 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllumination Estimation Challenge: experience of past two years
Dec 31, 2020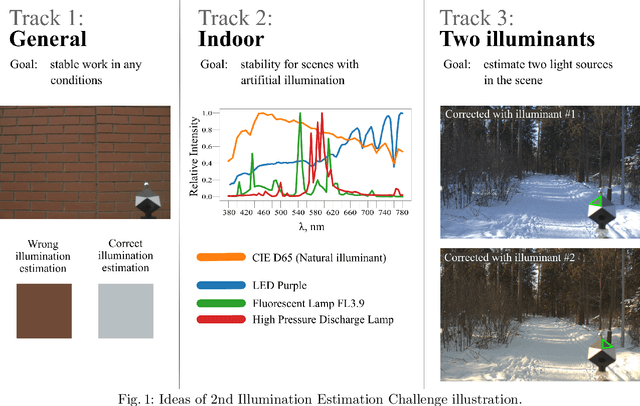
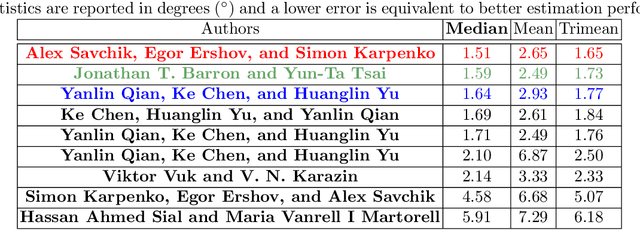

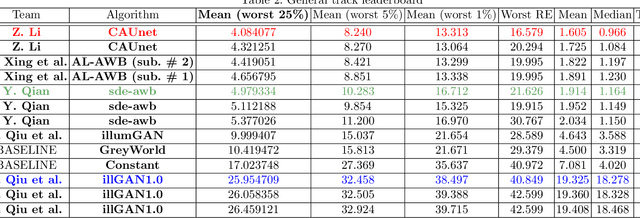
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.
The Cube++ Illumination Estimation Dataset
Nov 19, 2020
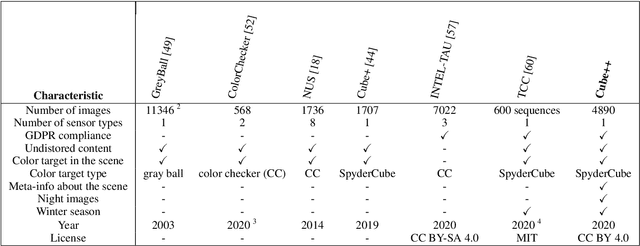

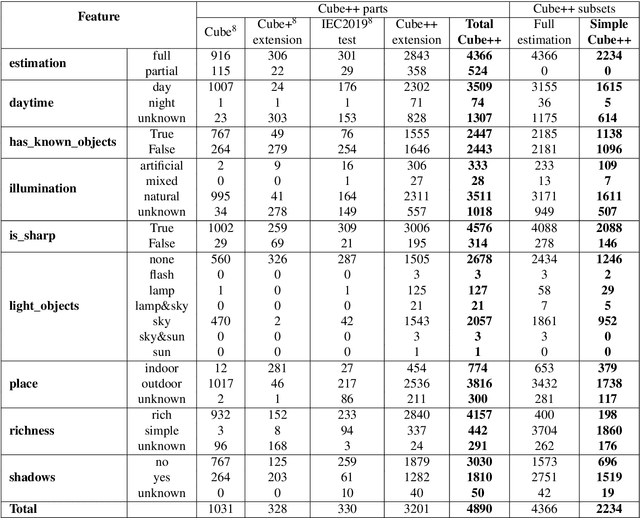
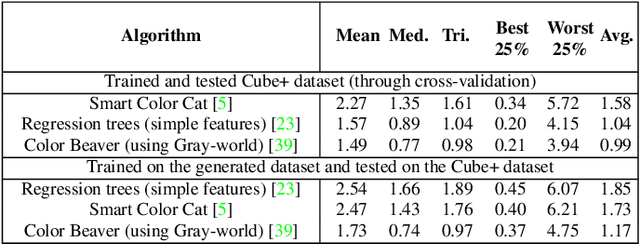
Computational color constancy has the important task of reducing the influence of the scene illumination on the object colors. As such, it is an essential part of the image processing pipelines of most digital cameras. One of the important parts of the computational color constancy is illumination estimation, i.e. estimating the illumination color. When an illumination estimation method is proposed, its accuracy is usually reported by providing the values of error metrics obtained on the images of publicly available datasets. However, over time it has been shown that many of these datasets have problems such as too few images, inappropriate image quality, lack of scene diversity, absence of version tracking, violation of various assumptions, GDPR regulation violation, lack of additional shooting procedure info, etc. In this paper, a new illumination estimation dataset is proposed that aims to alleviate many of the mentioned problems and to help the illumination estimation research. It consists of 4890 images with known illumination colors as well as with additional semantic data that can further make the learning process more accurate. Due to the usage of the SpyderCube color target, for every image there are two ground-truth illumination records covering different directions. Because of that, the dataset can be used for training and testing of methods that perform single or two-illuminant estimation. This makes it superior to many similar existing datasets. The datasets, it's smaller version SimpleCube++, and the accompanying code are available at https://github.com/Visillect/CubePlusPlus/.
CroP: Color Constancy Benchmark Dataset Generator
Mar 29, 2019
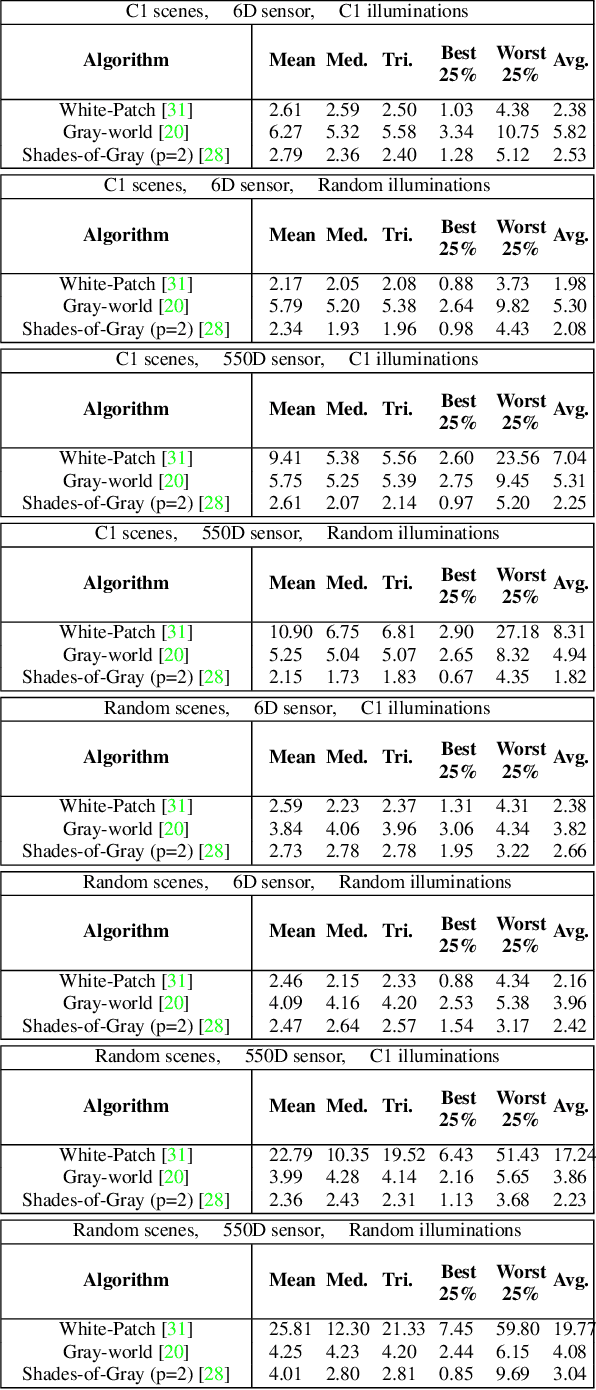
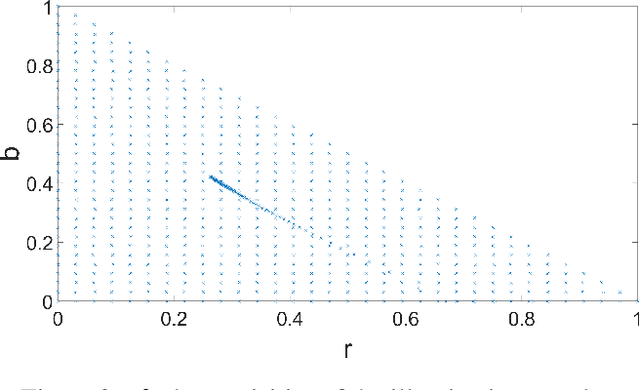
Implementing color constancy as a pre-processing step in contemporary digital cameras is of significant importance as it removes the influence of scene illumination on object colors. Several benchmark color constancy datasets have been created for the purpose of developing and testing new color constancy methods. However, they all have numerous drawbacks including a small number of images, erroneously extracted ground-truth illuminations, long histories of misuses, violations of their stated assumptions, etc. To overcome such and similar problems, in this paper a color constancy benchmark dataset generator is proposed. For a given camera sensor it enables generation of any number of realistic raw images taken in a subset of the real world, namely images of printed photographs. Datasets with such images share many positive features with other existing real-world datasets, while some of the negative features are completely eliminated. The generated images can be successfully used to train methods that afterward achieve high accuracy on real-world datasets. This opens the way for creating large enough datasets for advanced deep learning techniques. Experimental results are presented and discussed. The source code is available at http://www.fer.unizg.hr/ipg/resources/color_constancy/.
The Past and the Present of the Color Checker Dataset Misuse
Mar 11, 2019
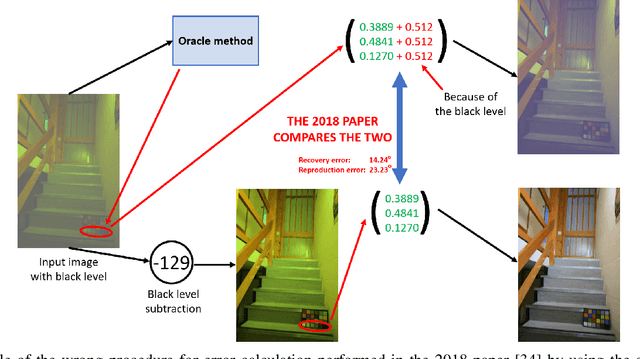

The pipelines of digital cameras contain a part for computational color constancy, which aims to remove the influence of the illumination on the scene colors. One of the best known and most widely used benchmark datasets for this problem is the Color Checker dataset. However, due to the improper handling of the black level in its images, this dataset has been widely misused and while some recent publications tried to alleviate the problem, they nevertheless erred and created additional wrong data. This paper gives a history of the Color Checker dataset usage, it describes the origins and reasons for its misuses, and it explains the old and new mistakes introduced in the most recent publications that tried to handle the issue. This should, hopefully, help to prevent similar future misuses.