 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer-Guided Pre-Training: Infusing Large Language Models with Paragraph-Level Contextual Awareness
Jun 06, 2024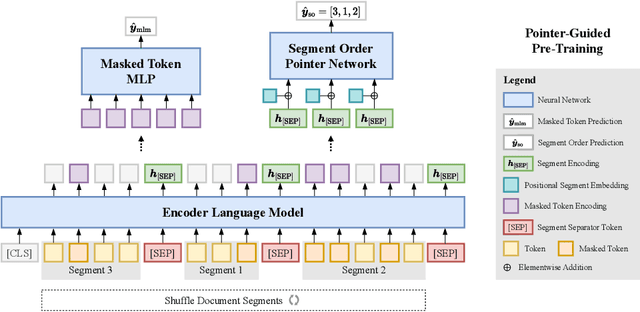
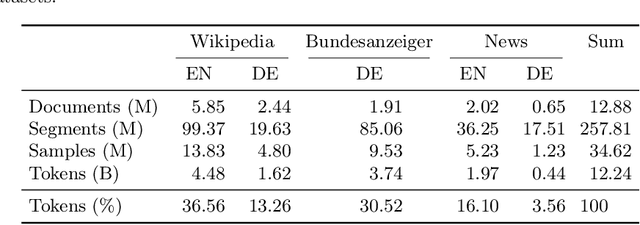
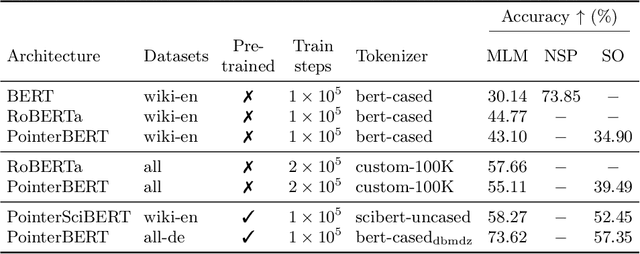
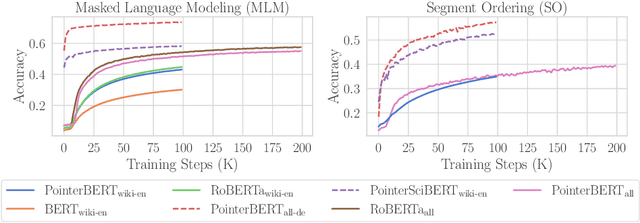
We introduce "pointer-guided segment ordering" (SO), a novel pre-training technique aimed at enhancing the contextual understanding of paragraph-level text representations in large language models. Our methodology leverages a self-attention-driven pointer network to restore the original sequence of shuffled text segments, addressing the challenge of capturing the structural coherence and contextual dependencies within documents. This pre-training approach is complemented by a fine-tuning methodology that incorporates dynamic sampling, augmenting the diversity of training instances and improving sample efficiency for various downstream applications. We evaluate our method on a diverse set of datasets, demonstrating its efficacy in tasks requiring sequential text classification across scientific literature and financial reporting domains. Our experiments show that pointer-guided pre-training significantly enhances the model's ability to understand complex document structures, leading to state-of-the-art performance in downstream classification tasks.