 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality assessment of 3D human animation: Subjective and objective evaluation
May 29, 2025Virtual human animations have a wide range of applications in virtual and augmented reality. While automatic generation methods of animated virtual humans have been developed, assessing their quality remains challenging. Recently, approaches introducing task-oriented evaluation metrics have been proposed, leveraging neural network training. However, quality assessment measures for animated virtual humans that are not generated with parametric body models have yet to be developed. In this context, we introduce a first such quality assessment measure leveraging a novel data-driven framework. First, we generate a dataset of virtual human animations together with their corresponding subjective realism evaluation scores collected with a user study. Second, we use the resulting dataset to learn predicting perceptual evaluation scores. Results indicate that training a linear regressor on our dataset results in a correlation of 90%, which outperforms a state of the art deep learning baseline.
Learning to Infer Parameterized Representations of Plants from 3D Scans
May 28, 2025Reconstructing faithfully the 3D architecture of plants from unstructured observations is a challenging task. Plants frequently contain numerous organs, organized in branching systems in more or less complex spatial networks, leading to specific computational issues due to self-occlusion or spatial proximity between organs. Existing works either consider inverse modeling where the aim is to recover the procedural rules that allow to simulate virtual plants, or focus on specific tasks such as segmentation or skeletonization. We propose a unified approach that, given a 3D scan of a plant, allows to infer a parameterized representation of the plant. This representation describes the plant's branching structure, contains parametric information for each plant organ, and can therefore be used directly in a variety of tasks. In this data-driven approach, we train a recursive neural network with virtual plants generated using an L-systems-based procedural model. After training, the network allows to infer a parametric tree-like representation based on an input 3D point cloud. Our method is applicable to any plant that can be represented as binary axial tree. We evaluate our approach on Chenopodium Album plants, using experiments on synthetic plants to show that our unified framework allows for different tasks including reconstruction, segmentation and skeletonization, while achieving results on-par with state-of-the-art for each task.
D-Garment: Physics-Conditioned Latent Diffusion for Dynamic Garment Deformations
Apr 04, 2025Adjusting and deforming 3D garments to body shapes, body motion, and cloth material is an important problem in virtual and augmented reality. Applications are numerous, ranging from virtual change rooms to the entertainment and gaming industry. This problem is challenging as garment dynamics influence geometric details such as wrinkling patterns, which depend on physical input including the wearer's body shape and motion, as well as cloth material features. Existing work studies learning-based modeling techniques to generate garment deformations from example data, and physics-inspired simulators to generate realistic garment dynamics. We propose here a learning-based approach trained on data generated with a physics-based simulator. Compared to prior work, our 3D generative model learns garment deformations for loose cloth geometry, especially for large deformations and dynamic wrinkles driven by body motion and cloth material. Furthermore, the model can be efficiently fitted to observations captured using vision sensors. We propose to leverage the capability of diffusion models to learn fine-scale detail: we model the 3D garment in a 2D parameter space, and learn a latent diffusion model using this representation independent from the mesh resolution. This allows to condition global and local geometric information with body and material information. We quantitatively and qualitatively evaluate our method on both simulated data and data captured with a multi-view acquisition platform. Compared to strong baselines, our method is more accurate in terms of Chamfer distance.
Pose-independent 3D Anthropometry from Sparse Data
Jan 10, 2025
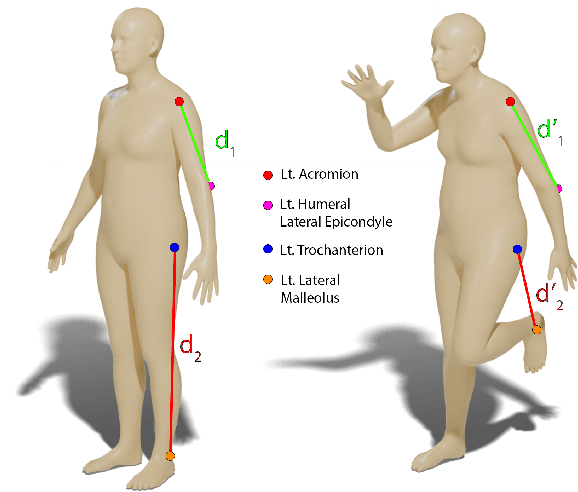


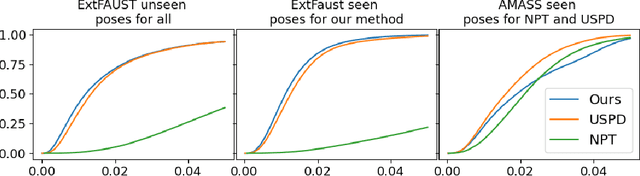
3D digital anthropometry is the study of estimating human body measurements from 3D scans. Precise body measurements are important health indicators in the medical industry, and guiding factors in the fashion, ergonomic and entertainment industries. The measuring protocol consists of scanning the whole subject in the static A-pose, which is maintained without breathing or movement during the scanning process. However, the A-pose is not easy to maintain during the whole scanning process, which can last even up to a couple of minutes. This constraint affects the final quality of the scan, which in turn affects the accuracy of the estimated body measurements obtained from methods that rely on dense geometric data. Additionally, this constraint makes it impossible to develop a digital anthropometry method for subjects unable to assume the A-pose, such as those with injuries or disabilities. We propose a method that can obtain body measurements from sparse landmarks acquired in any pose. We make use of the sparse landmarks of the posed subject to create pose-independent features, and train a network to predict the body measurements as taken from the standard A-pose. We show that our method achieves comparable results to competing methods that use dense geometry in the standard A-pose, but has the capability of estimating the body measurements from any pose using sparse landmarks only. Finally, we address the lack of open-source 3D anthropometry methods by making our method available to the research community at https://github.com/DavidBoja/pose-independent-anthropometry.
Combining Neural Fields and Deformation Models for Non-Rigid 3D Motion Reconstruction from Partial Data
Dec 11, 2024



We introduce a novel, data-driven approach for reconstructing temporally coherent 3D motion from unstructured and potentially partial observations of non-rigidly deforming shapes. Our goal is to achieve high-fidelity motion reconstructions for shapes that undergo near-isometric deformations, such as humans wearing loose clothing. The key novelty of our work lies in its ability to combine implicit shape representations with explicit mesh-based deformation models, enabling detailed and temporally coherent motion reconstructions without relying on parametric shape models or decoupling shape and motion. Each frame is represented as a neural field decoded from a feature space where observations over time are fused, hence preserving geometric details present in the input data. Temporal coherence is enforced with a near-isometric deformation constraint between adjacent frames that applies to the underlying surface in the neural field. Our method outperforms state-of-the-art approaches, as demonstrated by its application to human and animal motion sequences reconstructed from monocular depth videos.
Deformation-Guided Unsupervised Non-Rigid Shape Matching
Nov 27, 2023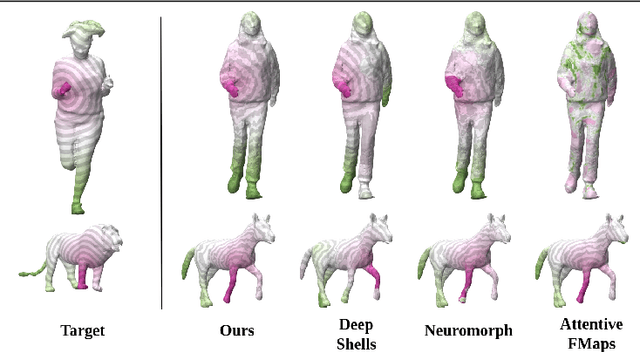

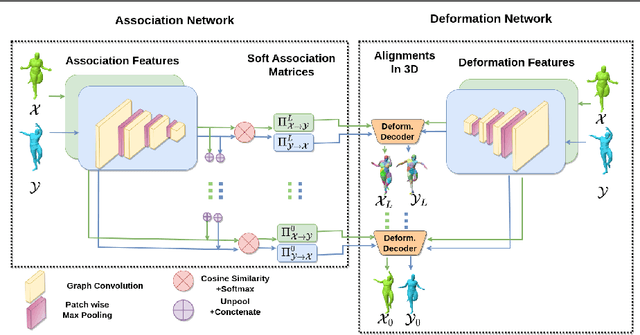
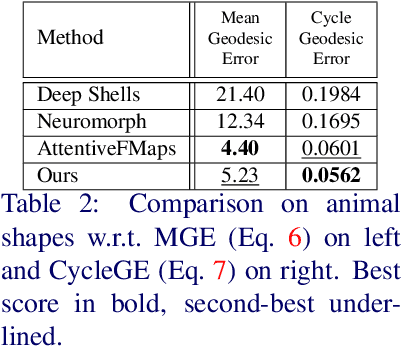
We present an unsupervised data-driven approach for non-rigid shape matching. Shape matching identifies correspondences between two shapes and is a fundamental step in many computer vision and graphics applications. Our approach is designed to be particularly robust when matching shapes digitized using 3D scanners that contain fine geometric detail and suffer from different types of noise including topological noise caused by the coalescence of spatially close surface regions. We build on two strategies. First, using a hierarchical patch based shape representation we match shapes consistently in a coarse to fine manner, allowing for robustness to noise. This multi-scale representation drastically reduces the dimensionality of the problem when matching at the coarsest scale, rendering unsupervised learning feasible. Second, we constrain this hierarchical matching to be reflected in 3D by fitting a patch-wise near-rigid deformation model. Using this constraint, we leverage spatial continuity at different scales to capture global shape properties, resulting in matchings that generalize well to data with different deformations and noise characteristics. Experiments demonstrate that our approach obtains significantly better results on raw 3D scans than state-of-the-art methods, while performing on-par on standard test scenarios.
4DHumanOutfit: a multi-subject 4D dataset of human motion sequences in varying outfits exhibiting large displacements
Jun 12, 2023
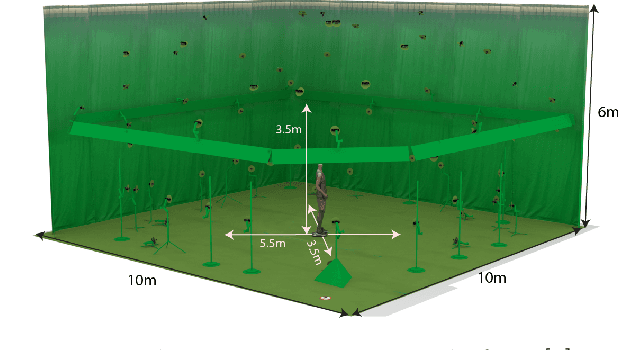

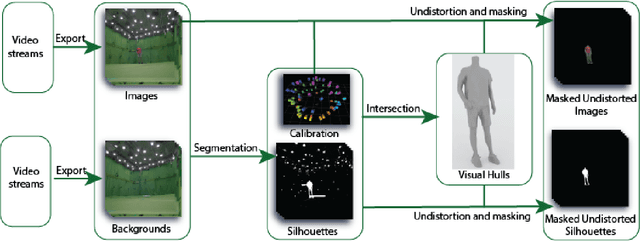
This work presents 4DHumanOutfit, a new dataset of densely sampled spatio-temporal 4D human motion data of different actors, outfits and motions. The dataset is designed to contain different actors wearing different outfits while performing different motions in each outfit. In this way, the dataset can be seen as a cube of data containing 4D motion sequences along 3 axes with identity, outfit and motion. This rich dataset has numerous potential applications for the processing and creation of digital humans, e.g. augmented reality, avatar creation and virtual try on. 4DHumanOutfit is released for research purposes at https://kinovis.inria.fr/4dhumanoutfit/. In addition to image data and 4D reconstructions, the dataset includes reference solutions for each axis. We present independent baselines along each axis that demonstrate the value of these reference solutions for evaluation tasks.
Correspondence-free online human motion retargeting
Feb 01, 2023



We present a novel data-driven framework for unsupervised human motion retargeting which animates a target body shape with a source motion. This allows to retarget motions between different characters by animating a target subject with a motion of a source subject. Our method is correspondence-free,~\ie neither spatial correspondences between the source and target shapes nor temporal correspondences between different frames of the source motion are required. Our proposed method directly animates a target shape with arbitrary sequences of humans in motion, possibly captured using 4D acquisition platforms or consumer devices. Our framework takes into account long-term temporal context of $1$ second during retargeting while accounting for surface details. To achieve this, we take inspiration from two lines of existing work: skeletal motion retargeting, which leverages long-term temporal context at the cost of surface detail, and surface-based retargeting, which preserves surface details without considering long-term temporal context. We unify the advantages of these works by combining a learnt skinning field with a skeletal retargeting approach. During inference, our method runs online,~\ie the input can be processed in a serial way, and retargeting is performed in a single forward pass per frame. Experiments show that including long-term temporal context during training improves the method's accuracy both in terms of the retargeted skeletal motion and the detail preservation. Furthermore, our method generalizes well on unobserved motions and body shapes. We demonstrate that the proposed framework achieves state-of-the-art results on two test datasets.
Spatio-temporal motion completion using a sequence of latent primitives
Jun 27, 2022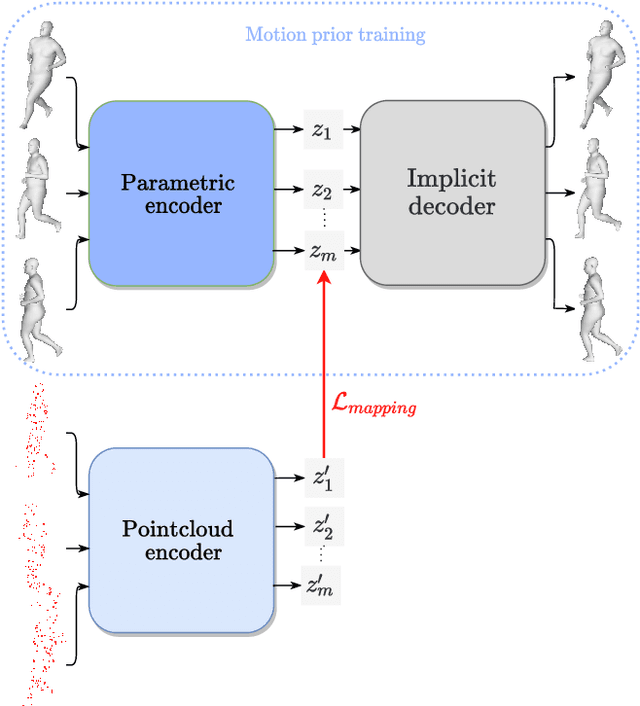
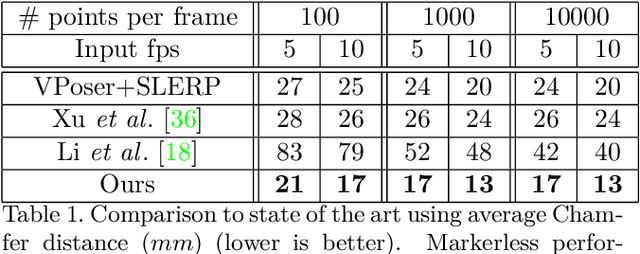
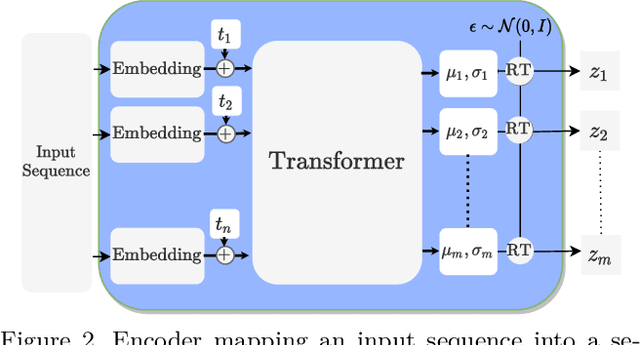
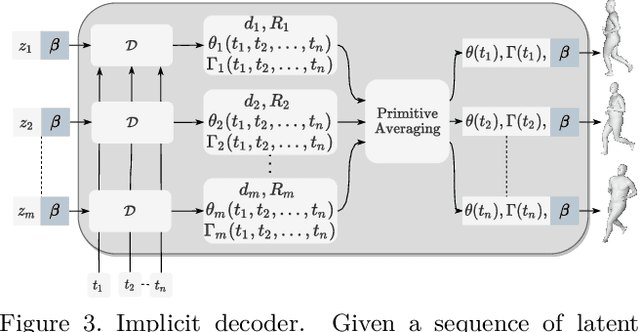
We propose a markerless performance capture method that computes a temporally coherent 4D representation of an actor deforming over time from a sparsely sampled sequence of untracked 3D point clouds. Our method proceeds by latent optimization with a spatio-temporal motion prior. Recently, task generic motion priors have been introduced and propose a coherent representation of human motion based on a single latent code, with encouraging results with short sequences and given temporal correspondences. Extending these methods to longer sequences without correspondences is all but straightforward. One latent code proves inefficient to encode longer term variability, and latent space optimization will be very susceptible to erroneous local minima due to possible inverted pose fittings. We address both problems by learning a motion prior that encodes a 4D human motion sequence into a sequence of latent primitives instead of one latent code. We also propose an additional mapping encoder which directly projects a sequence of point clouds into the learned latent space to provide a good initialization of the latent representation at inference time. Our temporal decoding from latent space is implicit and continuous in time, providing flexibility with temporal resolution. We show experimentally that our method outperforms state-of-the-art motion priors.
Neural Human Deformation Transfer
Oct 01, 2021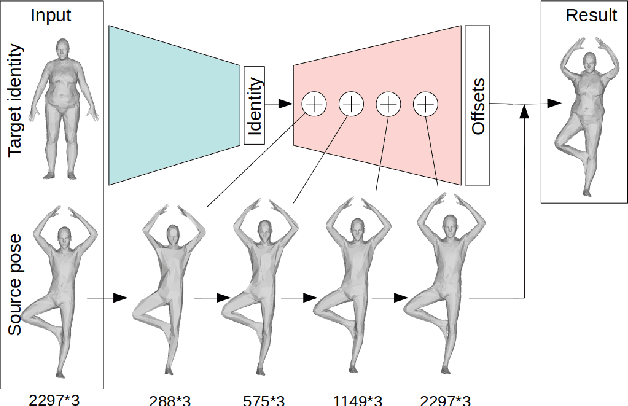

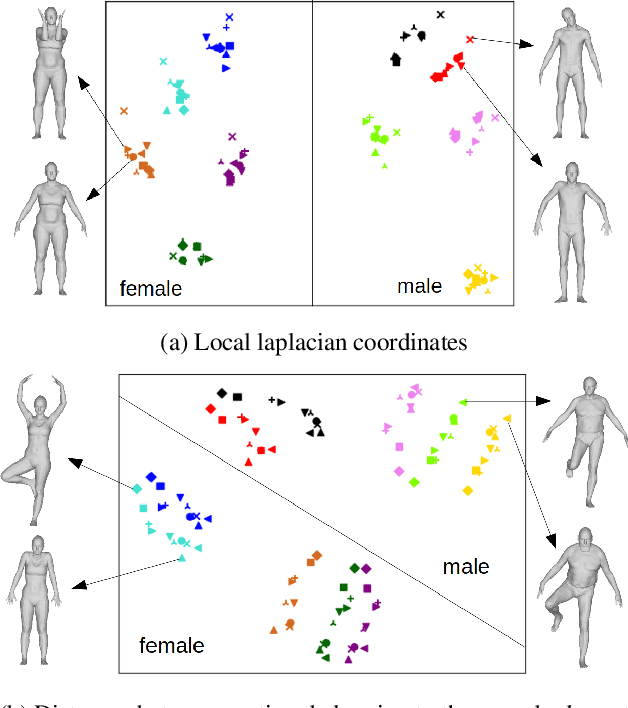
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.