 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Mesh Modeling for Anny Body
Nov 05, 2025Parametric body models are central to many human-centric tasks, yet existing models often rely on costly 3D scans and learned shape spaces that are proprietary and demographically narrow. We introduce Anny, a simple, fully differentiable, and scan-free human body model grounded in anthropometric knowledge from the MakeHuman community. Anny defines a continuous, interpretable shape space, where phenotype parameters (e.g. gender, age, height, weight) control blendshapes spanning a wide range of human forms -- across ages (from infants to elders), body types, and proportions. Calibrated using WHO population statistics, it provides realistic and demographically grounded human shape variation within a single unified model. Thanks to its openness and semantic control, Anny serves as a versatile foundation for 3D human modeling -- supporting millimeter-accurate scan fitting, controlled synthetic data generation, and Human Mesh Recovery (HMR). We further introduce Anny-One, a collection of 800k photorealistic humans generated with Anny, showing that despite its simplicity, HMR models trained with Anny can match the performance of those trained with scan-based body models, while remaining interpretable and broadly representative. The Anny body model and its code are released under the Apache 2.0 license, making Anny an accessible foundation for human-centric 3D modeling.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024



We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
Cross-view and Cross-pose Completion for 3D Human Understanding
Nov 15, 2023



Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
SHOWMe: Benchmarking Object-agnostic Hand-Object 3D Reconstruction
Sep 19, 2023Recent hand-object interaction datasets show limited real object variability and rely on fitting the MANO parametric model to obtain groundtruth hand shapes. To go beyond these limitations and spur further research, we introduce the SHOWMe dataset which consists of 96 videos, annotated with real and detailed hand-object 3D textured meshes. Following recent work, we consider a rigid hand-object scenario, in which the pose of the hand with respect to the object remains constant during the whole video sequence. This assumption allows us to register sub-millimetre-precise groundtruth 3D scans to the image sequences in SHOWMe. Although simpler, this hypothesis makes sense in terms of applications where the required accuracy and level of detail is important eg., object hand-over in human-robot collaboration, object scanning, or manipulation and contact point analysis. Importantly, the rigidity of the hand-object systems allows to tackle video-based 3D reconstruction of unknown hand-held objects using a 2-stage pipeline consisting of a rigid registration step followed by a multi-view reconstruction (MVR) part. We carefully evaluate a set of non-trivial baselines for these two stages and show that it is possible to achieve promising object-agnostic 3D hand-object reconstructions employing an SfM toolbox or a hand pose estimator to recover the rigid transforms and off-the-shelf MVR algorithms. However, these methods remain sensitive to the initial camera pose estimates which might be imprecise due to lack of textures on the objects or heavy occlusions of the hands, leaving room for improvements in the reconstruction. Code and dataset are available at https://europe.naverlabs.com/research/showme
4DHumanOutfit: a multi-subject 4D dataset of human motion sequences in varying outfits exhibiting large displacements
Jun 12, 2023
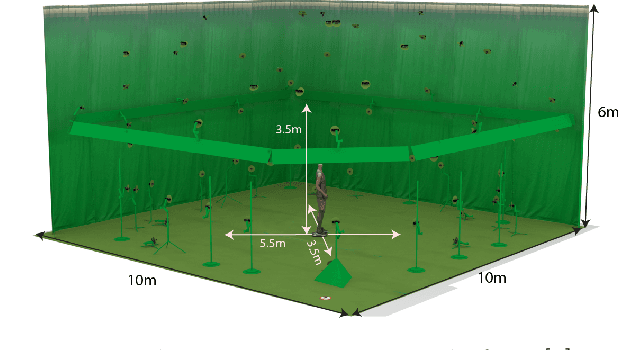

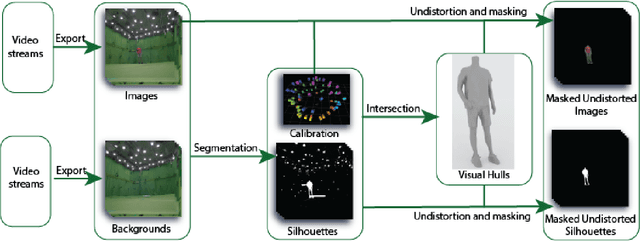
This work presents 4DHumanOutfit, a new dataset of densely sampled spatio-temporal 4D human motion data of different actors, outfits and motions. The dataset is designed to contain different actors wearing different outfits while performing different motions in each outfit. In this way, the dataset can be seen as a cube of data containing 4D motion sequences along 3 axes with identity, outfit and motion. This rich dataset has numerous potential applications for the processing and creation of digital humans, e.g. augmented reality, avatar creation and virtual try on. 4DHumanOutfit is released for research purposes at https://kinovis.inria.fr/4dhumanoutfit/. In addition to image data and 4D reconstructions, the dataset includes reference solutions for each axis. We present independent baselines along each axis that demonstrate the value of these reference solutions for evaluation tasks.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
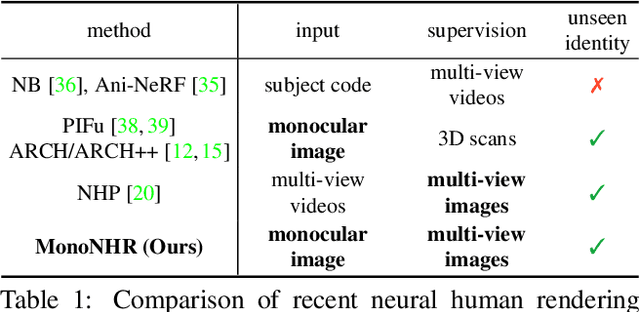
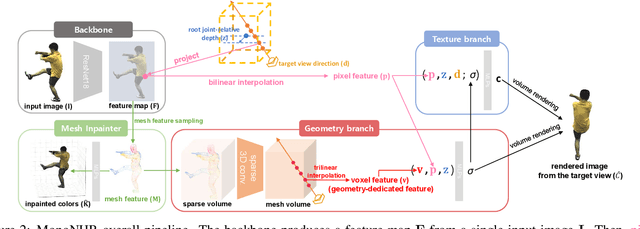
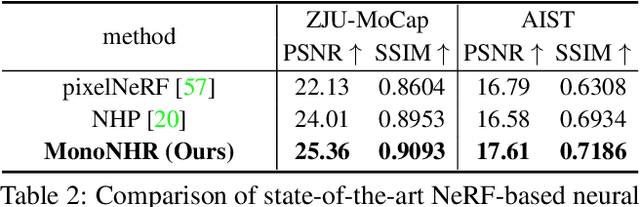
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.