 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Heart Rejection Detection in XPCI Images Using Synthetic Data Augmentation
May 26, 2025Accurate identification of acute cellular rejection (ACR) in endomyocardial biopsies is essential for effective management of heart transplant patients. However, the rarity of high-grade rejection cases (3R) presents a significant challenge for training robust deep learning models. This work addresses the class imbalance problem by leveraging synthetic data generation using StyleGAN to augment the limited number of real 3R images. Prior to GAN training, histogram equalization was applied to standardize image appearance and improve the consistency of tissue representation. StyleGAN was trained on available 3R biopsy patches and subsequently used to generate 10,000 realistic synthetic images. These were combined with real 0R samples, that is samples without rejection, in various configurations to train ResNet-18 classifiers for binary rejection classification. Three classifier variants were evaluated: one trained on real 0R and synthetic 3R images, another using both synthetic and additional real samples, and a third trained solely on real data. All models were tested on an independent set of real biopsy images. Results demonstrate that synthetic data improves classification performance, particularly when used in combination with real samples. The highest-performing model, which used both real and synthetic images, achieved strong precision and recall for both classes. These findings underscore the value of hybrid training strategies and highlight the potential of GAN-based data augmentation in biomedical image analysis, especially in domains constrained by limited annotated datasets.
DHECA-SuperGaze: Dual Head-Eye Cross-Attention and Super-Resolution for Unconstrained Gaze Estimation
May 13, 2025Unconstrained gaze estimation is the process of determining where a subject is directing their visual attention in uncontrolled environments. Gaze estimation systems are important for a myriad of tasks such as driver distraction monitoring, exam proctoring, accessibility features in modern software, etc. However, these systems face challenges in real-world scenarios, partially due to the low resolution of in-the-wild images and partially due to insufficient modeling of head-eye interactions in current state-of-the-art (SOTA) methods. This paper introduces DHECA-SuperGaze, a deep learning-based method that advances gaze prediction through super-resolution (SR) and a dual head-eye cross-attention (DHECA) module. Our dual-branch convolutional backbone processes eye and multiscale SR head images, while the proposed DHECA module enables bidirectional feature refinement between the extracted visual features through cross-attention mechanisms. Furthermore, we identified critical annotation errors in one of the most diverse and widely used gaze estimation datasets, Gaze360, and rectified the mislabeled data. Performance evaluation on Gaze360 and GFIE datasets demonstrates superior within-dataset performance of the proposed method, reducing angular error (AE) by 0.48{\deg} (Gaze360) and 2.95{\deg} (GFIE) in static configurations, and 0.59{\deg} (Gaze360) and 3.00{\deg} (GFIE) in temporal settings compared to prior SOTA methods. Cross-dataset testing shows improvements in AE of more than 1.53{\deg} (Gaze360) and 3.99{\deg} (GFIE) in both static and temporal settings, validating the robust generalization properties of our approach.
A Survey on Deep Learning-based Gaze Direction Regression: Searching for the State-of-the-art
Oct 22, 2024In this paper, we present a survey of deep learning-based methods for the regression of gaze direction vector from head and eye images. We describe in detail numerous published methods with a focus on the input data, architecture of the model, and loss function used to supervise the model. Additionally, we present a list of datasets that can be used to train and evaluate gaze direction regression methods. Furthermore, we noticed that the results reported in the literature are often not comparable one to another due to differences in the validation or even test subsets used. To address this problem, we re-evaluated several methods on the commonly used in-the-wild Gaze360 dataset using the same validation setup. The experimental results show that the latest methods, although claiming state-of-the-art results, significantly underperform compared with some older methods. Finally, we show that the temporal models outperform the static models under static test conditions.
Illumination Estimation Challenge: experience of past two years
Dec 31, 2020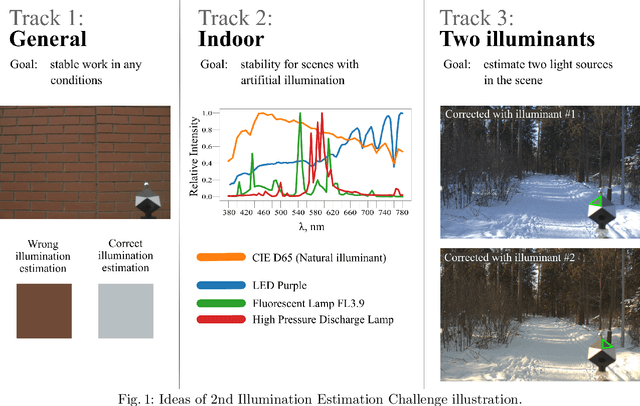
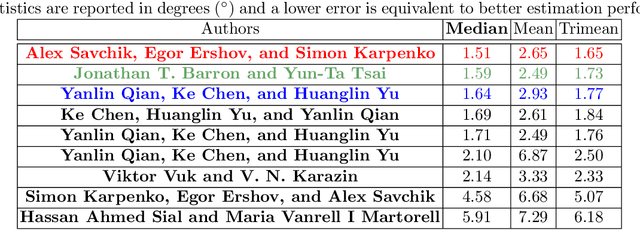

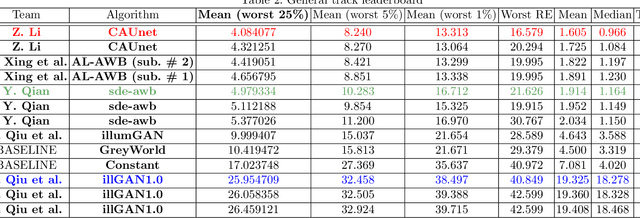
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.
The Cube++ Illumination Estimation Dataset
Nov 19, 2020
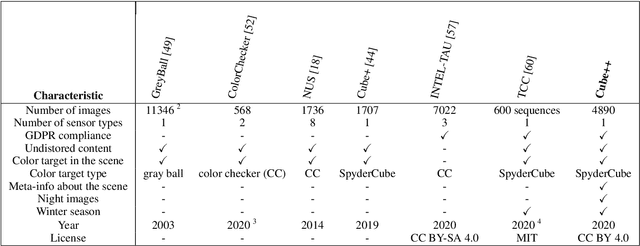

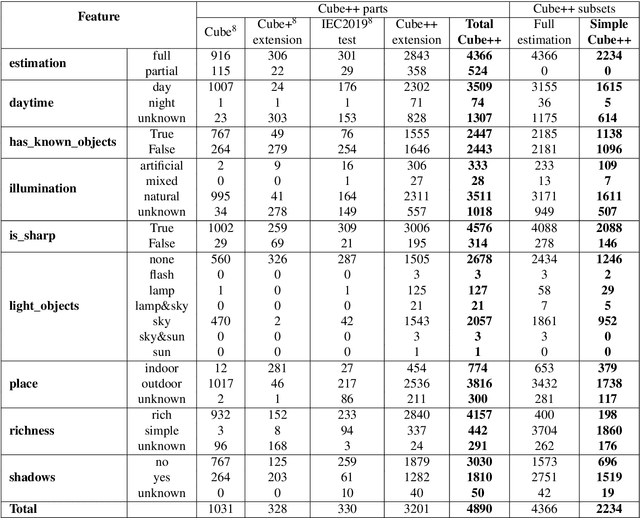
Computational color constancy has the important task of reducing the influence of the scene illumination on the object colors. As such, it is an essential part of the image processing pipelines of most digital cameras. One of the important parts of the computational color constancy is illumination estimation, i.e. estimating the illumination color. When an illumination estimation method is proposed, its accuracy is usually reported by providing the values of error metrics obtained on the images of publicly available datasets. However, over time it has been shown that many of these datasets have problems such as too few images, inappropriate image quality, lack of scene diversity, absence of version tracking, violation of various assumptions, GDPR regulation violation, lack of additional shooting procedure info, etc. In this paper, a new illumination estimation dataset is proposed that aims to alleviate many of the mentioned problems and to help the illumination estimation research. It consists of 4890 images with known illumination colors as well as with additional semantic data that can further make the learning process more accurate. Due to the usage of the SpyderCube color target, for every image there are two ground-truth illumination records covering different directions. Because of that, the dataset can be used for training and testing of methods that perform single or two-illuminant estimation. This makes it superior to many similar existing datasets. The datasets, it's smaller version SimpleCube++, and the accompanying code are available at https://github.com/Visillect/CubePlusPlus/.
Computational analysis of laminar structure of the human cortex based on local neuron features
May 03, 2019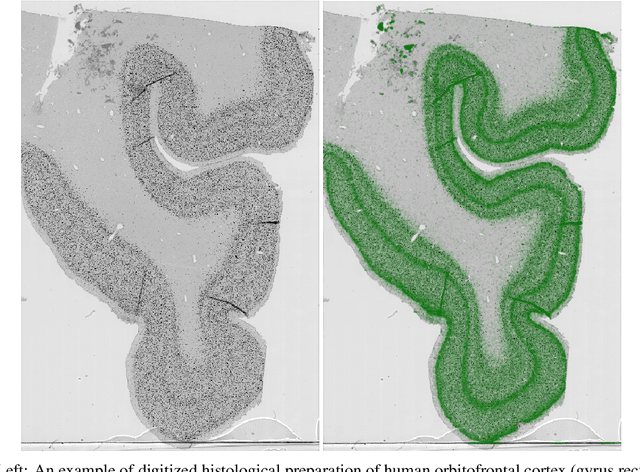



In this paper, we present a novel method for analysis and segmentation of laminar structure of the cortex based on tissue characteristics whose change across the gray matter facilitates distinction between cortical layers. We develop and analyze features of individual neurons to investigate changes in architectonic differentiation and present a novel high-performance, automated tree-ensemble method trained on data manually labeled by three human investigators. From the location and basic measures of neurons, more complex features are developed and used in machine learning models for automatic segmentation of cortical layers. Tree ensembles are used on data manually labeled by three human experts. The most accurate classification results were obtained by training three models separately and creating another ensemble by combining probability outputs for final neuron layer classification. Measurement of importances of developed neuron features on both global model level and individual prediction level are obtained.
CroP: Color Constancy Benchmark Dataset Generator
Mar 29, 2019
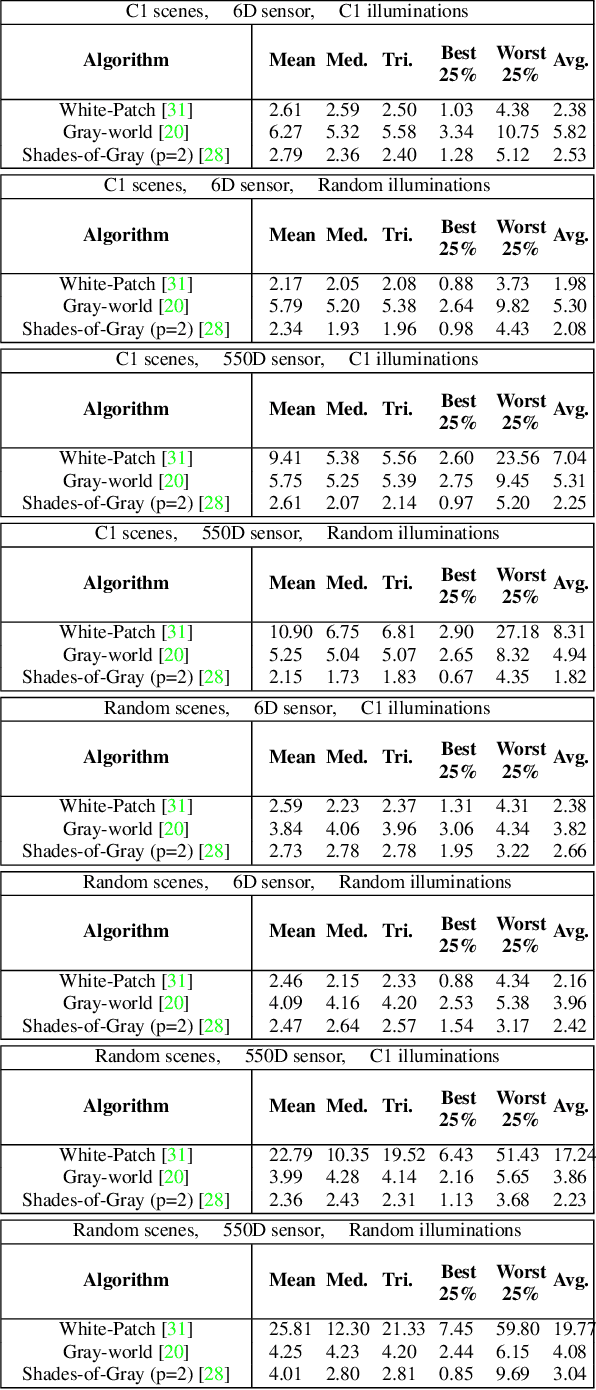
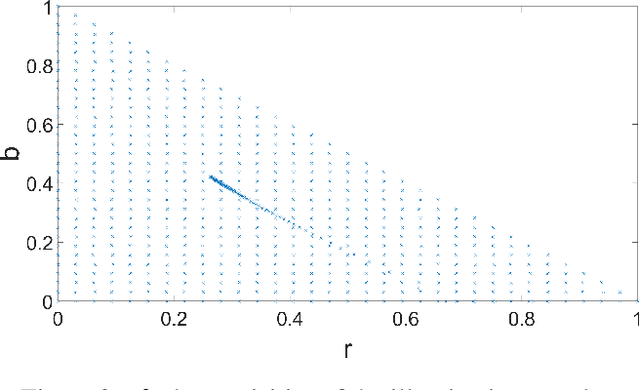
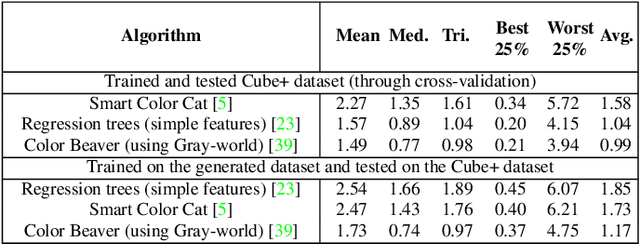
Implementing color constancy as a pre-processing step in contemporary digital cameras is of significant importance as it removes the influence of scene illumination on object colors. Several benchmark color constancy datasets have been created for the purpose of developing and testing new color constancy methods. However, they all have numerous drawbacks including a small number of images, erroneously extracted ground-truth illuminations, long histories of misuses, violations of their stated assumptions, etc. To overcome such and similar problems, in this paper a color constancy benchmark dataset generator is proposed. For a given camera sensor it enables generation of any number of realistic raw images taken in a subset of the real world, namely images of printed photographs. Datasets with such images share many positive features with other existing real-world datasets, while some of the negative features are completely eliminated. The generated images can be successfully used to train methods that afterward achieve high accuracy on real-world datasets. This opens the way for creating large enough datasets for advanced deep learning techniques. Experimental results are presented and discussed. The source code is available at http://www.fer.unizg.hr/ipg/resources/color_constancy/.
Automatic Detection of Neurons in NeuN-stained Histological Images of Human Brain
Jun 01, 2018



In this paper, we present a novel use of an anisotropic diffusion model for automatic detection of neurons in histological sections of the adult human brain cortex. We use a partial differential equation model to process high resolution images to acquire locations of neuronal bodies. We also present a novel approach in model training and evaluation that considers variability among the human experts, addressing the issue of existence and correctness of the golden standard for neuron and cell counting, used in most of relevant papers. Our method, trained on dataset manually labeled by three experts, has correctly distinguished over 95% of neuron bodies in test data, doing so in time much shorter than other comparable methods.
Unsupervised Learning for Color Constancy
Apr 20, 2018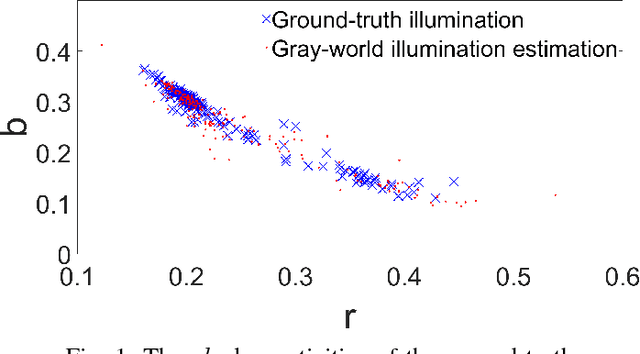

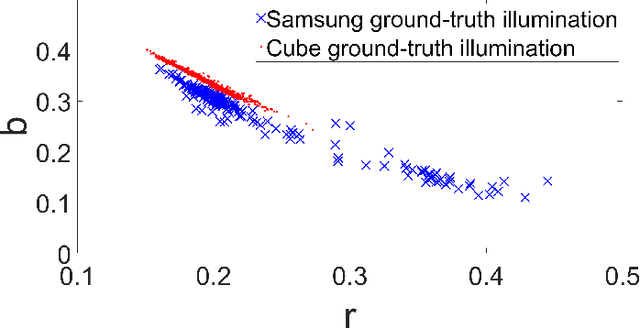

Most digital camera pipelines use color constancy methods to reduce the influence of illumination and camera sensor on the colors of scene objects. The highest accuracy of color correction is obtained with learning-based color constancy methods, but they require a significant amount of calibrated training images with known ground-truth illumination. Such calibration is time consuming, preferably done for each sensor individually, and therefore a major bottleneck in acquiring high color constancy accuracy. Statistics-based methods do not require calibrated training images, but they are less accurate. In this paper an unsupervised learning-based method is proposed that learns its parameter values after approximating the unknown ground-truth illumination of the training images, thus avoiding calibration. In terms of accuracy the proposed method outperforms all statistics-based and many learning-based methods. An extension of the method is also proposed, which learns the needed parameters from non-calibrated images taken with one sensors and which can then be successfully applied to images taken with another sensor. This effectively enables inter-camera unsupervised learning for color constancy. Additionally, a new high quality color constancy benchmark dataset with 1365 calibrated images is created, used for testing, and made publicly available. The results are presented and discussed. The source code and the dataset are available at http://www.fer.unizg.hr/ipg/resources/color_constancy/.
Green Stability Assumption: Unsupervised Learning for Statistics-Based Illumination Estimation
Feb 02, 2018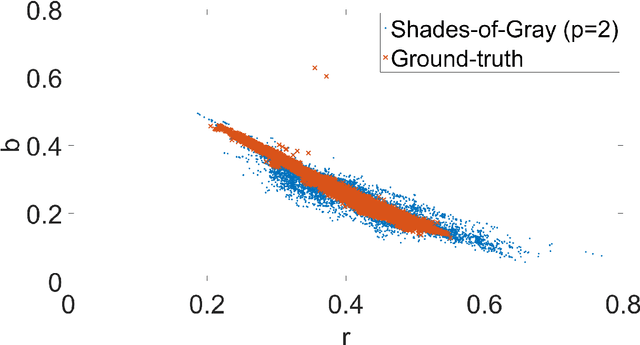

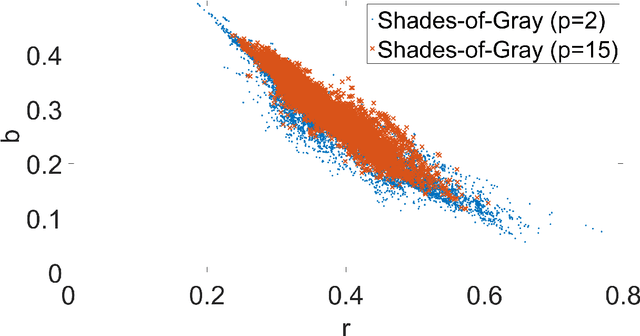
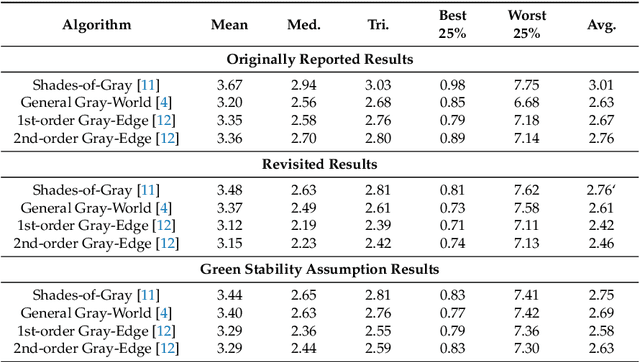
In the image processing pipeline of almost every digital camera there is a part dedicated to computational color constancy i.e. to removing the influence of illumination on the colors of the image scene. Some of the best known illumination estimation methods are the so called statistics-based methods. They are less accurate than the learning-based illumination estimation methods, but they are faster and simpler to implement in embedded systems, which is one of the reasons for their widespread usage. Although in the relevant literature it often appears as if they require no training, this is not true because they have parameter values that need to be fine-tuned in order to be more accurate. In this paper it is first shown that the accuracy of statistics-based methods reported in most papers was not obtained by means of the necessary cross-validation, but by using the whole benchmark datasets for both training and testing. After that the corrected results are given for the best known benchmark datasets. Finally, the so called green stability assumption is proposed that can be used to fine-tune the values of the parameters of the statistics-based methods by using only non-calibrated images without known ground-truth illumination. The obtained accuracy is practically the same as when using calibrated training images, but the whole process is much faster. The experimental results are presented and discussed. The source code is available at http://www.fer.unizg.hr/ipg/resources/color_constancy/.