 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Artificial Scientist -- in-transit Machine Learning of Plasma Simulations
Jan 06, 2025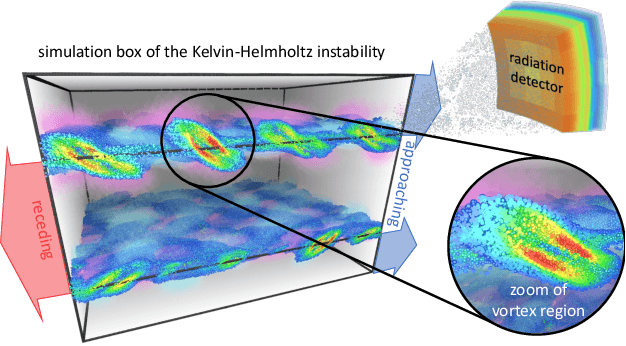
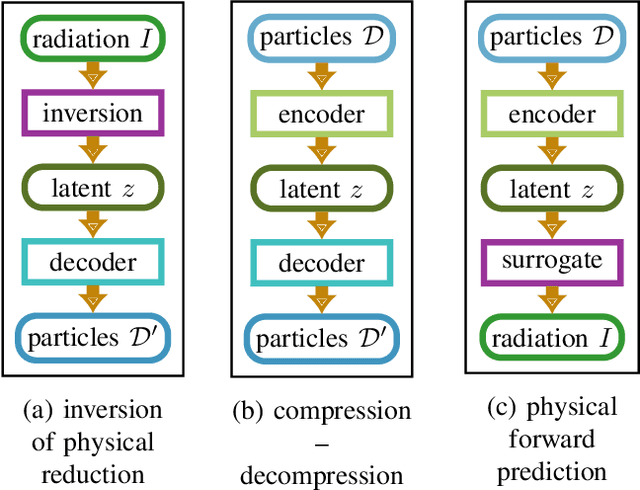
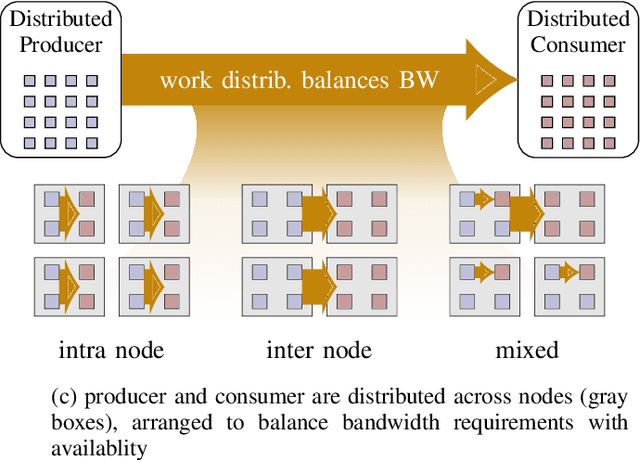
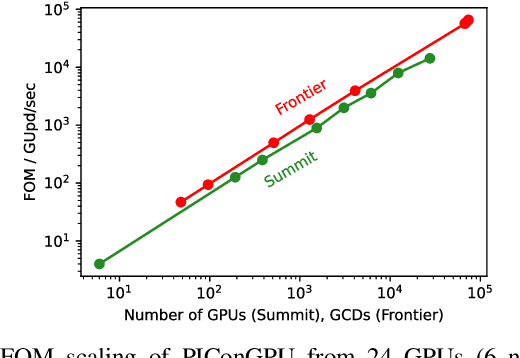
Increasing HPC cluster sizes and large-scale simulations that produce petabytes of data per run, create massive IO and storage challenges for analysis. Deep learning-based techniques, in particular, make use of these amounts of domain data to extract patterns that help build scientific understanding. Here, we demonstrate a streaming workflow in which simulation data is streamed directly to a machine-learning (ML) framework, circumventing the file system bottleneck. Data is transformed in transit, asynchronously to the simulation and the training of the model. With the presented workflow, data operations can be performed in common and easy-to-use programming languages, freeing the application user from adapting the application output routines. As a proof-of-concept we consider a GPU accelerated particle-in-cell (PIConGPU) simulation of the Kelvin- Helmholtz instability (KHI). We employ experience replay to avoid catastrophic forgetting in learning from this non-steady process in a continual manner. We detail challenges addressed while porting and scaling to Frontier exascale system.
Time Transfer: On Optimal Learning Rate and Batch Size In The Infinite Data Limit
Oct 08, 2024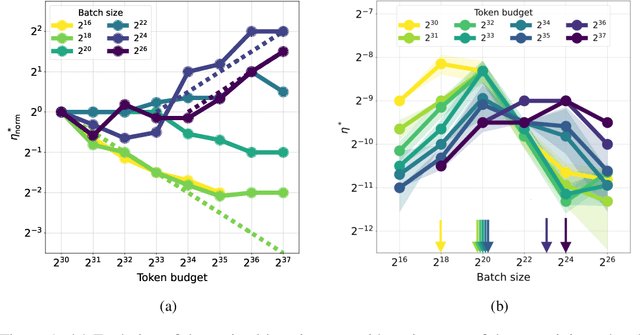
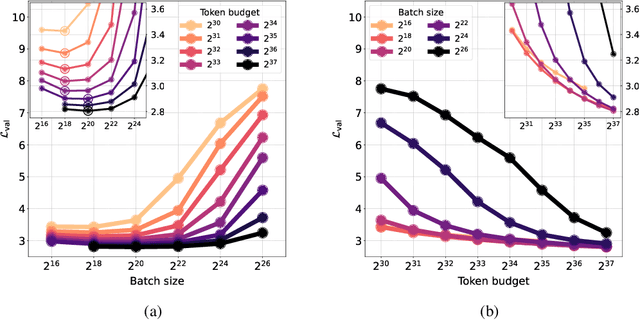
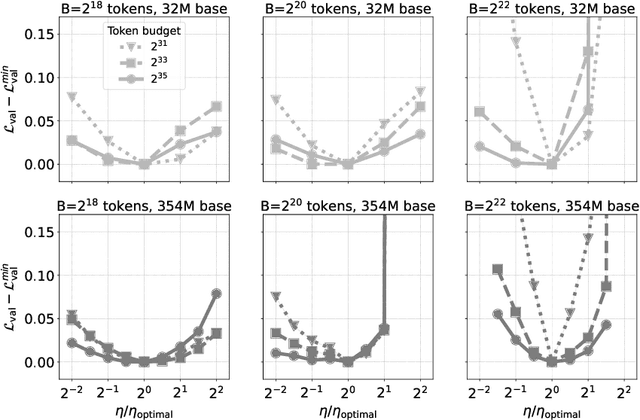
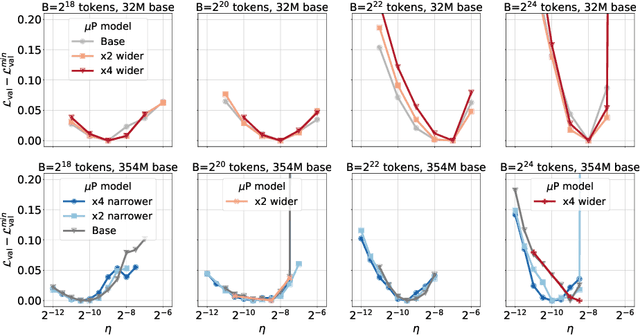
One of the main challenges in optimal scaling of large language models (LLMs) is the prohibitive cost of hyperparameter tuning, particularly learning rate $\eta$ and batch size $B$. While techniques like $\mu$P (Yang et al., 2022) provide scaling rules for optimal $\eta$ transfer in the infinite model size limit, the optimal scaling behavior in the infinite data size limit ($T \to \infty$) remains unknown. We fill in this gap by observing for the first time an interplay of three optimal $\eta$ scaling regimes: $\eta \propto \sqrt{T}$, $\eta \propto 1$, and $\eta \propto 1/\sqrt{T}$ with transitions controlled by $B$ and its relation to the time-evolving critical batch size $B_\mathrm{crit} \propto T$. Furthermore, we show that the optimal batch size is positively correlated with $B_\mathrm{crit}$: keeping it fixed becomes suboptimal over time even if learning rate is scaled optimally. Surprisingly, our results demonstrate that the observed optimal $\eta$ and $B$ dynamics are preserved with $\mu$P model scaling, challenging the conventional view of $B_\mathrm{crit}$ dependence solely on loss value. Complementing optimality, we examine the sensitivity of loss to changes in learning rate, where we find the sensitivity to decrease with $T \to \infty$ and to remain constant with $\mu$P model scaling. We hope our results make the first step towards a unified picture of the joint optimal data and model scaling.
Investigating Multilingual Instruction-Tuning: Do Polyglot Models Demand for Multilingual Instructions?
Feb 21, 2024The adaption of multilingual pre-trained Large Language Models (LLMs) into eloquent and helpful assistants is essential to facilitate their use across different language regions. In that spirit, we are the first to conduct an extensive study of the performance of multilingual models on parallel, multi-turn instruction-tuning benchmarks across a selection of the most-spoken Indo-European languages. We systematically examine the effects of language and instruction dataset size on a mid-sized, multilingual LLM by instruction-tuning it on parallel instruction-tuning datasets. Our results demonstrate that instruction-tuning on parallel instead of monolingual corpora benefits cross-lingual instruction following capabilities by up to 4.6%. Furthermore, we show that the Superficial Alignment Hypothesis does not hold in general, as the investigated multilingual 7B parameter model presents a counter-example requiring large-scale instruction-tuning datasets. Finally, we conduct a human annotation study to understand the alignment between human-based and GPT-4-based evaluation within multilingual chat scenarios.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023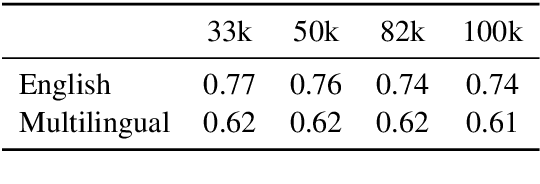
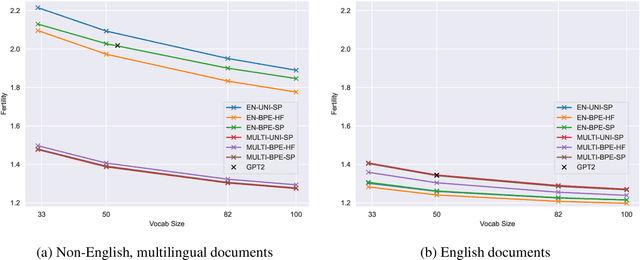
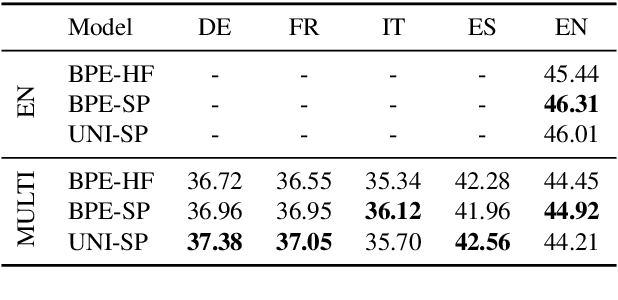
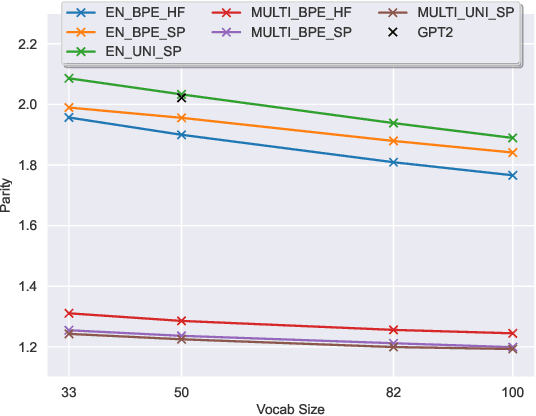
The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.
Physics informed Neural Networks applied to the description of wave-particle resonance in kinetic simulations of fusion plasmas
Aug 23, 2023



The Vlasov-Poisson system is employed in its reduced form version (1D1V) as a test bed for the applicability of Physics Informed Neural Network (PINN) to the wave-particle resonance. Two examples are explored: the Landau damping and the bump-on-tail instability. PINN is first tested as a compression method for the solution of the Vlasov-Poisson system and compared to the standard neural networks. Second, the application of PINN to solving the Vlasov-Poisson system is also presented with the special emphasis on the integral part, which motivates the implementation of a PINN variant, called Integrable PINN (I-PINN), based on the automatic-differentiation to solve the partial differential equation and on the automatic-integration to solve the integral equation.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Hearts Gym: Learning Reinforcement Learning as a Team Event
Sep 07, 2022Amidst the COVID-19 pandemic, the authors of this paper organized a Reinforcement Learning (RL) course for a graduate school in the field of data science. We describe the strategy and materials for creating an exciting learning experience despite the ubiquitous Zoom fatigue and evaluate the course qualitatively. The key organizational features are a focus on a competitive hands-on setting in teams, supported by a minimum of lectures providing the essential background on RL. The practical part of the course revolved around Hearts Gym, an RL environment for the card game Hearts that we developed as an entry-level tutorial to RL. Participants were tasked with training agents to explore reward shaping and other RL hyperparameters. For a final evaluation, the agents of the participants competed against each other.