 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionINN: Invertible Image Fusion for Brain Tumor Monitoring
Apr 02, 2024Image fusion typically employs non-invertible neural networks to merge multiple source images into a single fused image. However, for clinical experts, solely relying on fused images may be insufficient for making diagnostic decisions, as the fusion mechanism blends features from source images, thereby making it difficult to interpret the underlying tumor pathology. We introduce FusionINN, a novel invertible image fusion framework, capable of efficiently generating fused images and also decomposing them back to the source images by solving the inverse of the fusion process. FusionINN guarantees lossless one-to-one pixel mapping by integrating a normally distributed latent image alongside the fused image to facilitate the generative modeling of the decomposition process. To the best of our knowledge, we are the first to investigate the decomposability of fused images, which is particularly crucial for life-sensitive applications such as medical image fusion compared to other tasks like multi-focus or multi-exposure image fusion. Our extensive experimentation validates FusionINN over existing discriminative and generative fusion methods, both subjectively and objectively. Moreover, compared to a recent denoising diffusion-based fusion model, our approach offers faster and qualitatively better fusion results. We also exhibit the clinical utility of our results in aiding disease prognosis.
Learning to reconstruct the bubble distribution with conductivity maps using Invertible Neural Networks and Error Diffusion
Jul 04, 2023Electrolysis is crucial for eco-friendly hydrogen production, but gas bubbles generated during the process hinder reactions, reduce cell efficiency, and increase energy consumption. Additionally, these gas bubbles cause changes in the conductivity inside the cell, resulting in corresponding variations in the induced magnetic field around the cell. Therefore, measuring these gas bubble-induced magnetic field fluctuations using external magnetic sensors and solving the inverse problem of Biot-Savart Law allows for estimating the conductivity in the cell and, thus, bubble size and location. However, determining high-resolution conductivity maps from only a few induced magnetic field measurements is an ill-posed inverse problem. To overcome this, we exploit Invertible Neural Networks (INNs) to reconstruct the conductivity field. Our qualitative results and quantitative evaluation using random error diffusion show that INN achieves far superior performance compared to Tikhonov regularization.
Computational Performance Aware Benchmarking of Unsupervised Concept Drift Detection
Apr 17, 2023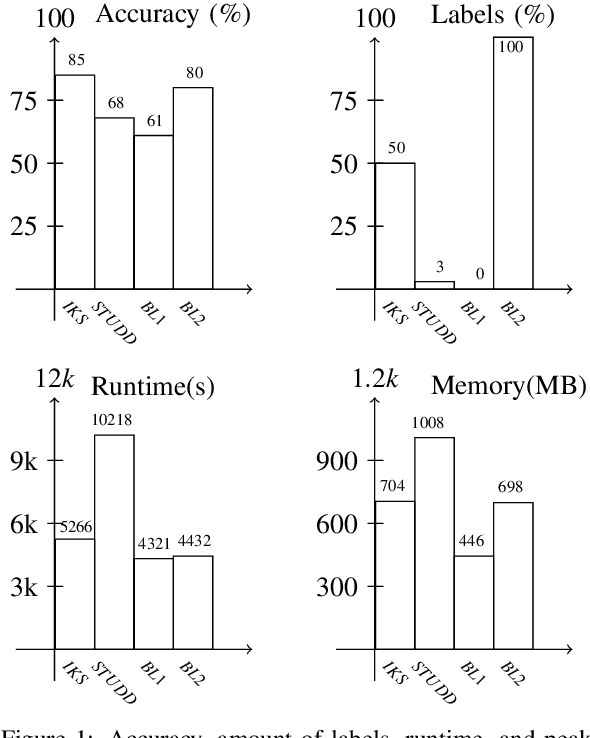
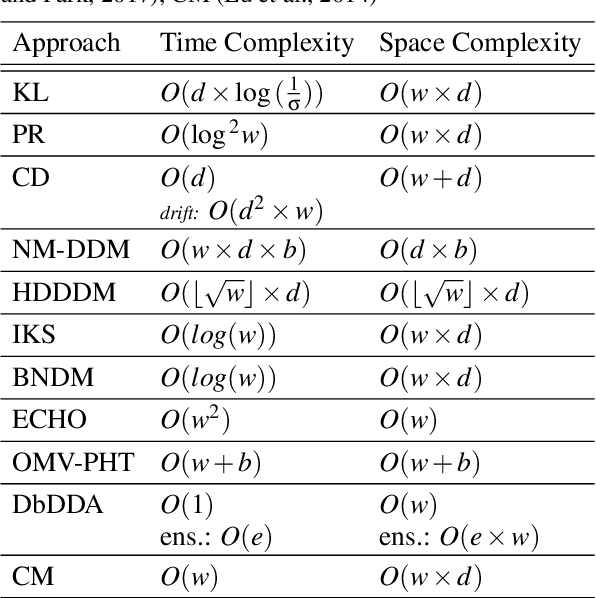
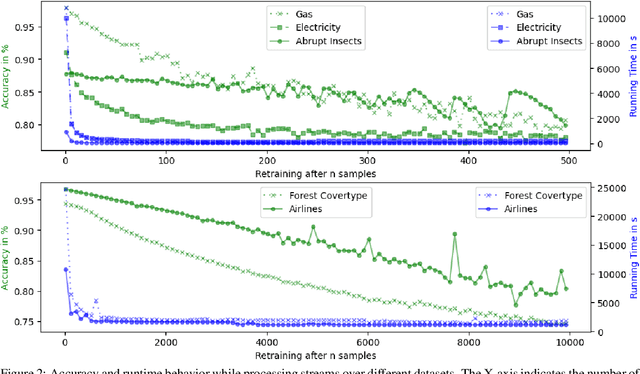
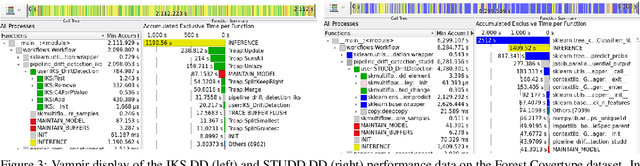
For many AI systems, concept drift detection is crucial to ensure the systems reliability. These systems often have to deal with large amounts of data or react in real time. Thus, drift detectors must meet computational requirements or constraints with a comprehensive performance evaluation. However, so far, the focus of developing drift detectors is on detection quality, e.g.~accuracy, but not on computational performance, such as running time. We show that the previous works consider computational performance only as a secondary objective and do not have a benchmark for such evaluation. Hence, we propose a novel benchmark suite for drift detectors that accounts both detection quality and computational performance to ensure a detector's applicability in various AI systems. In this work, we focus on unsupervised drift detectors that are not restricted to the availability of labeled data and thus being widely applicable. Our benchmark suite supports configurable synthetic and real world data streams. Moreover, it provides means for simulating a machine learning model's output to unify the performance evaluation across different drift detectors. This allows a fair and comprehensive comparison of drift detectors proposed in related work. Our benchmark suite is integrated in the existing framework, Massive Online Analysis (MOA). To evaluate our benchmark suite's capability, we integrate two representative unsupervised drift detectors. Our work enables the scientific community to achieve a baseline for unsupervised drift detectors with respect to both detection quality and computational performance.
Normalizing Flow based Feature Synthesis for Outlier-Aware Object Detection
Feb 01, 2023



Real-world deployment of reliable object detectors is crucial for applications such as autonomous driving. However, general-purpose object detectors like Faster R-CNN are prone to providing overconfident predictions for outlier objects. Recent outlier-aware object detection approaches estimate the density of instance-wide features with class-conditional Gaussians and train on synthesized outlier features from their low-likelihood regions. However, this strategy does not guarantee that the synthesized outlier features will have a low likelihood according to the other class-conditional Gaussians. We propose a novel outlier-aware object detection framework that learns to distinguish outliers from inlier objects by learning the joint data distribution of all inlier classes with an invertible normalizing flow. The flow model ensures that the synthesized outliers have a lower likelihood than inliers of all object classes, thereby modeling a better decision boundary between inlier and outlier objects. Our approach significantly outperforms the state-of-the-art for outlier-aware object detection on both image and video datasets.
Challenging the Universal Representation of Deep Models for 3D Point Cloud Registration
Nov 29, 2022



Learning universal representations across different applications domain is an open research problem. In fact, finding universal architecture within the same application but across different types of datasets is still unsolved problem too, especially in applications involving processing 3D point clouds. In this work we experimentally test several state-of-the-art learning-based methods for 3D point cloud registration against the proposed non-learning baseline registration method. The proposed method either outperforms or achieves comparable results w.r.t. learning based methods. In addition, we propose a dataset on which learning based methods have a hard time to generalize. Our proposed method and dataset, along with the provided experiments, can be used in further research in studying effective solutions for universal representations. Our source code is available at: github.com/DavidBoja/greedy-grid-search.
Enhancing Fairness of Visual Attribute Predictors
Jul 14, 2022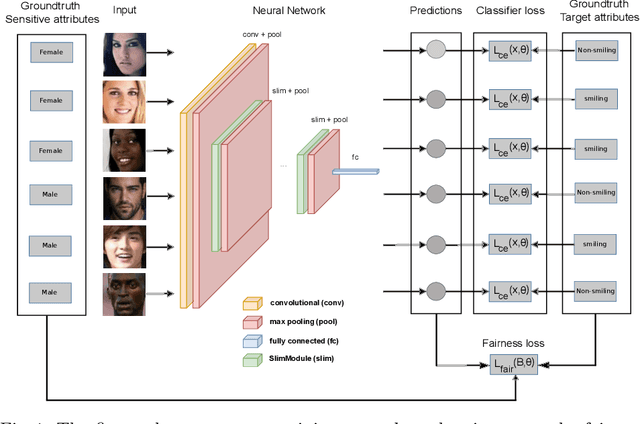
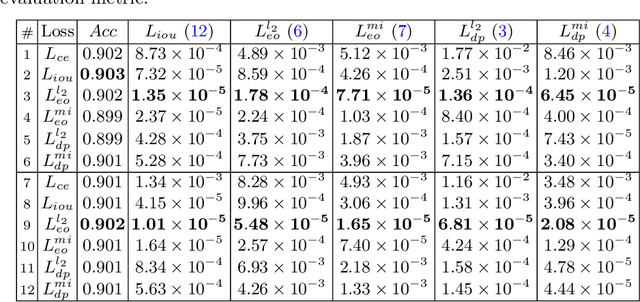
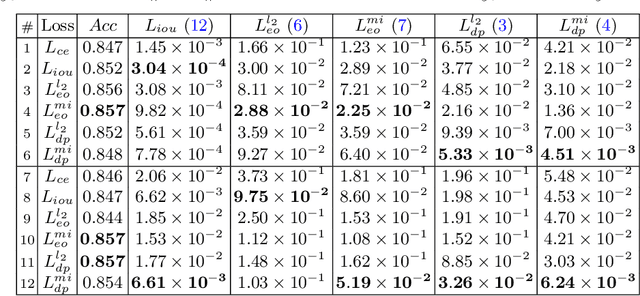
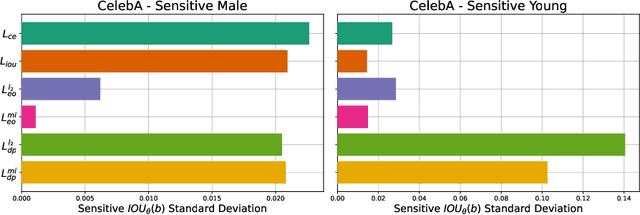
The performance of deep neural networks for image recognition tasks such as predicting a smiling face is known to degrade with under-represented classes of sensitive attributes. We address this problem by introducing fairness-aware regularization losses based on batch estimates of Demographic Parity, Equalized Odds, and a novel Intersection-over-Union measure. The experiments performed on facial and medical images from CelebA, UTKFace, and the SIIM-ISIC melanoma classification challenge show the effectiveness of our proposed fairness losses for bias mitigation as they improve model fairness while maintaining high classification performance. To the best of our knowledge, our work is the first attempt to incorporate these types of losses in an end-to-end training scheme for mitigating biases of visual attribute predictors. Our code is available at https://github.com/nish03/FVAP.
InFlow: Robust outlier detection utilizing Normalizing Flows
Jun 10, 2021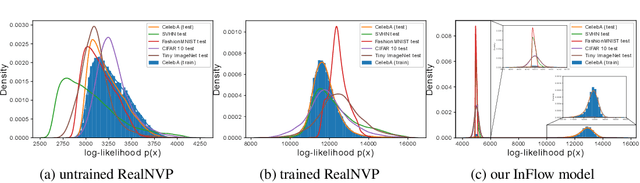
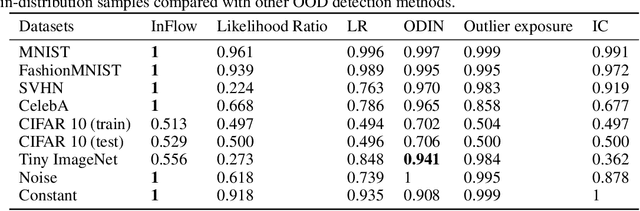
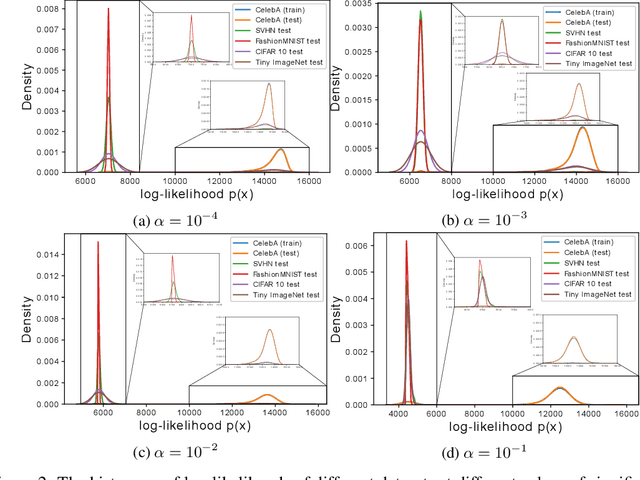
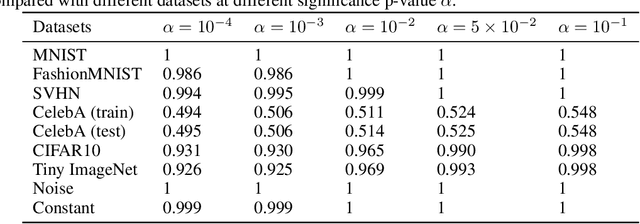
Normalizing flows are prominent deep generative models that provide tractable probability distributions and efficient density estimation. However, they are well known to fail while detecting Out-of-Distribution (OOD) inputs as they directly encode the local features of the input representations in their latent space. In this paper, we solve this overconfidence issue of normalizing flows by demonstrating that flows, if extended by an attention mechanism, can reliably detect outliers including adversarial attacks. Our approach does not require outlier data for training and we showcase the efficiency of our method for OOD detection by reporting state-of-the-art performance in diverse experimental settings. Code available at https://github.com/ComputationalRadiationPhysics/InFlow .
FuseVis: Interpreting neural networks for image fusion using per-pixel saliency visualization
Dec 06, 2020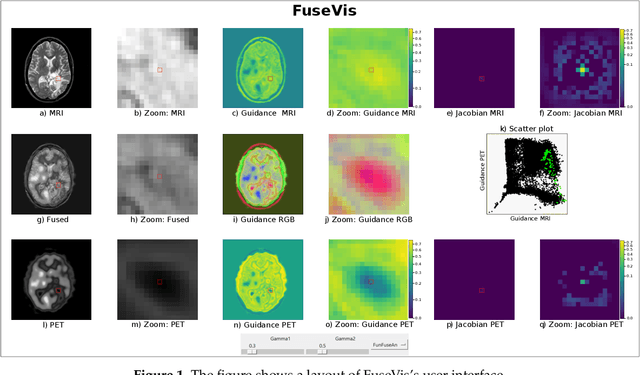

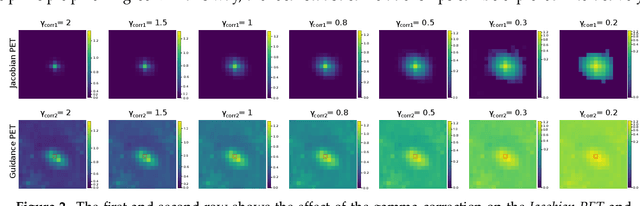

Image fusion helps in merging two or more images to construct a more informative single fused image. Recently, unsupervised learning based convolutional neural networks (CNN) have been utilized for different types of image fusion tasks such as medical image fusion, infrared-visible image fusion for autonomous driving as well as multi-focus and multi-exposure image fusion for satellite imagery. However, it is challenging to analyze the reliability of these CNNs for the image fusion tasks since no groundtruth is available. This led to the use of a wide variety of model architectures and optimization functions yielding quite different fusion results. Additionally, due to the highly opaque nature of such neural networks, it is difficult to explain the internal mechanics behind its fusion results. To overcome these challenges, we present a novel real-time visualization tool, named FuseVis, with which the end-user can compute per-pixel saliency maps that examine the influence of the input image pixels on each pixel of the fused image. We trained several image fusion based CNNs on medical image pairs and then using our FuseVis tool, we performed case studies on a specific clinical application by interpreting the saliency maps from each of the fusion methods. We specifically visualized the relative influence of each input image on the predictions of the fused image and showed that some of the evaluated image fusion methods are better suited for the specific clinical application. To the best of our knowledge, currently, there is no approach for visual analysis of neural networks for image fusion. Therefore, this work opens up a new research direction to improve the interpretability of deep fusion networks. The FuseVis tool can also be adapted in other deep neural network based image processing applications to make them interpretable.
Visualisation of Medical Image Fusion and Translation for Accurate Diagnosis of High Grade Gliomas
Jan 30, 2020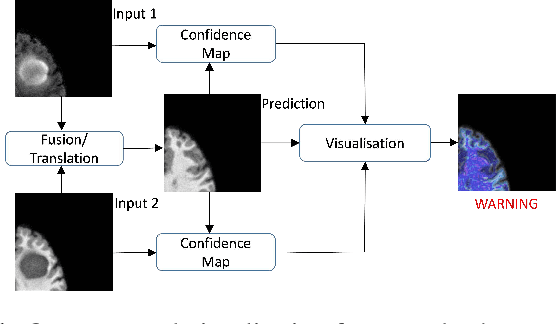
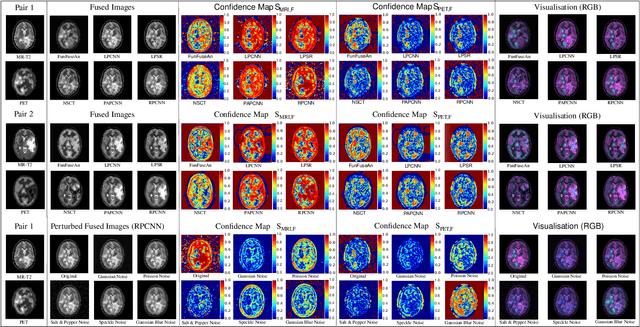
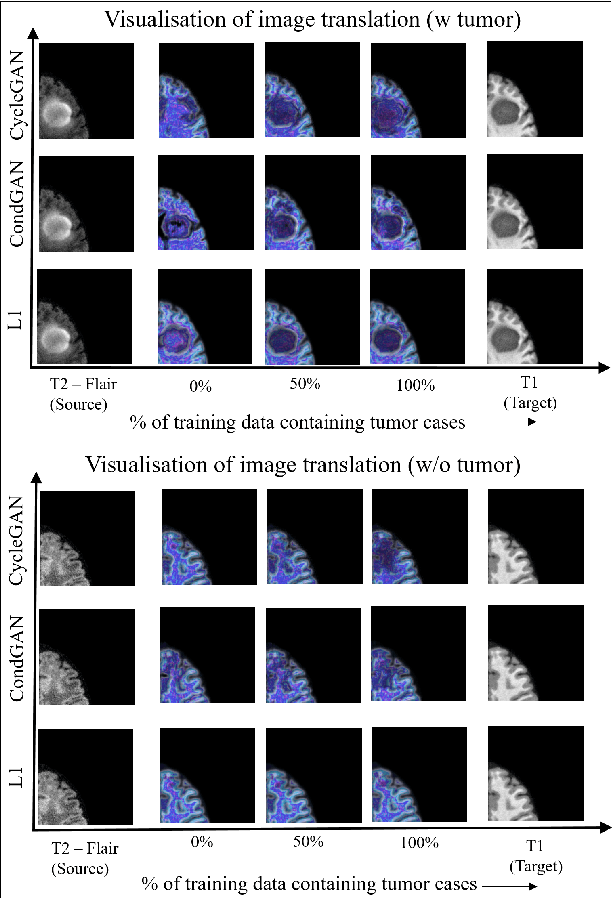
The medical image fusion combines two or more modalities into a single view while medical image translation synthesizes new images and assists in data augmentation. Together, these methods help in faster diagnosis of high grade malignant gliomas. However, they might be untrustworthy due to which neurosurgeons demand a robust visualisation tool to verify the reliability of the fusion and translation results before they make pre-operative surgical decisions. In this paper, we propose a novel approach to compute a confidence heat map between the source-target image pair by estimating the information transfer from the source to the target image using the joint probability distribution of the two images. We evaluate several fusion and translation methods using our visualisation procedure and showcase its robustness in enabling neurosurgeons to make finer clinical decisions.
Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task
Dec 02, 2019
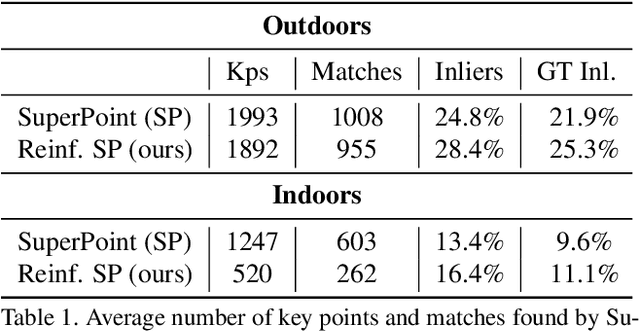
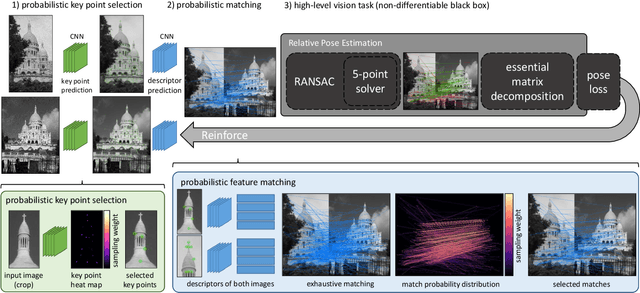
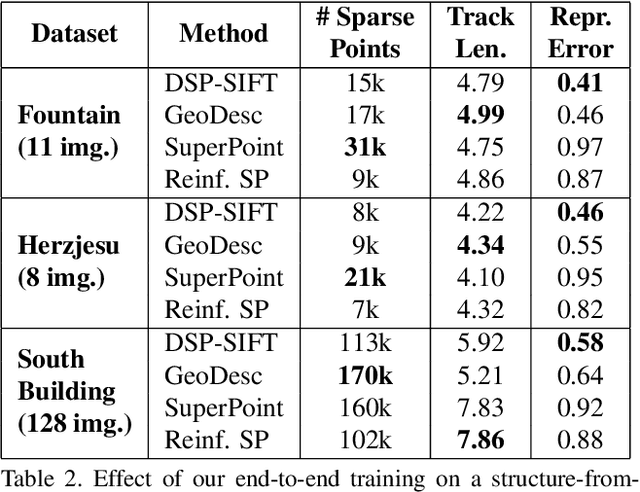
We address a core problem of computer vision: Detection and description of 2D feature points for image matching. For a long time, hand-crafted designs, like the seminal SIFT algorithm, were unsurpassed in accuracy and efficiency. Recently, learned feature detectors emerged that implement detection and description using neural networks. Training these networks usually resorts to optimizing low-level matching scores, often pre-defining sets of image patches which should or should not match, or which should or should not contain key points. Unfortunately, increased accuracy for these low-level matching scores does not necessarily translate to better performance in high-level vision tasks. We propose a new training methodology which embeds the feature detector in a complete vision pipeline, and where the learnable parameters are trained in an end-to-end fashion. We overcome the discrete nature of key point selection and descriptor matching using principles from reinforcement learning. As an example, we address the task of relative pose estimation between a pair of images. We demonstrate that the accuracy of a state-of-the-art learning-based feature detector can be increased when trained for the task it is supposed to solve at test time. Our training methodology poses little restrictions on the task to learn, and works for any architecture which predicts key point heat maps, and descriptors for key point locations.