 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Efficient Returns Management
Jan 24, 2025



In retail warehouses, returned products are typically placed in an intermediate storage until a decision regarding further shipment to stores is made. The longer products are held in storage, the higher the inefficiency and costs of the returns management process, since enough storage area has to be provided and maintained while the products are not placed for sale. To reduce the average product storage time, we consider an alternative solution where reallocation decisions for products can be made instantly upon their arrival in the warehouse allowing only a limited number of products to still be stored simultaneously. We transfer the problem to an online multiple knapsack problem and propose a novel reinforcement learning approach to pack the items (products) into the knapsacks (stores) such that the overall value (expected revenue) is maximized. Empirical evaluations on simulated data demonstrate that, compared to the usual offline decision procedure, our approach comes with a performance gap of only 3% while significantly reducing the average storage time of a product by 96%.
Multi-Agent Neural Rewriter for Vehicle Routing with Limited Disclosure of Costs
Jun 13, 2022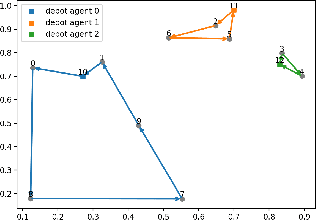

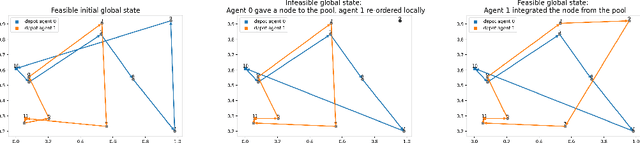

We interpret solving the multi-vehicle routing problem as a team Markov game with partially observable costs. For a given set of customers to serve, the playing agents (vehicles) have the common goal to determine the team-optimal agent routes with minimal total cost. Each agent thereby observes only its own cost. Our multi-agent reinforcement learning approach, the so-called multi-agent Neural Rewriter, builds on the single-agent Neural Rewriter to solve the problem by iteratively rewriting solutions. Parallel agent action execution and partial observability require new rewriting rules for the game. We propose the introduction of a so-called pool in the system which serves as a collection point for unvisited nodes. It enables agents to act simultaneously and exchange nodes in a conflict-free manner. We realize limited disclosure of agent-specific costs by only sharing them during learning. During inference, each agents acts decentrally, solely based on its own cost. First empirical results on small problem sizes demonstrate that we reach a performance close to the employed OR-Tools benchmark which operates in the perfect cost information setting.
Introducing Noise in Decentralized Training of Neural Networks
Sep 27, 2018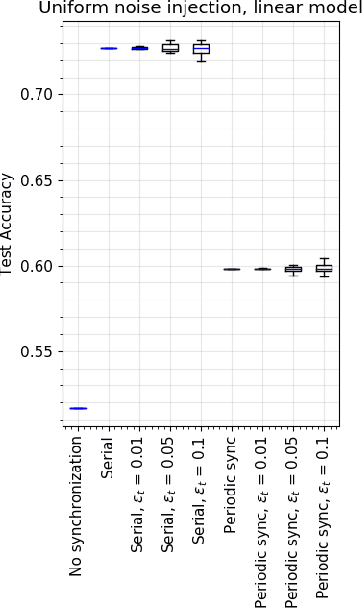
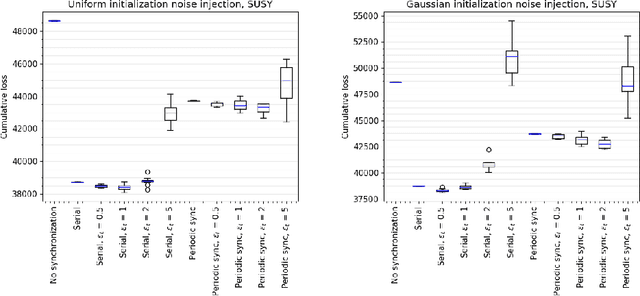
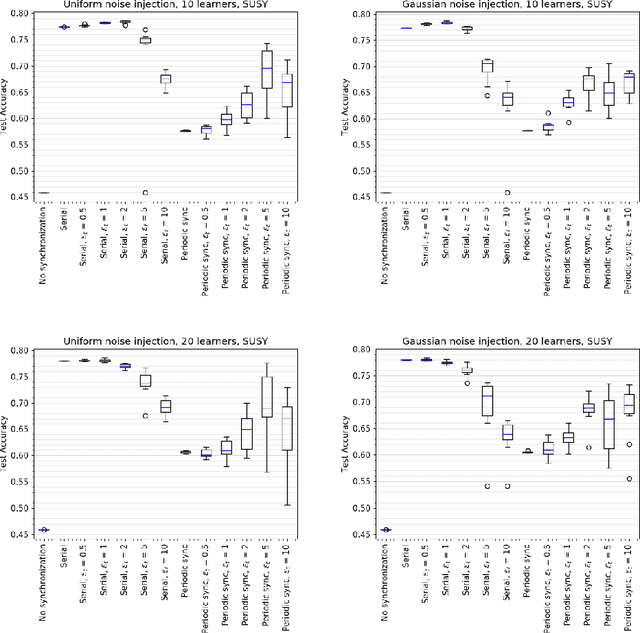
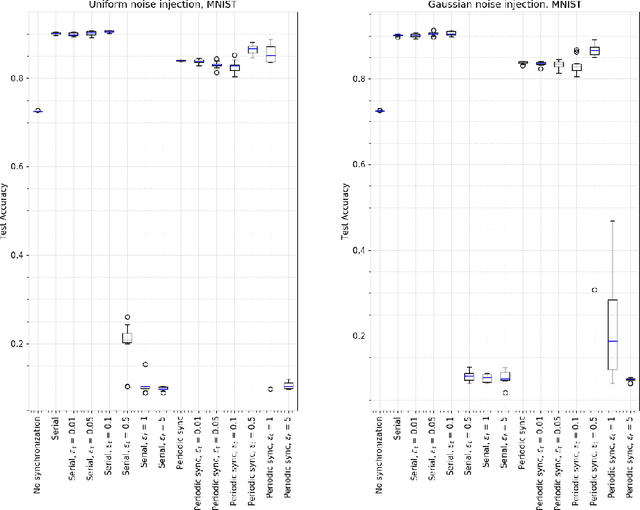
It has been shown that injecting noise into the neural network weights during the training process leads to a better generalization of the resulting model. Noise injection in the distributed setup is a straightforward technique and it represents a promising approach to improve the locally trained models. We investigate the effects of noise injection into the neural networks during a decentralized training process. We show both theoretically and empirically that noise injection has no positive effect in expectation on linear models, though. However for non-linear neural networks we empirically show that noise injection substantially improves model quality helping to reach a generalization ability of a local model close to the serial baseline.
* 13 pages