 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGG-BBQ: German Gender Bias Benchmark for Question Answering
Jul 22, 2025Within the context of Natural Language Processing (NLP), fairness evaluation is often associated with the assessment of bias and reduction of associated harm. In this regard, the evaluation is usually carried out by using a benchmark dataset, for a task such as Question Answering, created for the measurement of bias in the model's predictions along various dimensions, including gender identity. In our work, we evaluate gender bias in German Large Language Models (LLMs) using the Bias Benchmark for Question Answering by Parrish et al. (2022) as a reference. Specifically, the templates in the gender identity subset of this English dataset were machine translated into German. The errors in the machine translated templates were then manually reviewed and corrected with the help of a language expert. We find that manual revision of the translation is crucial when creating datasets for gender bias evaluation because of the limitations of machine translation from English to a language such as German with grammatical gender. Our final dataset is comprised of two subsets: Subset-I, which consists of group terms related to gender identity, and Subset-II, where group terms are replaced with proper names. We evaluate several LLMs used for German NLP on this newly created dataset and report the accuracy and bias scores. The results show that all models exhibit bias, both along and against existing social stereotypes.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023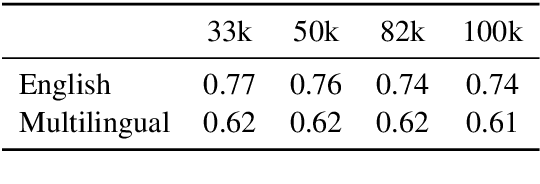
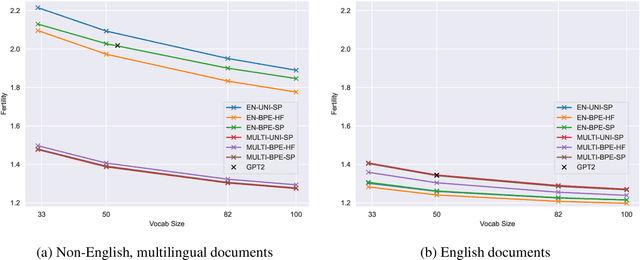
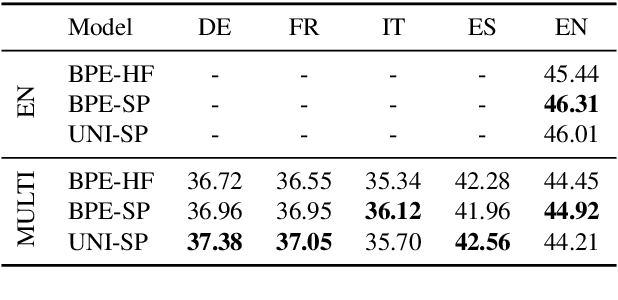
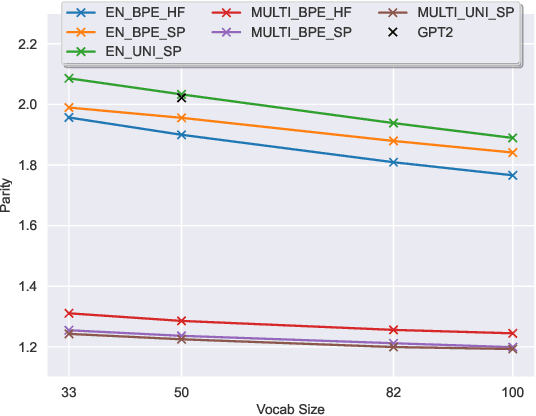
The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.