 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Theory of a Black-Box: A Life Cycle-Scale XAI Framework Based on Constructive Empiricism
Feb 02, 2026Explainable AI (XAI) offers a growing number of algorithms that aim to answer specific questions about black-box models. What is missing is a principled way to consolidate explanatory information about a fixed black-box model into a persistent, auditable artefact, that accompanies the black-box throughout its life cycle. We address this gap by introducing the notion of a scientific theory of a black (SToBB). Grounded in Constructive Empiricism, a SToBB fulfils three obligations: (i) empirical adequacy with respect to all available observations of black-box behaviour, (ii) adaptability via explicit update commitments that restore adequacy when new observations arrive, and (iii) auditability through transparent documentation of assumptions, construction choices, and update behaviour. We operationalise these obligations as a general framework that specifies an extensible observation base, a traceable hypothesis class, algorithmic components for construction and revision, and documentation sufficient for third-party assessment. Explanations for concrete stakeholder needs are then obtained by querying the maintained record through interfaces, rather than by producing isolated method outputs. As a proof of concept, we instantiate a complete SToBB for a neural-network classifier on a tabular task and introduce the Constructive Box Theoriser (CoBoT) algorithm, an online procedure that constructs and maintains an empirically adequate rule-based surrogate as observations accumulate. Together, these contributions position SToBBs as a life cycle-scale, inspectable point of reference that supports consistent, reusable analyses and systematic external scrutiny.
Four Quadrants of Difficulty: A Simple Categorisation and its Limits
Jan 04, 2026Curriculum Learning (CL) aims to improve the outcome of model training by estimating the difficulty of samples and scheduling them accordingly. In NLP, difficulty is commonly approximated using task-agnostic linguistic heuristics or human intuition, implicitly assuming that these signals correlate with what neural models find difficult to learn. We propose a four-quadrant categorisation of difficulty signals -- human vs. model and task-agnostic vs. task-dependent -- and systematically analyse their interactions on a natural language understanding dataset. We find that task-agnostic features behave largely independently and that only task-dependent features align. These findings challenge common CL intuitions and highlight the need for lightweight, task-dependent difficulty estimators that better reflect model learning behaviour.
A Survey on Current Trends and Recent Advances in Text Anonymization
Aug 29, 2025The proliferation of textual data containing sensitive personal information across various domains requires robust anonymization techniques to protect privacy and comply with regulations, while preserving data usability for diverse and crucial downstream tasks. This survey provides a comprehensive overview of current trends and recent advances in text anonymization techniques. We begin by discussing foundational approaches, primarily centered on Named Entity Recognition, before examining the transformative impact of Large Language Models, detailing their dual role as sophisticated anonymizers and potent de-anonymization threats. The survey further explores domain-specific challenges and tailored solutions in critical sectors such as healthcare, law, finance, and education. We investigate advanced methodologies incorporating formal privacy models and risk-aware frameworks, and address the specialized subfield of authorship anonymization. Additionally, we review evaluation frameworks, comprehensive metrics, benchmarks, and practical toolkits for real-world deployment of anonymization solutions. This review consolidates current knowledge, identifies emerging trends and persistent challenges, including the evolving privacy-utility trade-off, the need to address quasi-identifiers, and the implications of LLM capabilities, and aims to guide future research directions for both academics and practitioners in this field.
Beyond Shallow Heuristics: Leveraging Human Intuition for Curriculum Learning
Aug 27, 2025Curriculum learning (CL) aims to improve training by presenting data from "easy" to "hard", yet defining and measuring linguistic difficulty remains an open challenge. We investigate whether human-curated simple language can serve as an effective signal for CL. Using the article-level labels from the Simple Wikipedia corpus, we compare label-based curricula to competence-based strategies relying on shallow heuristics. Our experiments with a BERT-tiny model show that adding simple data alone yields no clear benefit. However, structuring it via a curriculum -- especially when introduced first -- consistently improves perplexity, particularly on simple language. In contrast, competence-based curricula lead to no consistent gains over random ordering, probably because they fail to effectively separate the two classes. Our results suggest that human intuition about linguistic difficulty can guide CL for language model pre-training.
Towards Automated Regulatory Compliance Verification in Financial Auditing with Large Language Models
Jul 22, 2025The auditing of financial documents, historically a labor-intensive process, stands on the precipice of transformation. AI-driven solutions have made inroads into streamlining this process by recommending pertinent text passages from financial reports to align with the legal requirements of accounting standards. However, a glaring limitation remains: these systems commonly fall short in verifying if the recommended excerpts indeed comply with the specific legal mandates. Hence, in this paper, we probe the efficiency of publicly available Large Language Models (LLMs) in the realm of regulatory compliance across different model configurations. We place particular emphasis on comparing cutting-edge open-source LLMs, such as Llama-2, with their proprietary counterparts like OpenAI's GPT models. This comparative analysis leverages two custom datasets provided by our partner PricewaterhouseCoopers (PwC) Germany. We find that the open-source Llama-2 70 billion model demonstrates outstanding performance in detecting non-compliance or true negative occurrences, beating all their proprietary counterparts. Nevertheless, proprietary models such as GPT-4 perform the best in a broad variety of scenarios, particularly in non-English contexts.
* Accepted and published at BigData 2023, 10 pages, 3 figures, 5 tables
Interpretable Topic Extraction and Word Embedding Learning using row-stochastic DEDICOM
Jul 22, 2025The DEDICOM algorithm provides a uniquely interpretable matrix factorization method for symmetric and asymmetric square matrices. We employ a new row-stochastic variation of DEDICOM on the pointwise mutual information matrices of text corpora to identify latent topic clusters within the vocabulary and simultaneously learn interpretable word embeddings. We introduce a method to efficiently train a constrained DEDICOM algorithm and a qualitative evaluation of its topic modeling and word embedding performance.
* Accepted and published at CD-MAKE 2020, 20 pages, 8 tables, 8 figures
Kernel $k$-Medoids as General Vector Quantization
Jun 05, 2025Vector Quantization (VQ) is a widely used technique in machine learning and data compression, valued for its simplicity and interpretability. Among hard VQ methods, $k$-medoids clustering and Kernel Density Estimation (KDE) approaches represent two prominent yet seemingly unrelated paradigms -- one distance-based, the other rooted in probability density matching. In this paper, we investigate their connection through the lens of Quadratic Unconstrained Binary Optimization (QUBO). We compare a heuristic QUBO formulation for $k$-medoids, which balances centrality and diversity, with a principled QUBO derived from minimizing Maximum Mean Discrepancy in KDE-based VQ. Surprisingly, we show that the KDE-QUBO is a special case of the $k$-medoids-QUBO under mild assumptions on the kernel's feature map. This reveals a deeper structural relationship between these two approaches and provides new insight into the geometric interpretation of the weighting parameters used in QUBO formulations for VQ.
Efficient Quantum Convolutional Neural Networks for Image Classification: Overcoming Hardware Constraints
May 09, 2025While classical convolutional neural networks (CNNs) have revolutionized image classification, the emergence of quantum computing presents new opportunities for enhancing neural network architectures. Quantum CNNs (QCNNs) leverage quantum mechanical properties and hold potential to outperform classical approaches. However, their implementation on current noisy intermediate-scale quantum (NISQ) devices remains challenging due to hardware limitations. In our research, we address this challenge by introducing an encoding scheme that significantly reduces the input dimensionality. We demonstrate that a primitive QCNN architecture with 49 qubits is sufficient to directly process $28\times 28$ pixel MNIST images, eliminating the need for classical dimensionality reduction pre-processing. Additionally, we propose an automated framework based on expressibility, entanglement, and complexity characteristics to identify the building blocks of QCNNs, parameterized quantum circuits (PQCs). Our approach demonstrates advantages in accuracy and convergence speed with a similar parameter count compared to both hybrid QCNNs and classical CNNs. We validated our experiments on IBM's Heron r2 quantum processor, achieving $96.08\%$ classification accuracy, surpassing the $71.74\%$ benchmark of traditional approaches under identical training conditions. These results represent one of the first implementations of image classifications on real quantum hardware and validate the potential of quantum computing in this area.
CFIRE: A General Method for Combining Local Explanations
Apr 01, 2025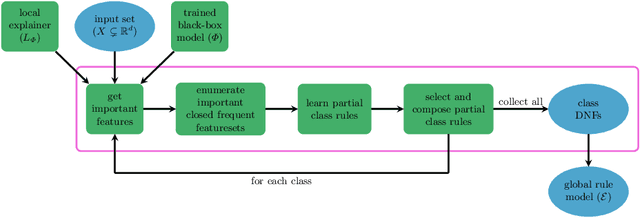
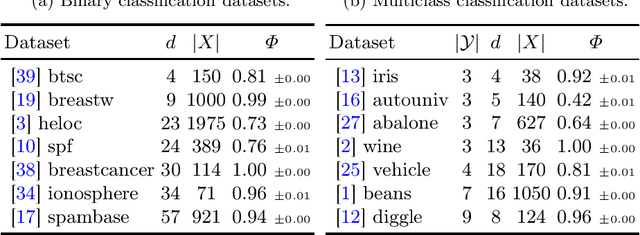

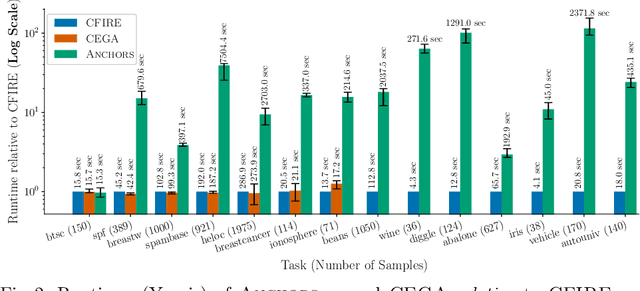
We propose a novel eXplainable AI algorithm to compute faithful, easy-to-understand, and complete global decision rules from local explanations for tabular data by combining XAI methods with closed frequent itemset mining. Our method can be used with any local explainer that indicates which dimensions are important for a given sample for a given black-box decision. This property allows our algorithm to choose among different local explainers, addressing the disagreement problem, \ie the observation that no single explanation method consistently outperforms others across models and datasets. Unlike usual experimental methodology, our evaluation also accounts for the Rashomon effect in model explainability. To this end, we demonstrate the robustness of our approach in finding suitable rules for nearly all of the 700 black-box models we considered across 14 benchmark datasets. The results also show that our method exhibits improved runtime, high precision and F1-score while generating compact and complete rules.
Immersive Explainability: Visualizing Robot Navigation Decisions through XAI Semantic Scene Projections in Virtual Reality
Apr 01, 2025End-to-end robot policies achieve high performance through neural networks trained via reinforcement learning (RL). Yet, their black box nature and abstract reasoning pose challenges for human-robot interaction (HRI), because humans may experience difficulty in understanding and predicting the robot's navigation decisions, hindering trust development. We present a virtual reality (VR) interface that visualizes explainable AI (XAI) outputs and the robot's lidar perception to support intuitive interpretation of RL-based navigation behavior. By visually highlighting objects based on their attribution scores, the interface grounds abstract policy explanations in the scene context. This XAI visualization bridges the gap between obscure numerical XAI attribution scores and a human-centric semantic level of explanation. A within-subjects study with 24 participants evaluated the effectiveness of our interface for four visualization conditions combining XAI and lidar. Participants ranked scene objects across navigation scenarios based on their importance to the robot, followed by a questionnaire assessing subjective understanding and predictability. Results show that semantic projection of attributions significantly enhances non-expert users' objective understanding and subjective awareness of robot behavior. In addition, lidar visualization further improves perceived predictability, underscoring the value of integrating XAI and sensor for transparent, trustworthy HRI.