 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-independent 3D Anthropometry from Sparse Data
Jan 10, 2025
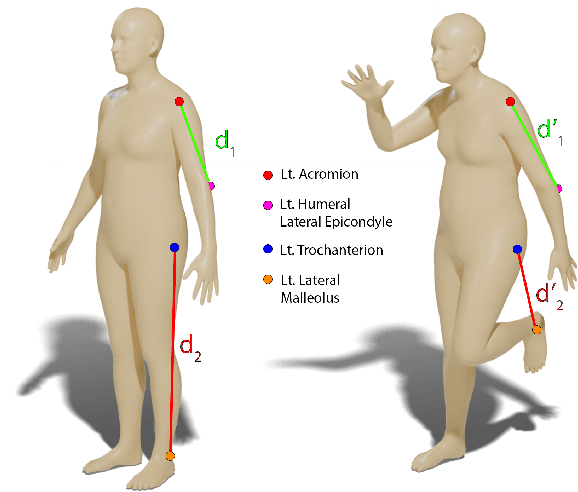


3D digital anthropometry is the study of estimating human body measurements from 3D scans. Precise body measurements are important health indicators in the medical industry, and guiding factors in the fashion, ergonomic and entertainment industries. The measuring protocol consists of scanning the whole subject in the static A-pose, which is maintained without breathing or movement during the scanning process. However, the A-pose is not easy to maintain during the whole scanning process, which can last even up to a couple of minutes. This constraint affects the final quality of the scan, which in turn affects the accuracy of the estimated body measurements obtained from methods that rely on dense geometric data. Additionally, this constraint makes it impossible to develop a digital anthropometry method for subjects unable to assume the A-pose, such as those with injuries or disabilities. We propose a method that can obtain body measurements from sparse landmarks acquired in any pose. We make use of the sparse landmarks of the posed subject to create pose-independent features, and train a network to predict the body measurements as taken from the standard A-pose. We show that our method achieves comparable results to competing methods that use dense geometry in the standard A-pose, but has the capability of estimating the body measurements from any pose using sparse landmarks only. Finally, we address the lack of open-source 3D anthropometry methods by making our method available to the research community at https://github.com/DavidBoja/pose-independent-anthropometry.
Challenging the Universal Representation of Deep Models for 3D Point Cloud Registration
Nov 29, 2022



Learning universal representations across different applications domain is an open research problem. In fact, finding universal architecture within the same application but across different types of datasets is still unsolved problem too, especially in applications involving processing 3D point clouds. In this work we experimentally test several state-of-the-art learning-based methods for 3D point cloud registration against the proposed non-learning baseline registration method. The proposed method either outperforms or achieves comparable results w.r.t. learning based methods. In addition, we propose a dataset on which learning based methods have a hard time to generalize. Our proposed method and dataset, along with the provided experiments, can be used in further research in studying effective solutions for universal representations. Our source code is available at: github.com/DavidBoja/greedy-grid-search.
Stochastic Modeling for Learnable Human Pose Triangulation
Oct 01, 2021
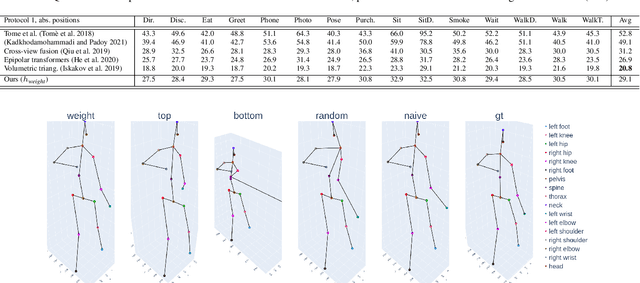
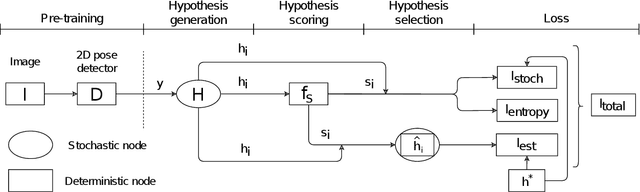
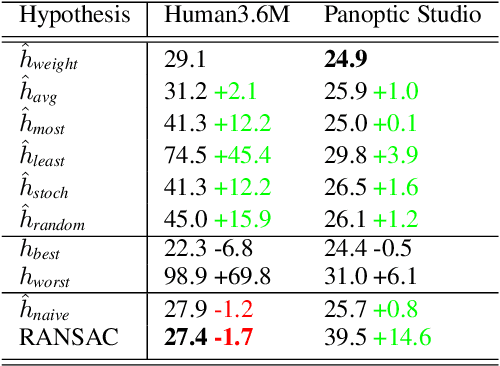
We propose a stochastic modeling framework for 3D human pose triangulation and evaluate its performance across different datasets and spatial camera arrangements. The common approach to 3D pose estimation is to first detect 2D keypoints in images and then apply the triangulation from multiple views. However, the majority of existing triangulation models are limited to a single dataset, i.e. camera arrangement and their number. Moreover, they require known camera parameters. The proposed stochastic pose triangulation model successfully generalizes to different camera arrangements and between two public datasets. In each step, we generate a set of 3D pose hypotheses obtained by triangulation from a random subset of views. The hypotheses are evaluated by a neural network and the expectation of the triangulation error is minimized. The key novelty is that the network learns to evaluate the poses without taking into account the spatial camera arrangement, thus improving generalization. Additionally, we demonstrate that the proposed stochastic framework can also be used for fundamental matrix estimation, showing promising results towards relative camera pose estimation from noisy keypoint correspondences.
Catadioptric Stereo on a Smartphone
Sep 24, 2021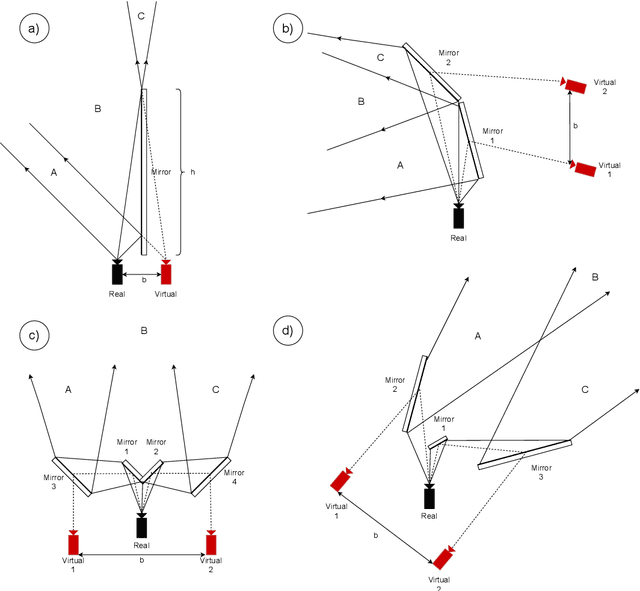
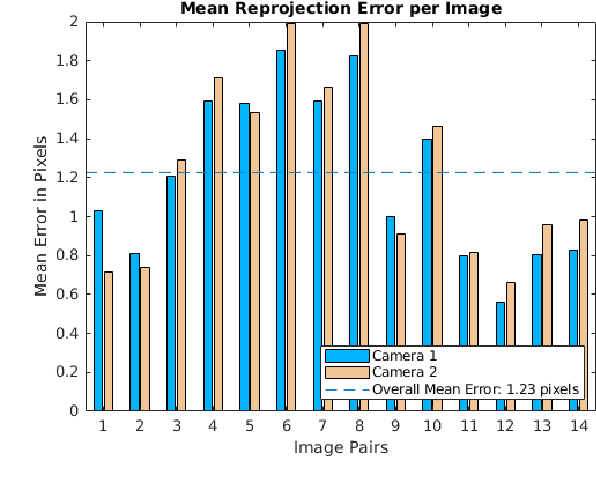

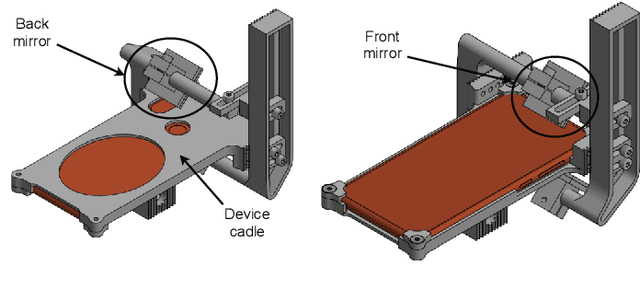
We present a 3D printed adapter with planar mirrors for stereo reconstruction using front and back smartphone camera. The adapter presents a practical and low-cost solution for enabling any smartphone to be used as a stereo camera, which is currently only possible using high-end phones with expensive 3D sensors. Using the prototype version of the adapter, we experiment with parameters like the angles between cameras and mirrors and the distance to each camera (the stereo baseline). We find the most convenient configuration and calibrate the stereo pair. Based on the presented preliminary analysis, we identify possible improvements in the current design. To demonstrate the working prototype, we reconstruct a 3D human pose using 2D keypoint detections from the stereo pair and evaluate extracted body lengths. The result shows that the adapter can be used for anthropometric measurement of several body segments.
Ensemble of LSTMs and feature selection for human action prediction
Jan 14, 2021
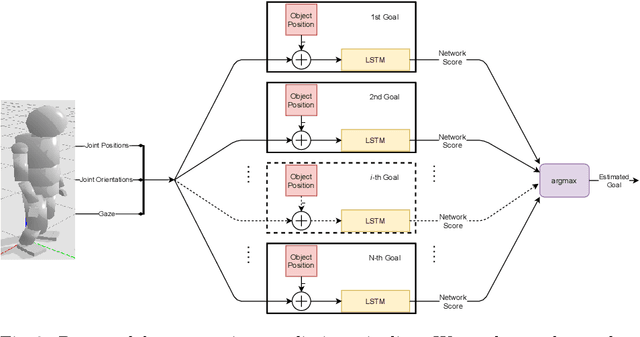
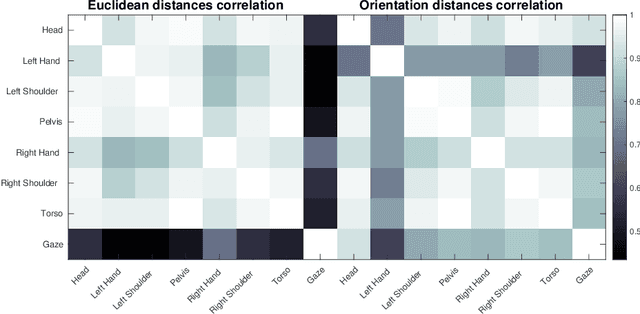
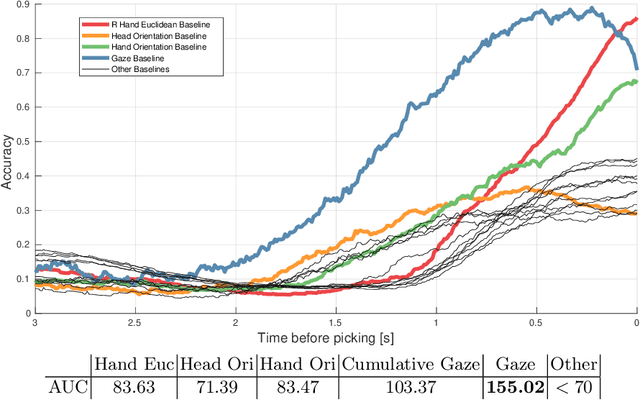
As robots are becoming more and more ubiquitous in human environments, it will be necessary for robotic systems to better understand and predict human actions. However, this is not an easy task, at times not even for us humans, but based on a relatively structured set of possible actions, appropriate cues, and the right model, this problem can be computationally tackled. In this paper, we propose to use an ensemble of long-short term memory (LSTM) networks for human action prediction. To train and evaluate models, we used the MoGaze dataset - currently the most comprehensive dataset capturing poses of human joints and the human gaze. We have thoroughly analyzed the MoGaze dataset and selected a reduced set of cues for this task. Our model can predict (i) which of the labeled objects the human is going to grasp, and (ii) which of the macro locations the human is going to visit (such as table or shelf). We have exhaustively evaluated the proposed method and compared it to individual cue baselines. The results suggest that our LSTM model slightly outperforms the gaze baseline in single object picking accuracy, but achieves better accuracy in macro object prediction. Furthermore, we have also analyzed the prediction accuracy when the gaze is not used, and in this case, the LSTM model considerably outperformed the best single cue baseline
On the Comparison of Classic and Deep Keypoint Detector and Descriptor Methods
Jul 29, 2020
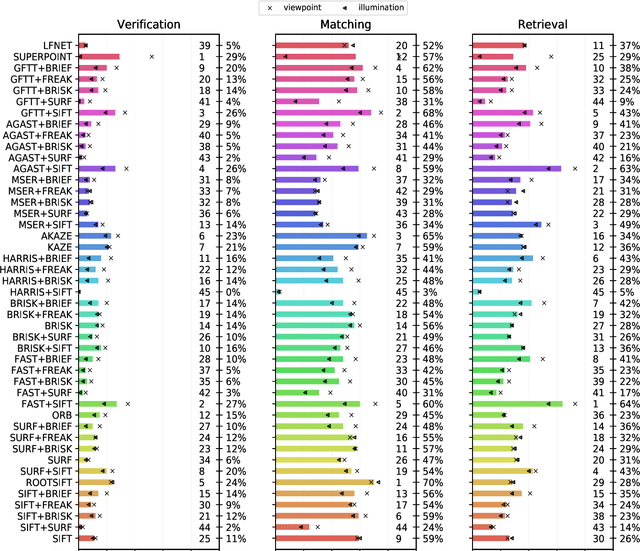
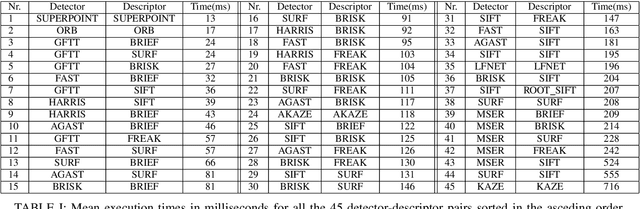
The purpose of this study is to give a performance comparison between several classic hand-crafted and deep key-point detector and descriptor methods. In particular, we consider the following classical algorithms: SIFT, SURF, ORB, FAST, BRISK, MSER, HARRIS, KAZE, AKAZE, AGAST, GFTT, FREAK, BRIEF and RootSIFT, where a subset of all combinations is paired into detector-descriptor pipelines. Additionally, we analyze the performance of two recent and perspective deep detector-descriptor models, LF-Net and SuperPoint. Our benchmark relies on the HPSequences dataset that provides real and diverse images under various geometric and illumination changes. We analyze the performance on three evaluation tasks: keypoint verification, image matching and keypoint retrieval. The results show that certain classic and deep approaches are still comparable, with some classic detector-descriptor combinations overperforming pretrained deep models. In terms of the execution times of tested implementations, SuperPoint model is the fastest, followed by ORB. The source code is published on \url{https://github.com/kristijanbartol/keypoint-algorithms-benchmark}.
Human Intention Recognition for Human Aware Planning in Integrated Warehouse Systems
May 22, 2020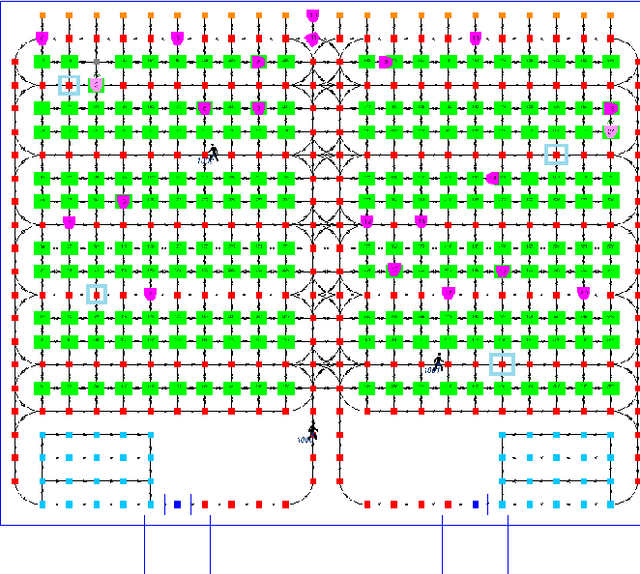
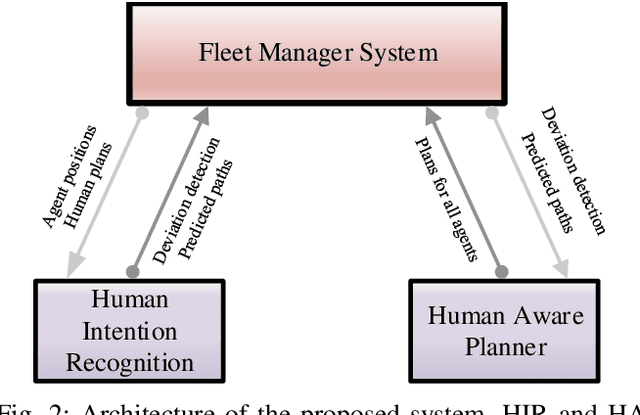
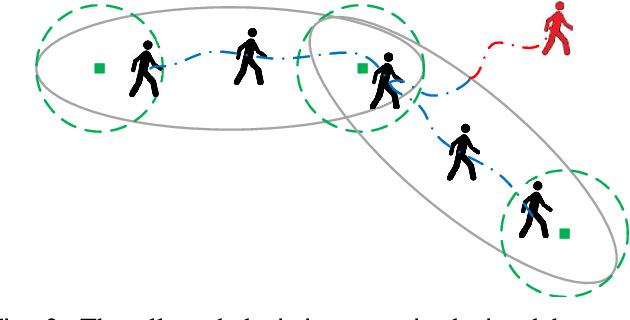
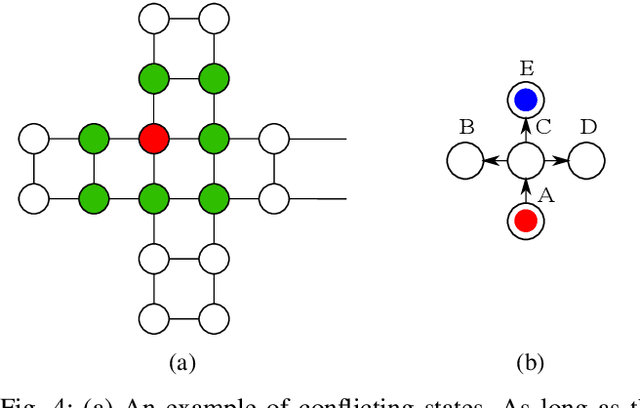
With the substantial growth of logistics businesses the need for larger and more automated warehouses increases, thus giving rise to fully robotized shop-floors with mobile robots in charge of transporting and distributing goods. However, even in fully automatized warehouse systems the need for human intervention frequently arises, whether because of maintenance or because of fulfilling specific orders, thus bringing mobile robots and humans ever closer in an integrated warehouse environment. In order to ensure smooth and efficient operation of such a warehouse, paths of both robots and humans need to be carefully planned; however, due to the possibility of humans deviating from the assigned path, this becomes an even more challenging task. Given that, the supervising system should be able to recognize human intentions and its alternative paths in real-time. In this paper, we propose a framework for human deviation detection and intention recognition which outputs the most probable paths of the humans workers and the planner that acts accordingly by replanning for robots to move out of the human's path. Experimental results demonstrate that the proposed framework increases total number of deliveries, especially human deliveries, and reduces human-robot encounters.
Human Intention Estimation based on Hidden Markov Model Motion Validation for Safe Flexible Robotized Warehouses
Nov 20, 2018

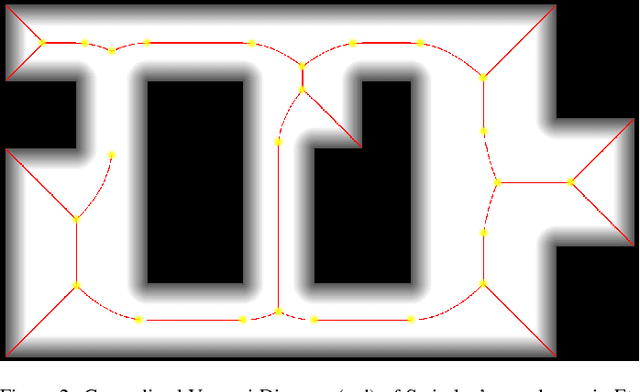
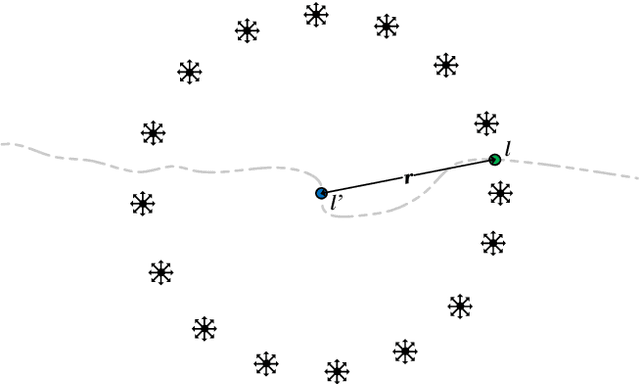
With the substantial growth of logistics businesses the need for larger warehouses and their automation arises, thus using robots as assistants to human workers is becoming a priority. In order to operate efficiently and safely, robot assistants or the supervising system should recognize human intentions in real-time. Theory of mind (ToM) is an intuitive human conception of other humans' mental state, i.e., beliefs and desires, and how they cause behavior. In this paper we propose a ToM based human intention estimation algorithm for flexible robotized warehouses. We observe human's, i.e., worker's motion and validate it with respect to the goal locations using generalized Voronoi diagram based path planning. These observations are then processed by the proposed hidden Markov model framework which estimates worker intentions in an online manner, capable of handling changing environments. To test the proposed intention estimation we ran experiments in a real-world laboratory warehouse with a worker wearing Microsoft Hololens augmented reality glasses. Furthermore, in order to demonstrate the scalability of the approach to larger warehouses, we propose to use virtual reality digital warehouse twins in order to realistically simulate worker behavior. We conducted intention estimation experiments in the larger warehouse digital twin with up to 24 running robots. We demonstrate that the proposed framework estimates warehouse worker intentions precisely and in the end we discuss the experimental results.
Human Intention Recognition in Flexible Robotized Warehouses based on Markov Decision Processes
Apr 05, 2018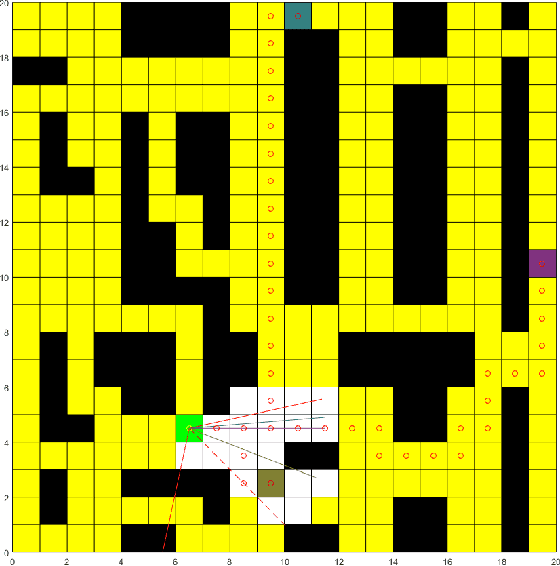
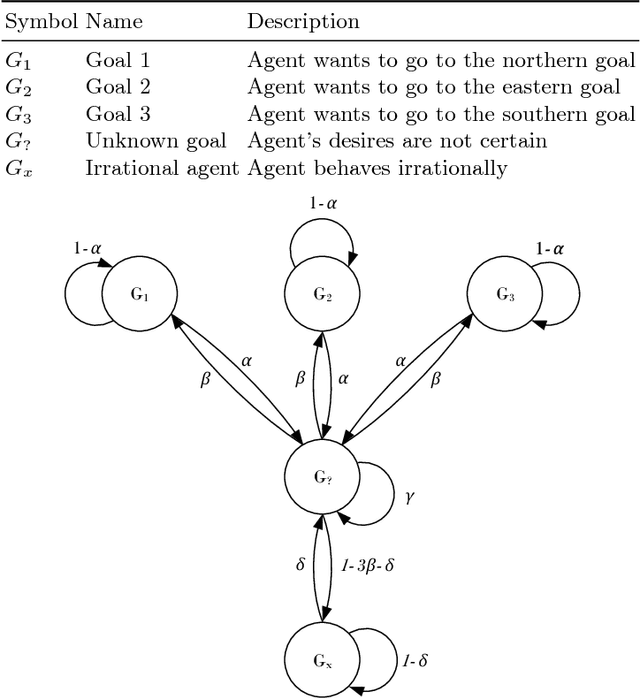
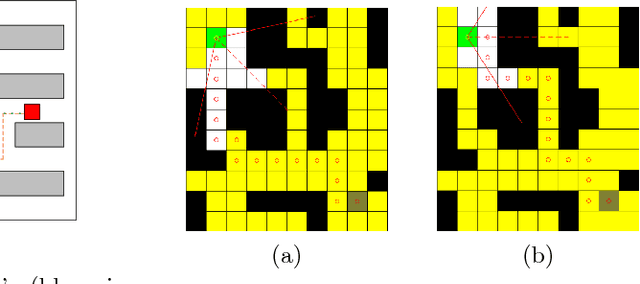
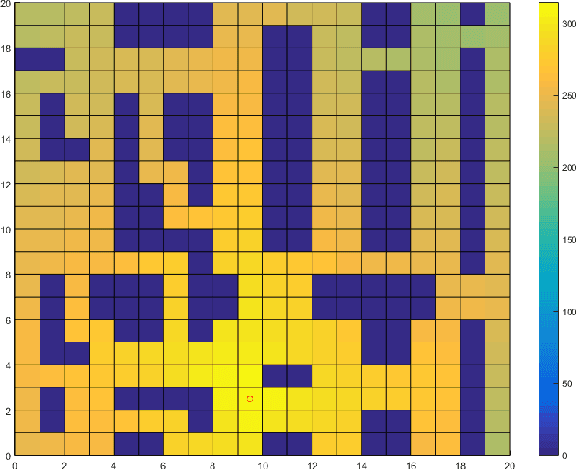
The rapid growth of e-commerce increases the need for larger warehouses and their automation, thus using robots as assistants to human workers becomes a priority. In order to operate efficiently and safely, robot assistants or the supervising system should recognize human intentions. Theory of mind (ToM) is an intuitive conception of other agents' mental state, i.e., beliefs and desires, and how they cause behavior. In this paper we present a ToM-based algorithm for human intention recognition in flexible robotized warehouses. We have placed the warehouse worker in a simulated 2D environment with three potential goals. We observe agent's actions and validate them with respect to the goal locations using a Markov decision process framework. Those observations are then processed by the proposed hidden Markov model framework which estimated agent's desires. We demonstrate that the proposed framework predicts human warehouse worker's desires in an intuitive manner and in the end we discuss the simulation results.
An Extension to Hough Transform Based on Gradient Orientation
Oct 16, 2015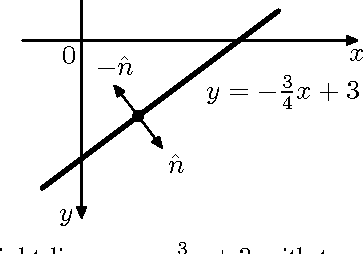
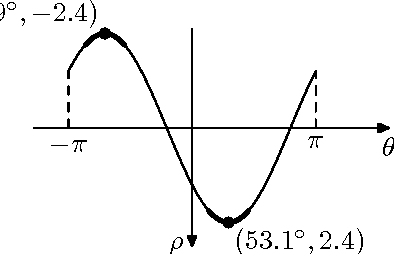
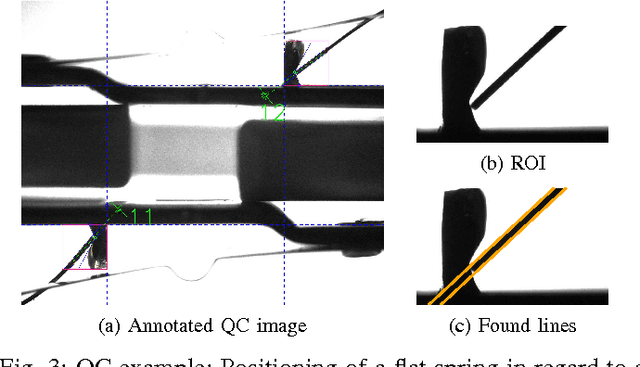
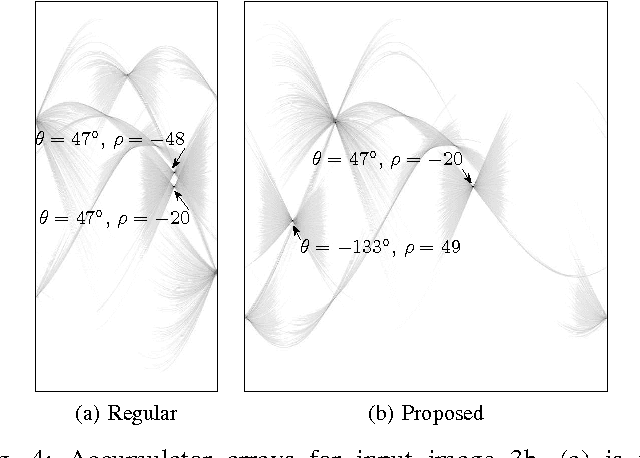
The Hough transform is one of the most common methods for line detection. In this paper we propose a novel extension of the regular Hough transform. The proposed extension combines the extension of the accumulator space and the local gradient orientation resulting in clutter reduction and yielding more prominent peaks, thus enabling better line identification. We demonstrate benefits in applications such as visual quality inspection and rectangle detection.