 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Efficient Returns Management
Jan 24, 2025



In retail warehouses, returned products are typically placed in an intermediate storage until a decision regarding further shipment to stores is made. The longer products are held in storage, the higher the inefficiency and costs of the returns management process, since enough storage area has to be provided and maintained while the products are not placed for sale. To reduce the average product storage time, we consider an alternative solution where reallocation decisions for products can be made instantly upon their arrival in the warehouse allowing only a limited number of products to still be stored simultaneously. We transfer the problem to an online multiple knapsack problem and propose a novel reinforcement learning approach to pack the items (products) into the knapsacks (stores) such that the overall value (expected revenue) is maximized. Empirical evaluations on simulated data demonstrate that, compared to the usual offline decision procedure, our approach comes with a performance gap of only 3% while significantly reducing the average storage time of a product by 96%.
Multi-Agent Neural Rewriter for Vehicle Routing with Limited Disclosure of Costs
Jun 13, 2022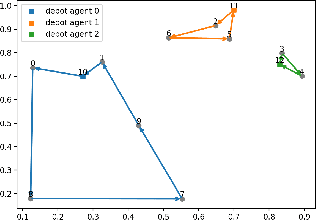

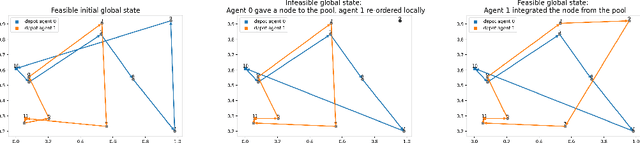

We interpret solving the multi-vehicle routing problem as a team Markov game with partially observable costs. For a given set of customers to serve, the playing agents (vehicles) have the common goal to determine the team-optimal agent routes with minimal total cost. Each agent thereby observes only its own cost. Our multi-agent reinforcement learning approach, the so-called multi-agent Neural Rewriter, builds on the single-agent Neural Rewriter to solve the problem by iteratively rewriting solutions. Parallel agent action execution and partial observability require new rewriting rules for the game. We propose the introduction of a so-called pool in the system which serves as a collection point for unvisited nodes. It enables agents to act simultaneously and exchange nodes in a conflict-free manner. We realize limited disclosure of agent-specific costs by only sharing them during learning. During inference, each agents acts decentrally, solely based on its own cost. First empirical results on small problem sizes demonstrate that we reach a performance close to the employed OR-Tools benchmark which operates in the perfect cost information setting.
Tailored Uncertainty Estimation for Deep Learning Systems
Apr 29, 2022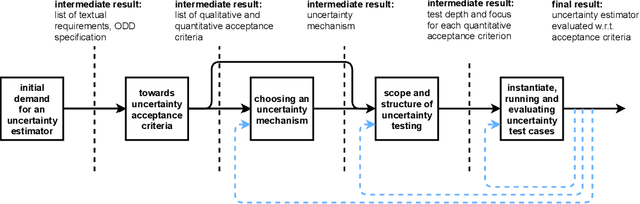

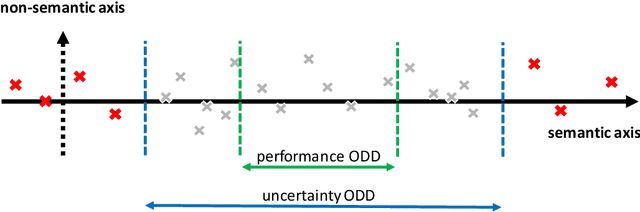
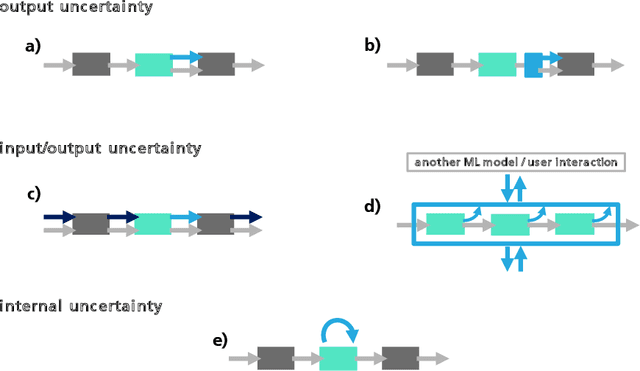
Uncertainty estimation bears the potential to make deep learning (DL) systems more reliable. Standard techniques for uncertainty estimation, however, come along with specific combinations of strengths and weaknesses, e.g., with respect to estimation quality, generalization abilities and computational complexity. To actually harness the potential of uncertainty quantification, estimators are required whose properties closely match the requirements of a given use case. In this work, we propose a framework that, firstly, structures and shapes these requirements, secondly, guides the selection of a suitable uncertainty estimation method and, thirdly, provides strategies to validate this choice and to uncover structural weaknesses. By contributing tailored uncertainty estimation in this sense, our framework helps to foster trustworthy DL systems. Moreover, it anticipates prospective machine learning regulations that require, e.g., in the EU, evidences for the technical appropriateness of machine learning systems. Our framework provides such evidences for system components modeling uncertainty.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021
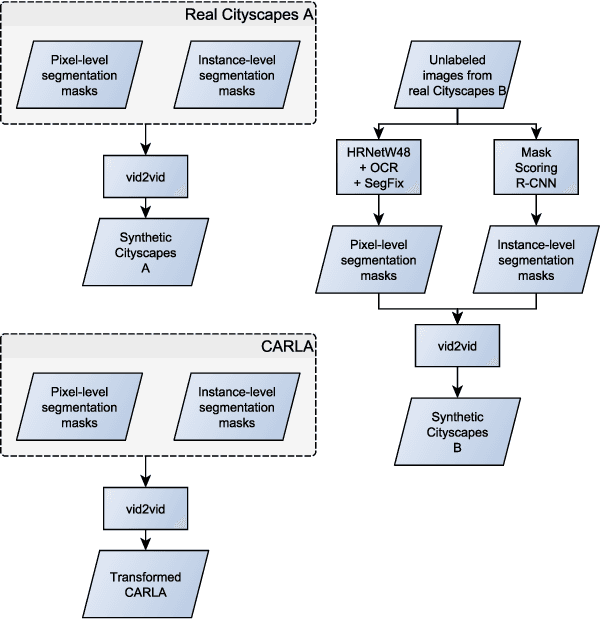


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Plants Don't Walk on the Street: Common-Sense Reasoning for Reliable Semantic Segmentation
Apr 19, 2021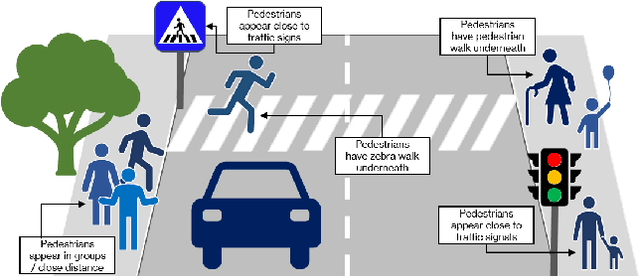

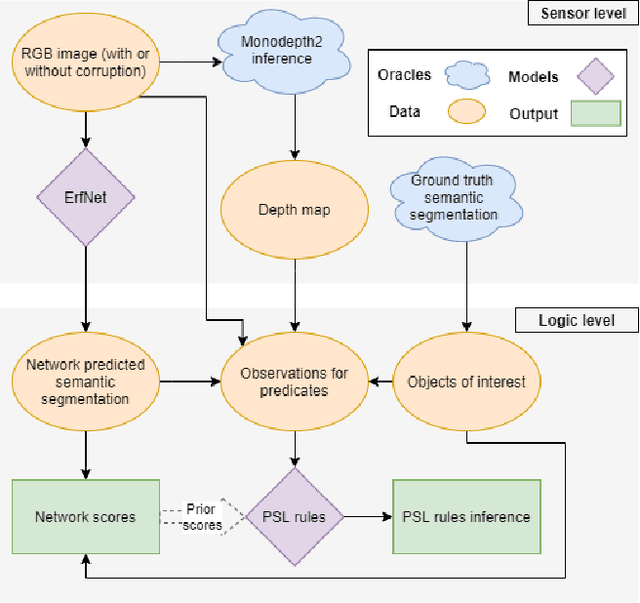

Data-driven sensor interpretation in autonomous driving can lead to highly implausible predictions as can most of the time be verified with common-sense knowledge. However, learning common knowledge only from data is hard and approaches for knowledge integration are an active research area. We propose to use a partly human-designed, partly learned set of rules to describe relations between objects of a traffic scene on a high level of abstraction. In doing so, we improve and robustify existing deep neural networks consuming low-level sensor information. We present an initial study adapting the well-established Probabilistic Soft Logic (PSL) framework to validate and improve on the problem of semantic segmentation. We describe in detail how we integrate common knowledge into the segmentation pipeline using PSL and verify our approach in a set of experiments demonstrating the increase in robustness against several severe image distortions applied to the A2D2 autonomous driving data set.
Street-Map Based Validation of Semantic Segmentation in Autonomous Driving
Apr 15, 2021
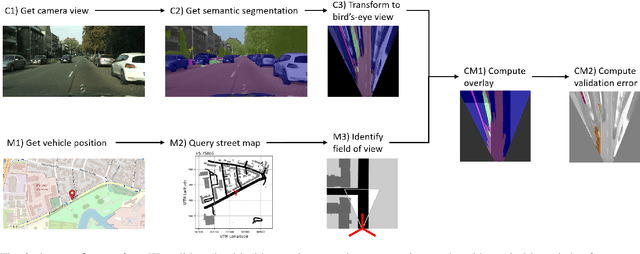
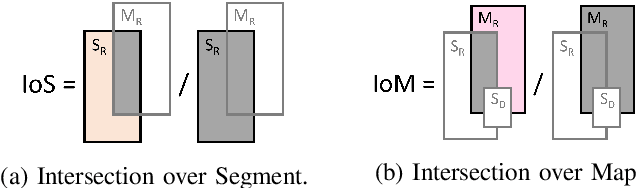

Artificial intelligence for autonomous driving must meet strict requirements on safety and robustness, which motivates the thorough validation of learned models. However, current validation approaches mostly require ground truth data and are thus both cost-intensive and limited in their applicability. We propose to overcome these limitations by a model agnostic validation using a-priori knowledge from street maps. In particular, we show how to validate semantic segmentation masks and demonstrate the potential of our approach using OpenStreetMap. We introduce validation metrics that indicate false positive or negative road segments. Besides the validation approach, we present a method to correct the vehicle's GPS position so that a more accurate localization can be used for the street-map based validation. Lastly, we present quantitative results on the Cityscapes dataset indicating that our validation approach can indeed uncover errors in semantic segmentation masks.
Supporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021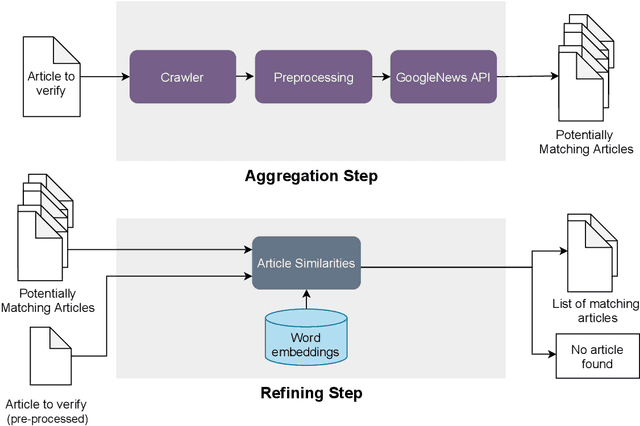

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.
Approaching Neural Network Uncertainty Realism
Jan 08, 2021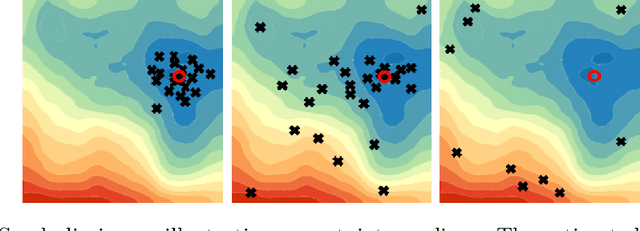
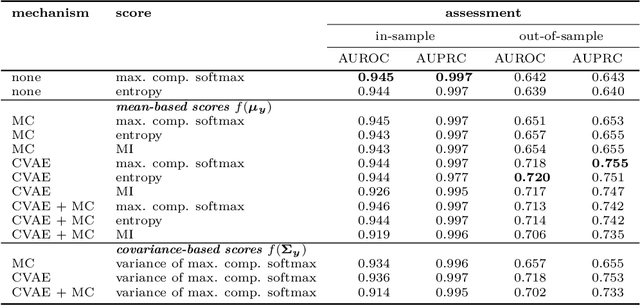
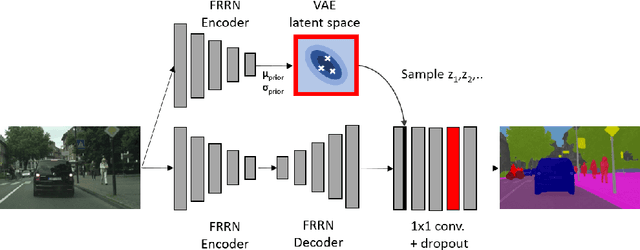
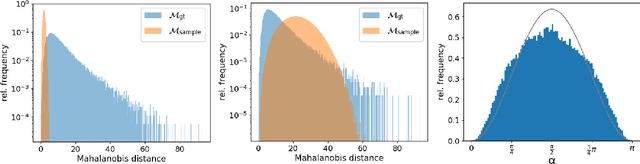
Statistical models are inherently uncertain. Quantifying or at least upper-bounding their uncertainties is vital for safety-critical systems such as autonomous vehicles. While standard neural networks do not report this information, several approaches exist to integrate uncertainty estimates into them. Assessing the quality of these uncertainty estimates is not straightforward, as no direct ground truth labels are available. Instead, implicit statistical assessments are required. For regression, we propose to evaluate uncertainty realism -- a strict quality criterion -- with a Mahalanobis distance-based statistical test. An empirical evaluation reveals the need for uncertainty measures that are appropriate to upper-bound heavy-tailed empirical errors. Alongside, we transfer the variational U-Net classification architecture to standard supervised image-to-image tasks. We adopt it to the automotive domain and show that it significantly improves uncertainty realism compared to a plain encoder-decoder model.
A Novel Regression Loss for Non-Parametric Uncertainty Optimization
Jan 07, 2021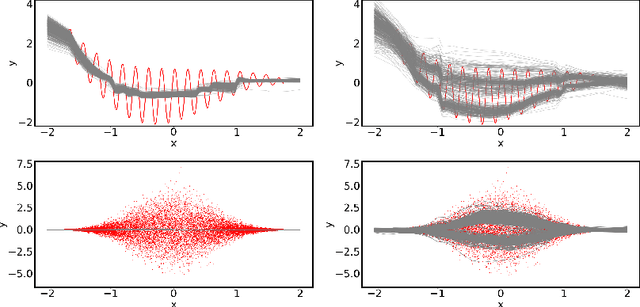
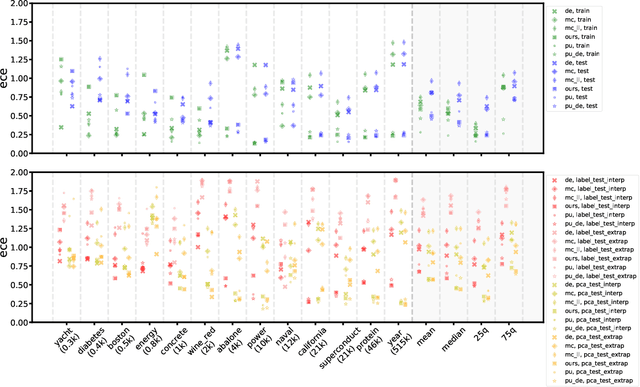
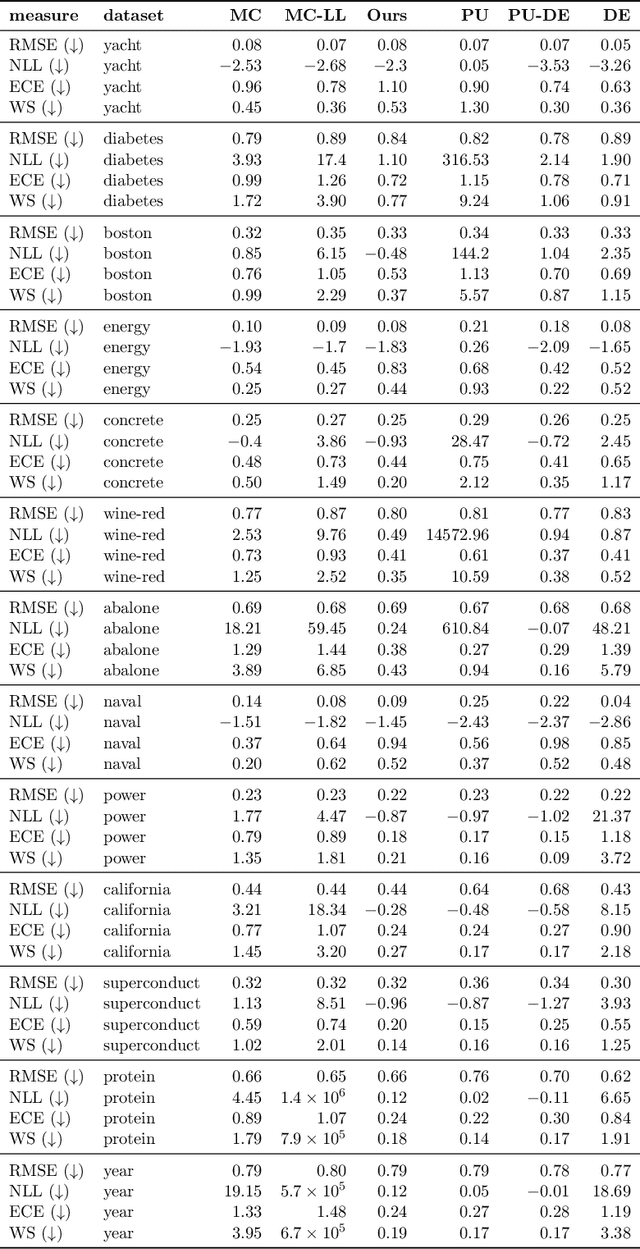
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We intensively study the performance of the new objective on various UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.