paper we propose a framework for assessing the risk associated with deploying a machine learning model in a specified environment. For that we carry over the risk definition from decision theory to machine learning. We develop and implement a method that allows to define deployment scenarios, test the machine learning model under the conditions specified in each scenario, and estimate the damage associated with the output of the machine learning model under test. Using the likelihood of each scenario together with the estimated damage we define \emph{key risk indicators} of a machine learning model. The definition of scenarios and weighting by their likelihood allows for standardized risk assessment in machine learning throughout multiple domains of application. In particular, in our framework, the robustness of a machine learning model to random input corruptions, distributional shifts caused by a changing environment, and adversarial perturbations can be assessed.