 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Data Bias Detection and Mitigation -- An Extensible Pipeline with Experimental Evaluation
Dec 12, 2025Textual data used to train large language models (LLMs) exhibits multifaceted bias manifestations encompassing harmful language and skewed demographic distributions. Regulations such as the European AI Act require identifying and mitigating biases against protected groups in data, with the ultimate goal of preventing unfair model outputs. However, practical guidance and operationalization are lacking. We propose a comprehensive data bias detection and mitigation pipeline comprising four components that address two data bias types, namely representation bias and (explicit) stereotypes for a configurable sensitive attribute. First, we leverage LLM-generated word lists created based on quality criteria to detect relevant group labels. Second, representation bias is quantified using the Demographic Representation Score. Third, we detect and mitigate stereotypes using sociolinguistically informed filtering. Finally, we compensate representation bias through Grammar- and Context-Aware Counterfactual Data Augmentation. We conduct a two-fold evaluation using the examples of gender, religion and age. First, the effectiveness of each individual component on data debiasing is evaluated through human validation and baseline comparison. The findings demonstrate that we successfully reduce representation bias and (explicit) stereotypes in a text dataset. Second, the effect of data debiasing on model bias reduction is evaluated by bias benchmarking of several models (0.6B-8B parameters), fine-tuned on the debiased text dataset. This evaluation reveals that LLMs fine-tuned on debiased data do not consistently show improved performance on bias benchmarks, exposing critical gaps in current evaluation methodologies and highlighting the need for targeted data manipulation to address manifested model bias.
Detecting Systematic Weaknesses in Vision Models along Predefined Human-Understandable Dimensions
Feb 17, 2025Studying systematic weaknesses of DNNs has gained prominence in the last few years with the rising focus on building safe AI systems. Slice discovery methods (SDMs) are prominent algorithmic approaches for finding such systematic weaknesses. They identify top-k semantically coherent slices/subsets of data where a DNN-under-test has low performance. For being directly useful, e.g., as evidences in a safety argumentation, slices should be aligned with human-understandable (safety-relevant) dimensions, which, for example, are defined by safety and domain experts as parts of the operational design domain (ODD). While straightforward for structured data, the lack of semantic metadata makes these investigations challenging for unstructured data. Therefore, we propose a complete workflow which combines contemporary foundation models with algorithms for combinatorial search that consider structured data and DNN errors for finding systematic weaknesses in images. In contrast to existing approaches, ours identifies weak slices that are in line with predefined human-understandable dimensions. As the workflow includes foundation models, its intermediate and final results may not always be exact. Therefore, we build into our workflow an approach to address the impact of noisy metadata. We evaluate our approach w.r.t. its quality on four popular computer vision datasets, including autonomous driving datasets like Cityscapes, BDD100k, and RailSem19, while using multiple state-of-the-art models as DNNs-under-test.
Reinforcement Learning for Efficient Returns Management
Jan 24, 2025



In retail warehouses, returned products are typically placed in an intermediate storage until a decision regarding further shipment to stores is made. The longer products are held in storage, the higher the inefficiency and costs of the returns management process, since enough storage area has to be provided and maintained while the products are not placed for sale. To reduce the average product storage time, we consider an alternative solution where reallocation decisions for products can be made instantly upon their arrival in the warehouse allowing only a limited number of products to still be stored simultaneously. We transfer the problem to an online multiple knapsack problem and propose a novel reinforcement learning approach to pack the items (products) into the knapsacks (stores) such that the overall value (expected revenue) is maximized. Empirical evaluations on simulated data demonstrate that, compared to the usual offline decision procedure, our approach comes with a performance gap of only 3% while significantly reducing the average storage time of a product by 96%.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
Robustness in Fatigue Strength Estimation
Dec 02, 2022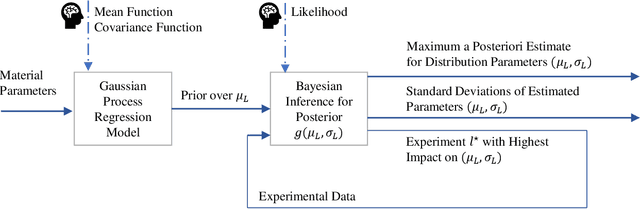

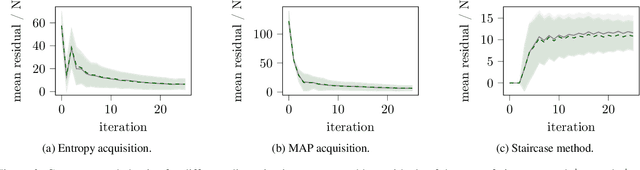
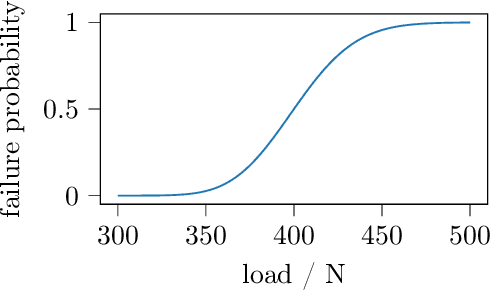
Fatigue strength estimation is a costly manual material characterization process in which state-of-the-art approaches follow a standardized experiment and analysis procedure. In this paper, we examine a modular, Machine Learning-based approach for fatigue strength estimation that is likely to reduce the number of experiments and, thus, the overall experimental costs. Despite its high potential, deployment of a new approach in a real-life lab requires more than the theoretical definition and simulation. Therefore, we study the robustness of the approach against misspecification of the prior and discretization of the specified loads. We identify its applicability and its advantageous behavior over the state-of-the-art methods, potentially reducing the number of costly experiments.
Multi-Agent Neural Rewriter for Vehicle Routing with Limited Disclosure of Costs
Jun 13, 2022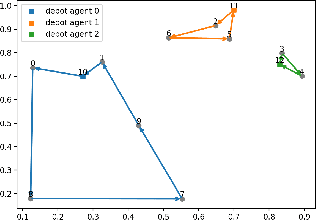

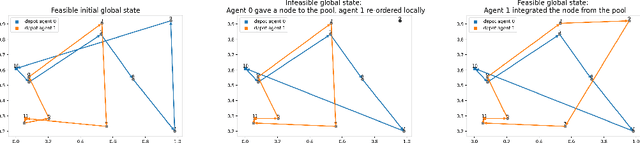

We interpret solving the multi-vehicle routing problem as a team Markov game with partially observable costs. For a given set of customers to serve, the playing agents (vehicles) have the common goal to determine the team-optimal agent routes with minimal total cost. Each agent thereby observes only its own cost. Our multi-agent reinforcement learning approach, the so-called multi-agent Neural Rewriter, builds on the single-agent Neural Rewriter to solve the problem by iteratively rewriting solutions. Parallel agent action execution and partial observability require new rewriting rules for the game. We propose the introduction of a so-called pool in the system which serves as a collection point for unvisited nodes. It enables agents to act simultaneously and exchange nodes in a conflict-free manner. We realize limited disclosure of agent-specific costs by only sharing them during learning. During inference, each agents acts decentrally, solely based on its own cost. First empirical results on small problem sizes demonstrate that we reach a performance close to the employed OR-Tools benchmark which operates in the perfect cost information setting.
Tailored Uncertainty Estimation for Deep Learning Systems
Apr 29, 2022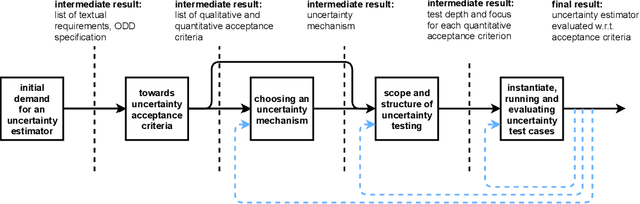

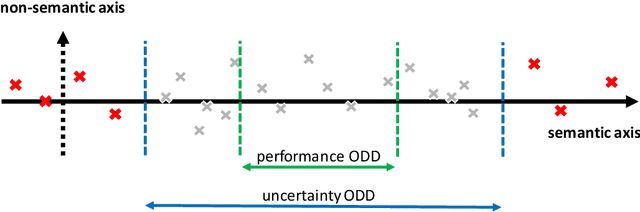
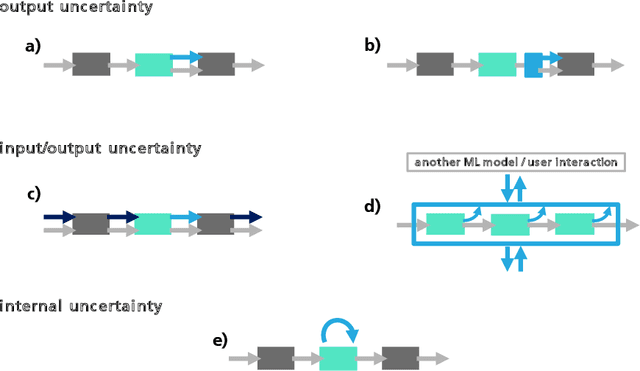
Uncertainty estimation bears the potential to make deep learning (DL) systems more reliable. Standard techniques for uncertainty estimation, however, come along with specific combinations of strengths and weaknesses, e.g., with respect to estimation quality, generalization abilities and computational complexity. To actually harness the potential of uncertainty quantification, estimators are required whose properties closely match the requirements of a given use case. In this work, we propose a framework that, firstly, structures and shapes these requirements, secondly, guides the selection of a suitable uncertainty estimation method and, thirdly, provides strategies to validate this choice and to uncover structural weaknesses. By contributing tailored uncertainty estimation in this sense, our framework helps to foster trustworthy DL systems. Moreover, it anticipates prospective machine learning regulations that require, e.g., in the EU, evidences for the technical appropriateness of machine learning systems. Our framework provides such evidences for system components modeling uncertainty.
Graph Filtration Kernels
Oct 22, 2021
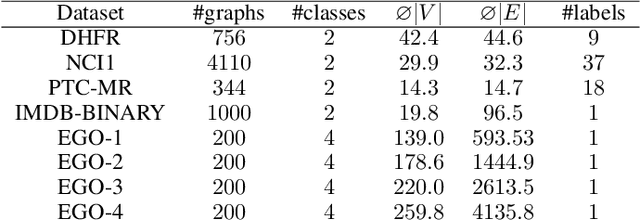
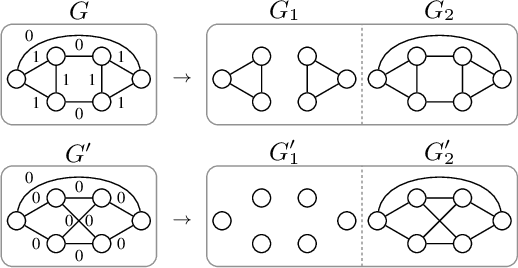
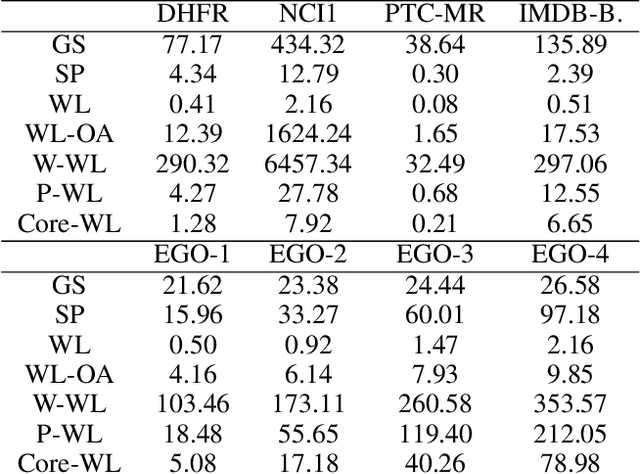
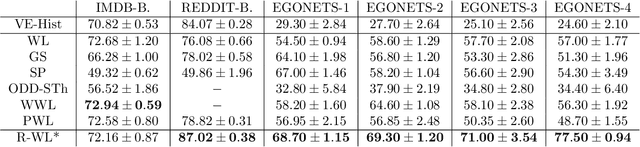
The majority of popular graph kernels is based on the concept of Haussler's $\mathcal{R}$-convolution kernel and defines graph similarities in terms of mutual substructures. In this work, we enrich these similarity measures by considering graph filtrations: Using meaningful orders on the set of edges, which allow to construct a sequence of nested graphs, we can consider a graph at multiple granularities. For one thing, this provides access to features on different levels of resolution. Furthermore, rather than to simply compare frequencies of features in graphs, it allows for their comparison in terms of when and for how long they exist in the sequences. In this work, we propose a family of graph kernels that incorporate these existence intervals of features. While our approach can be applied to arbitrary graph features, we particularly highlight Weisfeiler-Lehman vertex labels, leading to efficient kernels. We show that using Weisfeiler-Lehman labels over certain filtrations strictly increases the expressive power over the ordinary Weisfeiler-Lehman procedure in terms of deciding graph isomorphism. In fact, this result directly yields more powerful graph kernels based on such features and has implications to graph neural networks due to their close relationship to the Weisfeiler-Lehman method. We empirically validate the expressive power of our graph kernels and show significant improvements over state-of-the-art graph kernels in terms of predictive performance on various real-world benchmark datasets.
Learning Weakly Convex Sets in Metric Spaces
May 10, 2021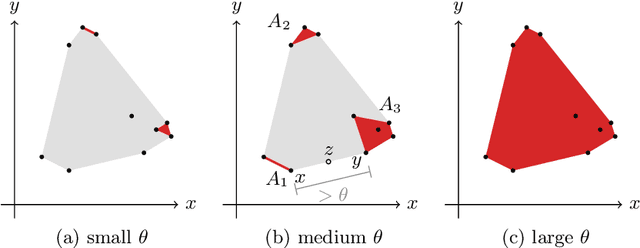

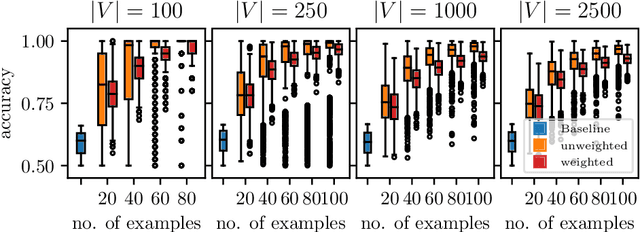
We introduce the notion of weak convexity in metric spaces, a generalization of ordinary convexity commonly used in machine learning. It is shown that weakly convex sets can be characterized by a closure operator and have a unique decomposition into a set of pairwise disjoint connected blocks. We give two generic efficient algorithms, an extensional and an intensional one for learning weakly convex concepts and study their formal properties. Our experimental results concerning vertex classification clearly demonstrate the excellent predictive performance of the extensional algorithm. Two non-trivial applications of the intensional algorithm to polynomial PAC-learnability are presented. The first one deals with learning $k$-convex Boolean functions, which are already known to be efficiently PAC-learnable. It is shown how to derive this positive result in a fairly easy way by the generic intensional algorithm. The second one is concerned with the Euclidean space equipped with the Manhattan distance. For this metric space, weakly convex sets are a union of pairwise disjoint axis-aligned hyperrectangles. We show that a weakly convex set that is consistent with a set of examples and contains a minimum number of hyperrectangles can be found in polynomial time. In contrast, this problem is known to be NP-complete if the hyperrectangles may be overlapping.
A Generalized Weisfeiler-Lehman Graph Kernel
Jan 20, 2021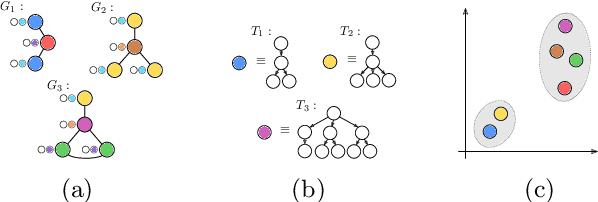
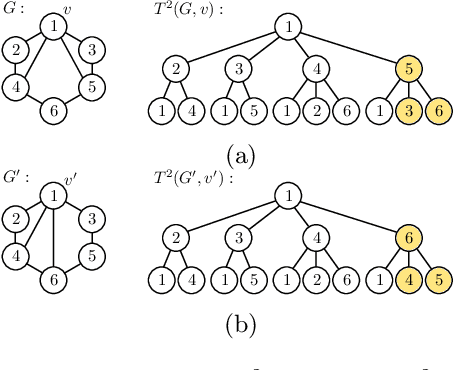
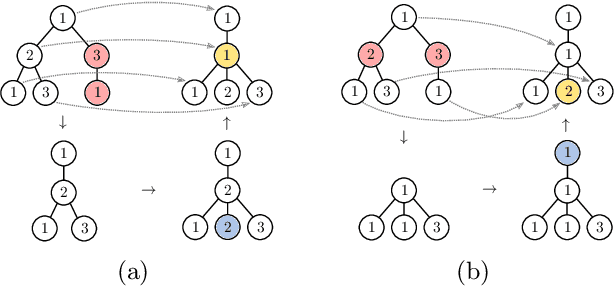
The Weisfeiler-Lehman graph kernels are among the most prevalent graph kernels due to their remarkable time complexity and predictive performance. Their key concept is based on an implicit comparison of neighborhood representing trees with respect to equality (i.e., isomorphism). This binary valued comparison is, however, arguably too rigid for defining suitable similarity measures over graphs. To overcome this limitation, we propose a generalization of Weisfeiler-Lehman graph kernels which takes into account the similarity between trees rather than equality. We achieve this using a specifically fitted variation of the well-known tree edit distance which can efficiently be calculated. We empirically show that our approach significantly outperforms state-of-the-art methods in terms of predictive performance on datasets containing structurally more complex graphs beyond the typically considered molecular graphs.