 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable phase retrieval for coherent transition radiation spectroscopy based on differentiable physics information
Apr 28, 2026Coherent transition radiation (CTR) spectroscopy is a critical diagnostic for characterizing the longitudinal structure of relativistic electron bunches in laser-plasma and conventional accelerators. In practice, recovering the bunch profile from a measured CTR spectrum is an ill-posed phase-retrieval problem. Traditionally, this is addressed using Gerchberg-Saxton (GS)-type iterative algorithms. However, these implementations often rely on explicit inverse propagators, making them difficult to adapt to sophisticated experimental forward models. In this work, we introduce a flexible gradient-based framework for CTR phase retrieval. By leveraging a differentiable forward model, we propose a phase-only gradient descent (GD-Phase) approach that enforces the measured spectral amplitude as a hard constraint while optimizing the Fourier phase under physical real-space priors. Using synthetic CTR spectra spanning multi-peaked and strongly modulated profiles, we benchmark GD-Phase against traditional GS and a real-space amplitude-parametrized gradient descent (GD-Amp) algorithm. Unlike traditional methods, this formulation allows for the seamless inclusion of arbitrary differentiable experimental effects into the reconstruction loop. We demonstrate that this physics-informed approach not only reproduces the fidelity of GS methods but also establishes a robust baseline for incorporating multi-diagnostic constraints and uncertainty quantification. This enables the systematic extension to higher-dimensional, multimodal, and uncertainty-aware diagnostics, facilitating fast and scalable phase retrieval in realistic experimental settings.
The Artificial Scientist -- in-transit Machine Learning of Plasma Simulations
Jan 06, 2025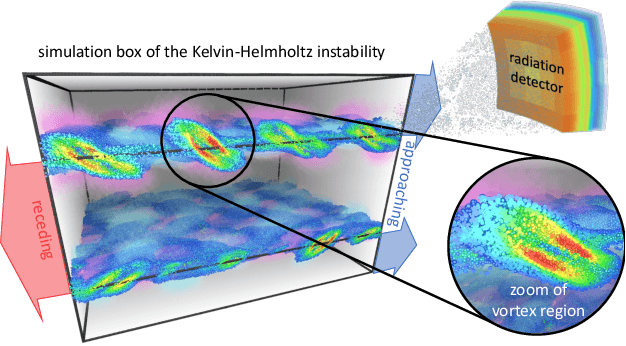
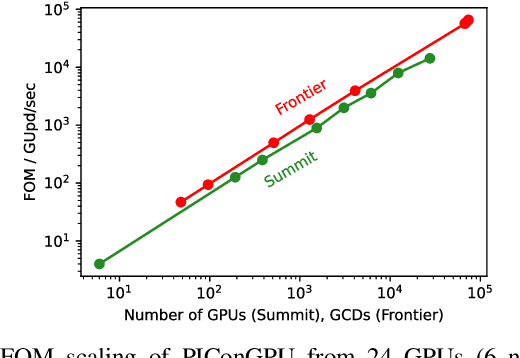
Increasing HPC cluster sizes and large-scale simulations that produce petabytes of data per run, create massive IO and storage challenges for analysis. Deep learning-based techniques, in particular, make use of these amounts of domain data to extract patterns that help build scientific understanding. Here, we demonstrate a streaming workflow in which simulation data is streamed directly to a machine-learning (ML) framework, circumventing the file system bottleneck. Data is transformed in transit, asynchronously to the simulation and the training of the model. With the presented workflow, data operations can be performed in common and easy-to-use programming languages, freeing the application user from adapting the application output routines. As a proof-of-concept we consider a GPU accelerated particle-in-cell (PIConGPU) simulation of the Kelvin- Helmholtz instability (KHI). We employ experience replay to avoid catastrophic forgetting in learning from this non-steady process in a continual manner. We detail challenges addressed while porting and scaling to Frontier exascale system.
Advancing oncology with federated learning: transcending boundaries in breast, lung, and prostate cancer. A systematic review
Aug 08, 2024Federated Learning (FL) has emerged as a promising solution to address the limitations of centralised machine learning (ML) in oncology, particularly in overcoming privacy concerns and harnessing the power of diverse, multi-center data. This systematic review synthesises current knowledge on the state-of-the-art FL in oncology, focusing on breast, lung, and prostate cancer. Distinct from previous surveys, our comprehensive review critically evaluates the real-world implementation and impact of FL on cancer care, demonstrating its effectiveness in enhancing ML generalisability, performance and data privacy in clinical settings and data. We evaluated state-of-the-art advances in FL, demonstrating its growing adoption amid tightening data privacy regulations. FL outperformed centralised ML in 15 out of the 25 studies reviewed, spanning diverse ML models and clinical applications, and facilitating integration of multi-modal information for precision medicine. Despite the current challenges identified in reproducibility, standardisation and methodology across studies, the demonstrable benefits of FL in harnessing real-world data and addressing clinical needs highlight its significant potential for advancing cancer research. We propose that future research should focus on addressing these limitations and investigating further advanced FL methods, to fully harness data diversity and realise the transformative power of cutting-edge FL in cancer care.
Kidnapping Deep Learning-based Multirotors using Optimized Flying Adversarial Patches
Aug 01, 2023
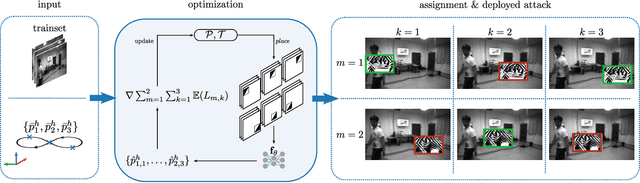
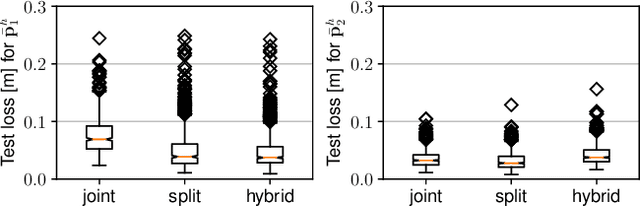
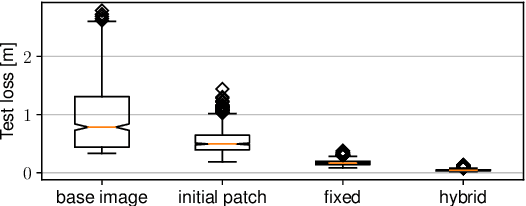
Autonomous flying robots, such as multirotors, often rely on deep learning models that makes predictions based on a camera image, e.g. for pose estimation. These models can predict surprising results if applied to input images outside the training domain. This fault can be exploited by adversarial attacks, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where multiple images are mounted on at least one other flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. By introducing the attacker robots, the system is extended to an adversarial multi-robot system. For an effective attack, we compare three methods that simultaneously optimize multiple adversarial patches and their position in the input image. We show that our methods scale well with the number of adversarial patches. Moreover, we demonstrate physical flights with two robots, where we employ a novel attack policy that uses the computed adversarial patches to kidnap a robot that was supposed to follow a human.
Flying Adversarial Patches: Manipulating the Behavior of Deep Learning-based Autonomous Multirotors
May 22, 2023Autonomous flying robots, e.g. multirotors, often rely on a neural network that makes predictions based on a camera image. These deep learning (DL) models can compute surprising results if applied to input images outside the training domain. Adversarial attacks exploit this fault, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where an image is mounted on another flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. For an effective attack, we compare three methods that simultaneously optimize the adversarial patch and its position in the input image. We perform an empirical validation on a publicly available DL model and dataset for autonomous multirotors. Ultimately, our attacking multirotor would be able to gain full control over the motions of the victim multirotor.
Learning Electron Bunch Distribution along a FEL Beamline by Normalising Flows
Feb 27, 2023Understanding and control of Laser-driven Free Electron Lasers remain to be difficult problems that require highly intensive experimental and theoretical research. The gap between simulated and experimentally collected data might complicate studies and interpretation of obtained results. In this work we developed a deep learning based surrogate that could help to fill in this gap. We introduce a surrogate model based on normalising flows for conditional phase-space representation of electron clouds in a FEL beamline. Achieved results let us discuss further benefits and limitations in exploitability of the models to gain deeper understanding of fundamental processes within a beamline.
* 7 pages, 5 figures
Continual learning autoencoder training for a particle-in-cell simulation via streaming
Nov 09, 2022
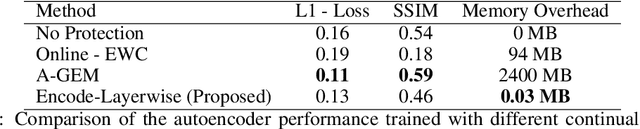

The upcoming exascale era will provide a new generation of physics simulations. These simulations will have a high spatiotemporal resolution, which will impact the training of machine learning models since storing a high amount of simulation data on disk is nearly impossible. Therefore, we need to rethink the training of machine learning models for simulations for the upcoming exascale era. This work presents an approach that trains a neural network concurrently to a running simulation without storing data on a disk. The training pipeline accesses the training data by in-memory streaming. Furthermore, we apply methods from the domain of continual learning to enhance the generalization of the model. We tested our pipeline on the training of a 3d autoencoder trained concurrently to laser wakefield acceleration particle-in-cell simulation. Furthermore, we experimented with various continual learning methods and their effect on the generalization.
InFlow: Robust outlier detection utilizing Normalizing Flows
Jun 10, 2021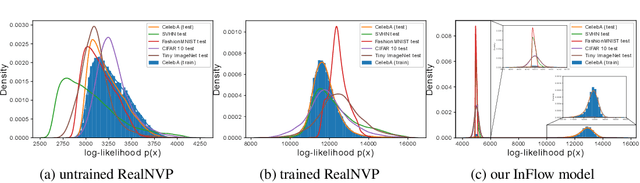
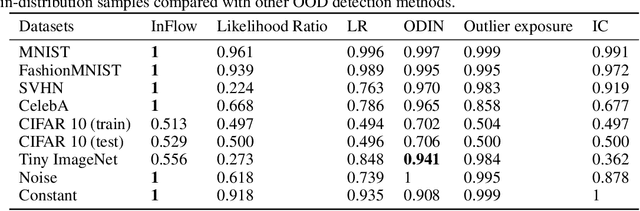
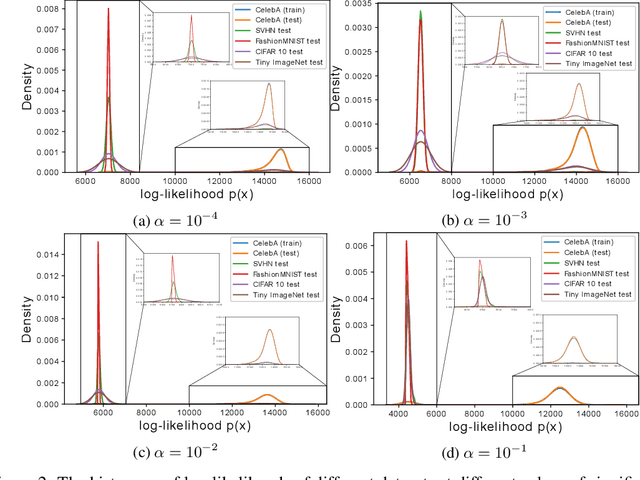
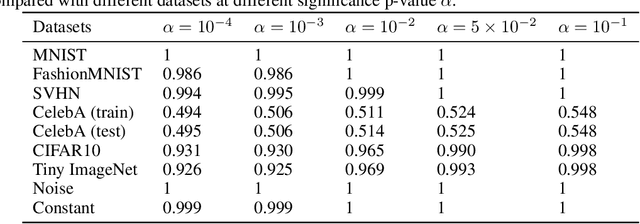
Normalizing flows are prominent deep generative models that provide tractable probability distributions and efficient density estimation. However, they are well known to fail while detecting Out-of-Distribution (OOD) inputs as they directly encode the local features of the input representations in their latent space. In this paper, we solve this overconfidence issue of normalizing flows by demonstrating that flows, if extended by an attention mechanism, can reliably detect outliers including adversarial attacks. Our approach does not require outlier data for training and we showcase the efficiency of our method for OOD detection by reporting state-of-the-art performance in diverse experimental settings. Code available at https://github.com/ComputationalRadiationPhysics/InFlow .
Invertible Surrogate Models: Joint surrogate modelling and reconstruction of Laser-Wakefield Acceleration by invertible neural networks
Jun 01, 2021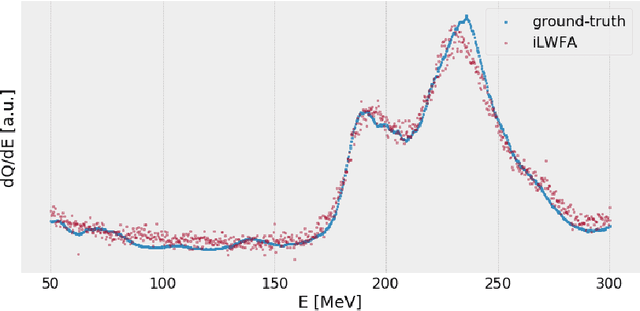
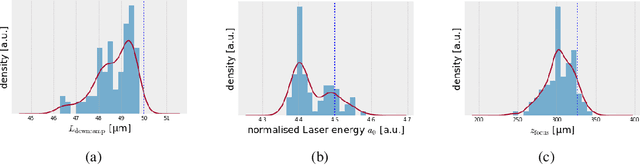
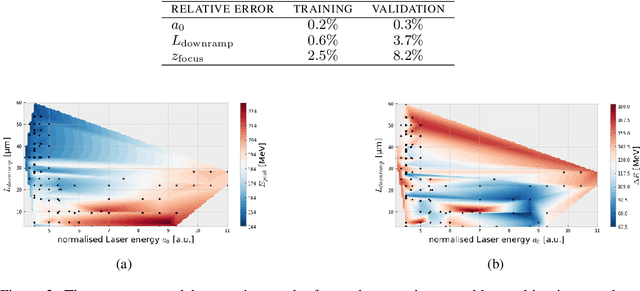
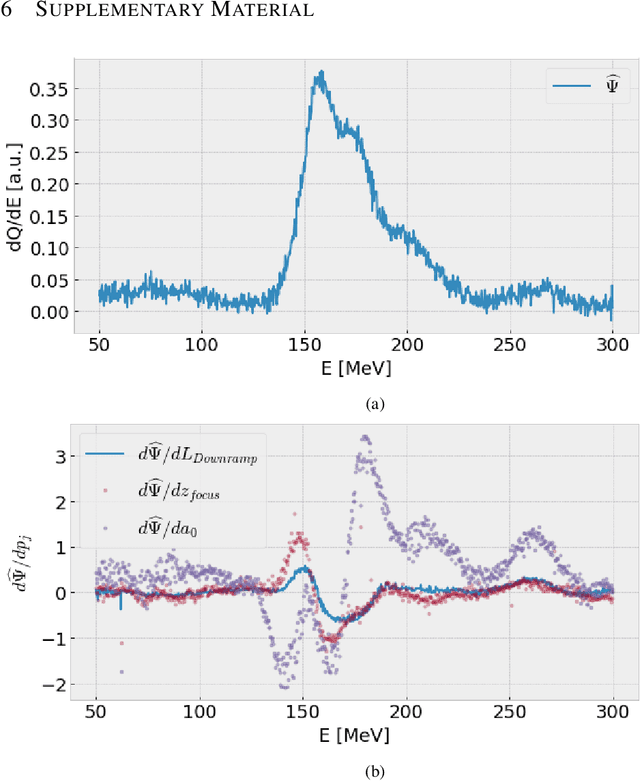
Invertible neural networks are a recent technique in machine learning promising neural network architectures that can be run in forward and reverse mode. In this paper, we will be introducing invertible surrogate models that approximate complex forward simulation of the physics involved in laser plasma accelerators: iLWFA. The bijective design of the surrogate model also provides all means for reconstruction of experimentally acquired diagnostics. The quality of our invertible laser wakefield acceleration network will be verified on a large set of numerical LWFA simulations.
Data-Driven Shadowgraph Simulation of a 3D Object
Jun 01, 2021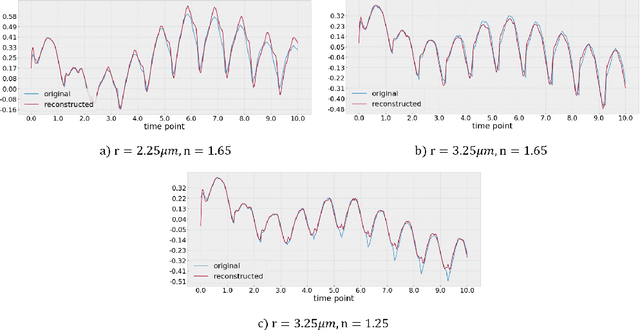
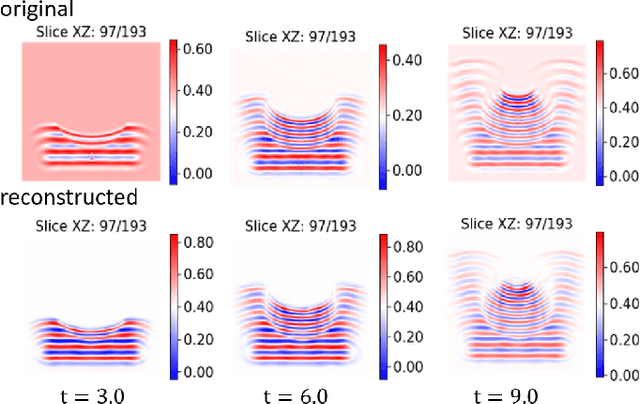
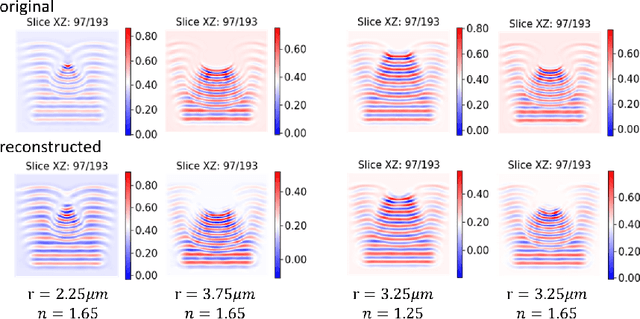
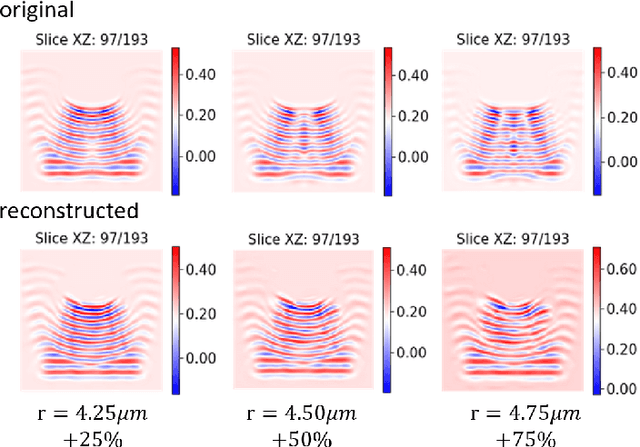
In this work we propose a deep neural network based surrogate model for a plasma shadowgraph - a technique for visualization of perturbations in a transparent medium. We are substituting the numerical code by a computationally cheaper projection based surrogate model that is able to approximate the electric fields at a given time without computing all preceding electric fields as required by numerical methods. This means that the projection based surrogate model allows to recover the solution of the governing 3D partial differential equation, 3D wave equation, at any point of a given compute domain and configuration without the need to run a full simulation. This model has shown a good quality of reconstruction in a problem of interpolation of data within a narrow range of simulation parameters and can be used for input data of large size.