 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing When Not to Predict: Self Supervised Learning and Abstention for Safer DR Screening
May 18, 2026Self-supervised learning (SSL) is now a standard way to pretrain medical image models, but performance is still mostly judged by downstream accuracy. For safety-critical screening tasks such as diabetic retinopathy grading, this is not enough: a model must also know when its predictions are unreliable and defer uncertain cases for clinical review. In this work, we examine how the length of SSL pretraining influences calibrated confidence and confidence-based abstention. We evaluate multiple SSL checkpoints under a fixed fine-tuning protocol and assess calibrated confidence, coverage, selective accuracy, and selective macro-F1. Across datasets and data regimes, SSL pretraining improves selective prediction compared to training from scratch. Unlike prior SSL studies that primarily evaluate downstream accuracy or AUROC, we analyze how SSL pretraining duration influences confidence behavior under calibrated confidence-based abstention. However, once accuracy saturates, selective performance can still change markedly across checkpoints, and longer pretraining does not consistently improve reliability. These results underscore the importance of abstention-aware evaluation and suggest that pretraining length should be treated as an important reliability-related design choice rather than only a computational detail. Code is available at GitHub.
Is continuous CoT better suited for multi-lingual reasoning?
Mar 09, 2026We investigate whether performing reasoning in a continuous latent space leads to more robust multilingual capabilities. We compare Continuous Chain-of-Thought (using the CODI framework) against standard supervised fine-tuning across five typologically diverse languages: English, Chinese, German, French, and Urdu. Our experiments on GSM8k and CommonsenseQA demonstrate that continuous reasoning significantly outperforms explicit reasoning on low-resource languages, particularly in zero-shot settings where the target language was not seen during training. Additionally, this approach achieves extreme efficiency, compressing reasoning traces by approximately $29\times$ to $50\times$. These findings indicate that continuous latent representations naturally exhibit greater language invariance, offering a scalable solution for cross-lingual reasoning.
Towards Reliable Machine Translation: Scaling LLMs for Critical Error Detection and Safety
Feb 11, 2026Machine Translation (MT) plays a pivotal role in cross-lingual information access, public policy communication, and equitable knowledge dissemination. However, critical meaning errors, such as factual distortions, intent reversals, or biased translations, can undermine the reliability, fairness, and safety of multilingual systems. In this work, we explore the capacity of instruction-tuned Large Language Models (LLMs) to detect such critical errors, evaluating models across a range of parameters using the publicly accessible data sets. Our findings show that model scaling and adaptation strategies (zero-shot, few-shot, fine-tuning) yield consistent improvements, outperforming encoder-only baselines like XLM-R and ModernBERT. We argue that improving critical error detection in MT contributes to safer, more trustworthy, and socially accountable information systems by reducing the risk of disinformation, miscommunication, and linguistic harm, especially in high-stakes or underrepresented contexts. This work positions error detection not merely as a technical challenge, but as a necessary safeguard in the pursuit of just and responsible multilingual AI. The code will be made available at GitHub.
Modalities, a PyTorch-native Framework For Large-scale LLM Training and Research
Feb 09, 2026Today's LLM (pre-) training and research workflows typically allocate a significant amount of compute to large-scale ablation studies. Despite the substantial compute costs of these ablations, existing open-source frameworks provide limited tooling for these experiments, often forcing researchers to write their own wrappers and scripts. We propose Modalities, an end-to-end PyTorch-native framework that integrates data-driven LLM research with large-scale model training from two angles. Firstly, by integrating state-of-the-art parallelization strategies, it enables both efficient pretraining and systematic ablations at trillion-token and billion-parameter scale. Secondly, Modalities adopts modular design with declarative, self-contained configuration, enabling reproducibility and extensibility levels that are difficult to achieve out-of-the-box with existing LLM training frameworks.
Domain-Adaptation through Synthetic Data: Fine-Tuning Large Language Models for German Law
Jan 20, 2026Large language models (LLMs) often struggle in specialized domains such as legal reasoning due to limited expert knowledge, resulting in factually incorrect outputs or hallucinations. This paper presents an effective method for adapting advanced LLMs to German legal question answering through a novel synthetic data generation approach. In contrast to costly human-annotated resources or unreliable synthetic alternatives, our approach systematically produces high-quality, diverse, and legally accurate question-answer pairs directly from authoritative German statutes. Using rigorous automated filtering methods and parameter-efficient fine-tuning techniques, we demonstrate that LLMs adapted with our synthetic dataset significantly outperform their baseline counterparts on German legal question answering tasks. Our results highlight the feasibility of using carefully designed synthetic data as a robust alternative to manual annotation in high-stakes, knowledge-intensive domains.
Generalizing Abstention for Noise-Robust Learning in Medical Image Segmentation
Jan 20, 2026Label noise is a critical problem in medical image segmentation, often arising from the inherent difficulty of manual annotation. Models trained on noisy data are prone to overfitting, which degrades their generalization performance. While a number of methods and strategies have been proposed to mitigate noisy labels in the segmentation domain, this area remains largely under-explored. The abstention mechanism has proven effective in classification tasks by enhancing the capabilities of Cross Entropy, yet its potential in segmentation remains unverified. In this paper, we address this gap by introducing a universal and modular abstention framework capable of enhancing the noise-robustness of a diverse range of loss functions. Our framework improves upon prior work with two key components: an informed regularization term to guide abstention behaviour, and a more flexible power-law-based auto-tuning algorithm for the abstention penalty. We demonstrate the framework's versatility by systematically integrating it with three distinct loss functions to create three novel, noise-robust variants: GAC, SAC, and ADS. Experiments on the CaDIS and DSAD medical datasets show our methods consistently and significantly outperform their non-abstaining baselines, especially under high noise levels. This work establishes that enabling models to selectively ignore corrupted samples is a powerful and generalizable strategy for building more reliable segmentation models. Our code is publicly available at https://github.com/wemous/abstention-for-segmentation.
Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
Dec 28, 2025Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors high-resource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institution-agnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised fine-tuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.
History Rhymes: Macro-Contextual Retrieval for Robust Financial Forecasting
Nov 16, 2025Financial markets are inherently non-stationary: structural breaks and macroeconomic regime shifts often cause forecasting models to fail when deployed out of distribution (OOD). Conventional multimodal approaches that simply fuse numerical indicators and textual sentiment rarely adapt to such shifts. We introduce macro-contextual retrieval, a retrieval-augmented forecasting framework that grounds each prediction in historically analogous macroeconomic regimes. The method jointly embeds macro indicators (e.g., CPI, unemployment, yield spread, GDP growth) and financial news sentiment in a shared similarity space, enabling causal retrieval of precedent periods during inference without retraining. Trained on seventeen years of S&P 500 data (2007-2023) and evaluated OOD on AAPL (2024) and XOM (2024), the framework consistently narrows the CV to OOD performance gap. Macro-conditioned retrieval achieves the only positive out-of-sample trading outcomes (AAPL: PF=1.18, Sharpe=0.95; XOM: PF=1.16, Sharpe=0.61), while static numeric, text-only, and naive multimodal baselines collapse under regime shifts. Beyond metric gains, retrieved neighbors form interpretable evidence chains that correspond to recognizable macro contexts, such as inflationary or yield-curve inversion phases, supporting causal interpretability and transparency. By operationalizing the principle that "financial history may not repeat, but it often rhymes," this work demonstrates that macro-aware retrieval yields robust, explainable forecasts under distributional change. All datasets, models, and source code are publicly available.
From Retinal Pixels to Patients: Evolution of Deep Learning Research in Diabetic Retinopathy Screening
Nov 14, 2025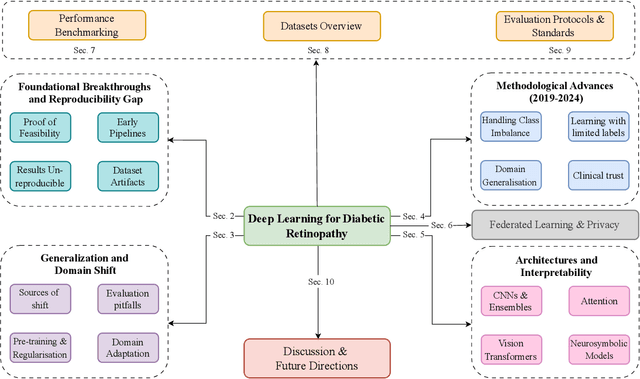

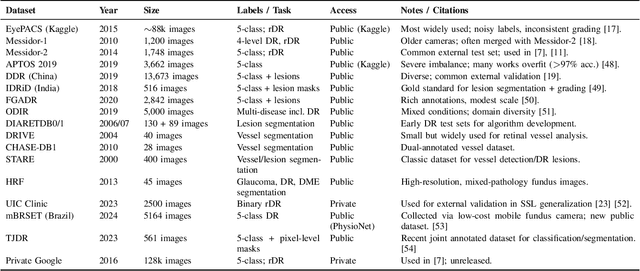
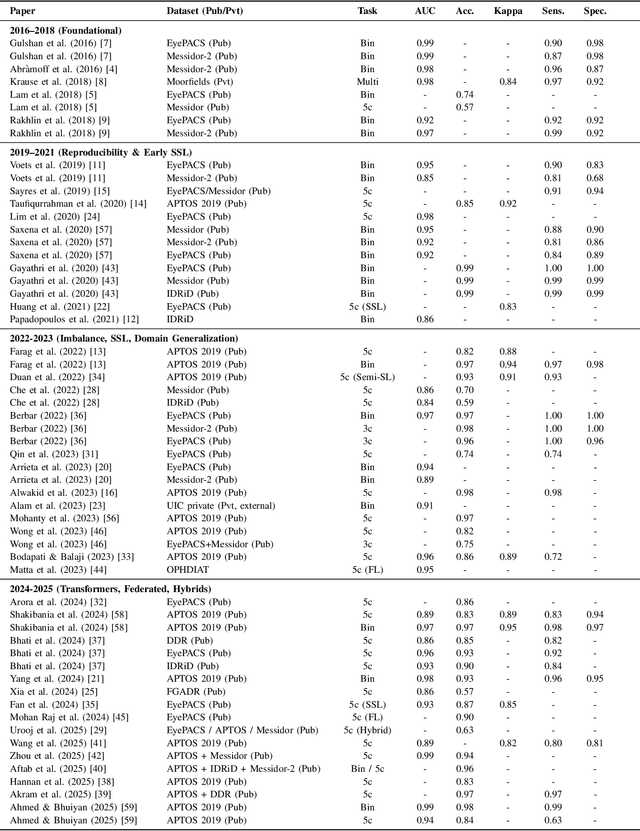
Diabetic Retinopathy (DR) remains a leading cause of preventable blindness, with early detection critical for reducing vision loss worldwide. Over the past decade, deep learning has transformed DR screening, progressing from early convolutional neural networks trained on private datasets to advanced pipelines addressing class imbalance, label scarcity, domain shift, and interpretability. This survey provides the first systematic synthesis of DR research spanning 2016-2025, consolidating results from 50+ studies and over 20 datasets. We critically examine methodological advances, including self- and semi-supervised learning, domain generalization, federated training, and hybrid neuro-symbolic models, alongside evaluation protocols, reporting standards, and reproducibility challenges. Benchmark tables contextualize performance across datasets, while discussion highlights open gaps in multi-center validation and clinical trust. By linking technical progress with translational barriers, this work outlines a practical agenda for reproducible, privacy-preserving, and clinically deployable DR AI. Beyond DR, many of the surveyed innovations extend broadly to medical imaging at scale.
How Small Can You Go? Compact Language Models for On-Device Critical Error Detection in Machine Translation
Nov 12, 2025Large Language Models (LLMs) excel at evaluating machine translation (MT), but their scale and cost hinder deployment on edge devices and in privacy-sensitive workflows. We ask: how small can you get while still detecting meaning-altering translation errors? Focusing on English->German Critical Error Detection (CED), we benchmark sub-2B models (LFM2-350M, Qwen-3-0.6B/1.7B, Llama-3.2-1B-Instruct, Gemma-3-1B) across WMT21, WMT22, and SynCED-EnDe-2025. Our framework standardizes prompts, applies lightweight logit-bias calibration and majority voting, and reports both semantic quality (MCC, F1-ERR/F1-NOT) and compute metrics (VRAM, latency, throughput). Results reveal a clear sweet spot around one billion parameters: Gemma-3-1B provides the best quality-efficiency trade-off, reaching MCC=0.77 with F1-ERR=0.98 on SynCED-EnDe-2025 after merged-weights fine-tuning, while maintaining 400 ms single-sample latency on a MacBook Pro M4 Pro (24 GB). At larger scale, Qwen-3-1.7B attains the highest absolute MCC (+0.11 over Gemma) but with higher compute cost. In contrast, ultra-small models (0.6B) remain usable with few-shot calibration yet under-detect entity and number errors. Overall, compact, instruction-tuned LLMs augmented with lightweight calibration and small-sample supervision can deliver trustworthy, on-device CED for MT, enabling private, low-cost error screening in real-world translation pipelines. All datasets, prompts, and scripts are publicly available at our GitHub repository.