 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Topic Extraction and Word Embedding Learning using row-stochastic DEDICOM
Jul 22, 2025The DEDICOM algorithm provides a uniquely interpretable matrix factorization method for symmetric and asymmetric square matrices. We employ a new row-stochastic variation of DEDICOM on the pointwise mutual information matrices of text corpora to identify latent topic clusters within the vocabulary and simultaneously learn interpretable word embeddings. We introduce a method to efficiently train a constrained DEDICOM algorithm and a qualitative evaluation of its topic modeling and word embedding performance.
* Accepted and published at CD-MAKE 2020, 20 pages, 8 tables, 8 figures
Advancing Risk and Quality Assurance: A RAG Chatbot for Improved Regulatory Compliance
Jul 22, 2025Risk and Quality (R&Q) assurance in highly regulated industries requires constant navigation of complex regulatory frameworks, with employees handling numerous daily queries demanding accurate policy interpretation. Traditional methods relying on specialized experts create operational bottlenecks and limit scalability. We present a novel Retrieval Augmented Generation (RAG) system leveraging Large Language Models (LLMs), hybrid search and relevance boosting to enhance R&Q query processing. Evaluated on 124 expert-annotated real-world queries, our actively deployed system demonstrates substantial improvements over traditional RAG approaches. Additionally, we perform an extensive hyperparameter analysis to compare and evaluate multiple configuration setups, delivering valuable insights to practitioners.
* Accepted and published at BigData 2024, 3 pages, 3 tables, 2 figures
Towards Automated Regulatory Compliance Verification in Financial Auditing with Large Language Models
Jul 22, 2025The auditing of financial documents, historically a labor-intensive process, stands on the precipice of transformation. AI-driven solutions have made inroads into streamlining this process by recommending pertinent text passages from financial reports to align with the legal requirements of accounting standards. However, a glaring limitation remains: these systems commonly fall short in verifying if the recommended excerpts indeed comply with the specific legal mandates. Hence, in this paper, we probe the efficiency of publicly available Large Language Models (LLMs) in the realm of regulatory compliance across different model configurations. We place particular emphasis on comparing cutting-edge open-source LLMs, such as Llama-2, with their proprietary counterparts like OpenAI's GPT models. This comparative analysis leverages two custom datasets provided by our partner PricewaterhouseCoopers (PwC) Germany. We find that the open-source Llama-2 70 billion model demonstrates outstanding performance in detecting non-compliance or true negative occurrences, beating all their proprietary counterparts. Nevertheless, proprietary models such as GPT-4 perform the best in a broad variety of scenarios, particularly in non-English contexts.
* Accepted and published at BigData 2023, 10 pages, 3 figures, 5 tables
Pointer-Guided Pre-Training: Infusing Large Language Models with Paragraph-Level Contextual Awareness
Jun 06, 2024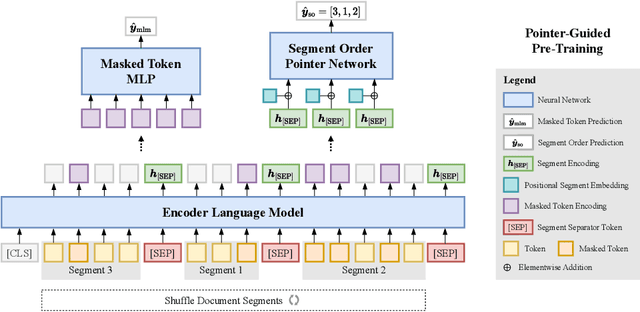
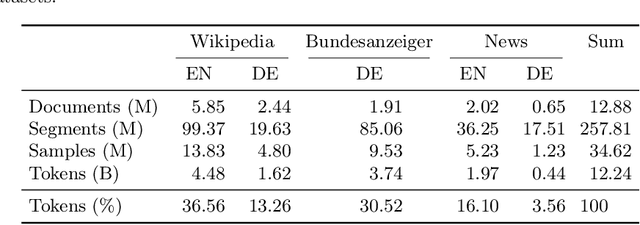
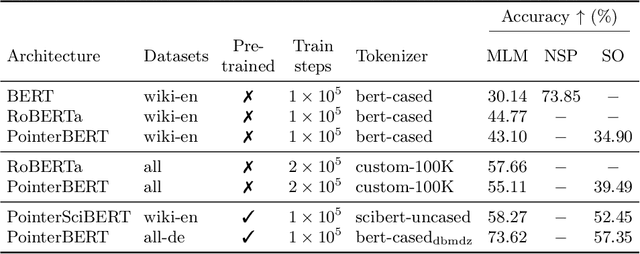
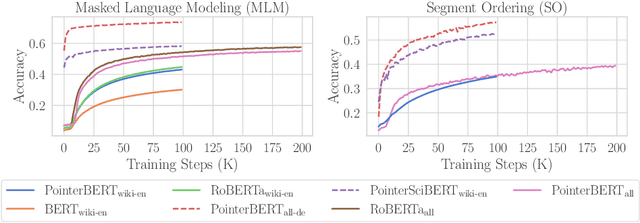
We introduce "pointer-guided segment ordering" (SO), a novel pre-training technique aimed at enhancing the contextual understanding of paragraph-level text representations in large language models. Our methodology leverages a self-attention-driven pointer network to restore the original sequence of shuffled text segments, addressing the challenge of capturing the structural coherence and contextual dependencies within documents. This pre-training approach is complemented by a fine-tuning methodology that incorporates dynamic sampling, augmenting the diversity of training instances and improving sample efficiency for various downstream applications. We evaluate our method on a diverse set of datasets, demonstrating its efficacy in tasks requiring sequential text classification across scientific literature and financial reporting domains. Our experiments show that pointer-guided pre-training significantly enhances the model's ability to understand complex document structures, leading to state-of-the-art performance in downstream classification tasks.
Informed Named Entity Recognition Decoding for Generative Language Models
Aug 15, 2023



Ever-larger language models with ever-increasing capabilities are by now well-established text processing tools. Alas, information extraction tasks such as named entity recognition are still largely unaffected by this progress as they are primarily based on the previous generation of encoder-only transformer models. Here, we propose a simple yet effective approach, Informed Named Entity Recognition Decoding (iNERD), which treats named entity recognition as a generative process. It leverages the language understanding capabilities of recent generative models in a future-proof manner and employs an informed decoding scheme incorporating the restricted nature of information extraction into open-ended text generation, improving performance and eliminating any risk of hallucinations. We coarse-tune our model on a merged named entity corpus to strengthen its performance, evaluate five generative language models on eight named entity recognition datasets, and achieve remarkable results, especially in an environment with an unknown entity class set, demonstrating the adaptability of the approach.
Improving Zero-Shot Text Matching for Financial Auditing with Large Language Models
Aug 14, 2023


Auditing financial documents is a very tedious and time-consuming process. As of today, it can already be simplified by employing AI-based solutions to recommend relevant text passages from a report for each legal requirement of rigorous accounting standards. However, these methods need to be fine-tuned regularly, and they require abundant annotated data, which is often lacking in industrial environments. Hence, we present ZeroShotALI, a novel recommender system that leverages a state-of-the-art large language model (LLM) in conjunction with a domain-specifically optimized transformer-based text-matching solution. We find that a two-step approach of first retrieving a number of best matching document sections per legal requirement with a custom BERT-based model and second filtering these selections using an LLM yields significant performance improvements over existing approaches.
sustain.AI: a Recommender System to analyze Sustainability Reports
May 26, 2023



We present sustainAI, an intelligent, context-aware recommender system that assists auditors and financial investors as well as the general public to efficiently analyze companies' sustainability reports. The tool leverages an end-to-end trainable architecture that couples a BERT-based encoding module with a multi-label classification head to match relevant text passages from sustainability reports to their respective law regulations from the Global Reporting Initiative (GRI) standards. We evaluate our model on two novel German sustainability reporting data sets and consistently achieve a significantly higher recommendation performance compared to multiple strong baselines. Furthermore, sustainAI is publicly available for everyone at https://sustain.ki.nrw/.
Towards automating Numerical Consistency Checks in Financial Reports
Nov 11, 2022



We introduce KPI-Check, a novel system that automatically identifies and cross-checks semantically equivalent key performance indicators (KPIs), e.g. "revenue" or "total costs", in real-world German financial reports. It combines a financial named entity and relation extraction module with a BERT-based filtering and text pair classification component to extract KPIs from unstructured sentences before linking them to synonymous occurrences in the balance sheet and profit & loss statement. The tool achieves a high matching performance of $73.00$% micro F$_1$ on a hold out test set and is currently being deployed for a globally operating major auditing firm to assist the auditing procedure of financial statements.
KPI-EDGAR: A Novel Dataset and Accompanying Metric for Relation Extraction from Financial Documents
Oct 17, 2022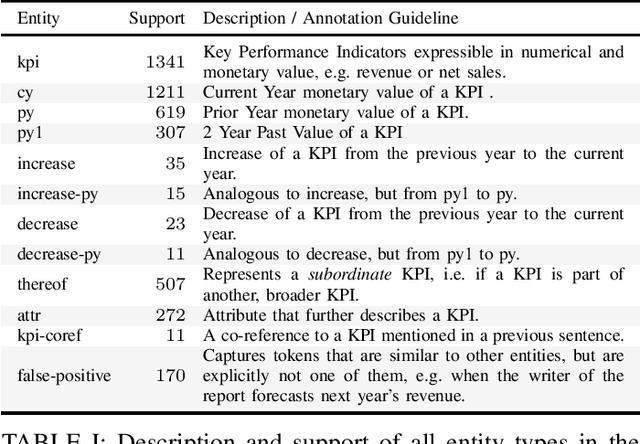
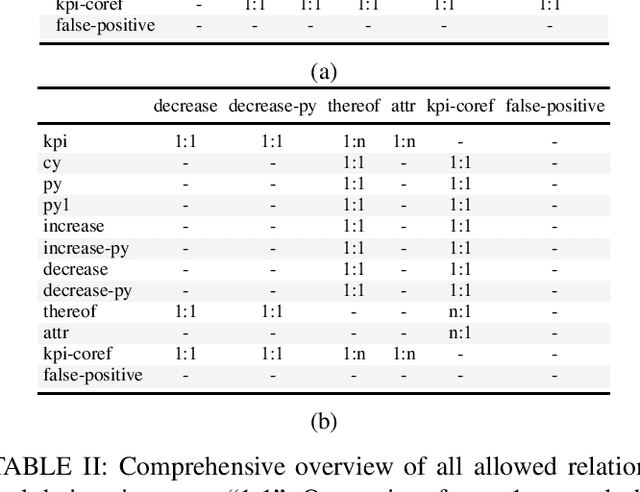

We introduce KPI-EDGAR, a novel dataset for Joint Named Entity Recognition and Relation Extraction building on financial reports uploaded to the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system, where the main objective is to extract Key Performance Indicators (KPIs) from financial documents and link them to their numerical values and other attributes. We further provide four accompanying baselines for benchmarking potential future research. Additionally, we propose a new way of measuring the success of said extraction process by incorporating a word-level weighting scheme into the conventional F1 score to better model the inherently fuzzy borders of the entity pairs of a relation in this domain.
KPI-BERT: A Joint Named Entity Recognition and Relation Extraction Model for Financial Reports
Aug 03, 2022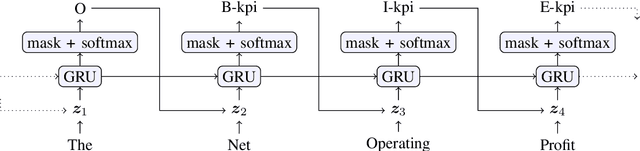
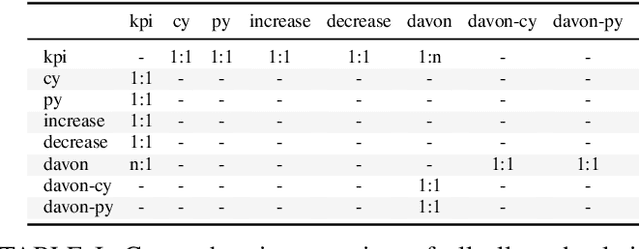

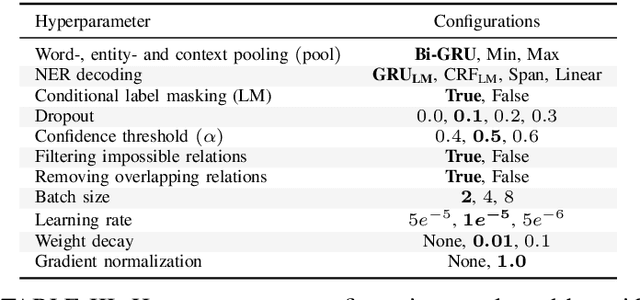
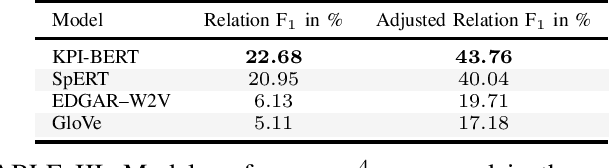
We present KPI-BERT, a system which employs novel methods of named entity recognition (NER) and relation extraction (RE) to extract and link key performance indicators (KPIs), e.g. "revenue" or "interest expenses", of companies from real-world German financial documents. Specifically, we introduce an end-to-end trainable architecture that is based on Bidirectional Encoder Representations from Transformers (BERT) combining a recurrent neural network (RNN) with conditional label masking to sequentially tag entities before it classifies their relations. Our model also introduces a learnable RNN-based pooling mechanism and incorporates domain expert knowledge by explicitly filtering impossible relations. We achieve a substantially higher prediction performance on a new practical dataset of German financial reports, outperforming several strong baselines including a competing state-of-the-art span-based entity tagging approach.