 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Reconstruction of Animatable 3D Avatars with Cloth Dynamics from a Single Image
Mar 16, 2026Existing single-image 3D human avatar methods primarily rely on rigid joint transformations, limiting their ability to model realistic cloth dynamics. We present DynaAvatar, a zero-shot framework that reconstructs animatable 3D human avatars with motion-dependent cloth dynamics from a single image. Trained on large-scale multi-person motion datasets, DynaAvatar employs a Transformer-based feed-forward architecture that directly predicts dynamic 3D Gaussian deformations without subject-specific optimization. To overcome the scarcity of dynamic captures, we introduce a static-to-dynamic knowledge transfer strategy: a Transformer pretrained on large-scale static captures provides strong geometric and appearance priors, which are efficiently adapted to motion-dependent deformations through lightweight LoRA fine-tuning on dynamic captures. We further propose the DynaFlow loss, an optical flow-guided objective that provides reliable motion-direction geometric cues for cloth dynamics in rendered space. Finally, we reannotate the missing or noisy SMPL-X fittings in existing dynamic capture datasets, as most public dynamic capture datasets contain incomplete or unreliable fittings that are unsuitable for training high-quality 3D avatar reconstruction models. Experiments demonstrate that DynaAvatar produces visually rich and generalizable animations, outperforming prior methods.
Enhancing Hands in 3D Whole-Body Pose Estimation with Conditional Hands Modulator
Mar 16, 2026Accurately recovering hand poses within the body context remains a major challenge in 3D whole-body pose estimation. This difficulty arises from a fundamental supervision gap: whole-body pose estimators are trained on full-body datasets with limited hand diversity, while hand-only estimators, trained on hand-centric datasets, excel at detailed finger articulation but lack global body awareness. To address this, we propose Hand4Whole++, a modular framework that leverages the strengths of both pre-trained whole-body and hand pose estimators. We introduce CHAM (Conditional Hands Modulator), a lightweight module that modulates the whole-body feature stream using hand-specific features extracted from a pre-trained hand pose estimator. This modulation enables the whole-body model to predict wrist orientations that are both accurate and coherent with the upper-body kinematic structure, without retraining the full-body model. In parallel, we directly incorporate finger articulations and hand shapes predicted by the hand pose estimator, aligning them to the full-body mesh via differentiable rigid alignment. This design allows Hand4Whole++ to combine globally consistent body reasoning with fine-grained hand detail. Extensive experiments demonstrate that Hand4Whole++ substantially improves hand accuracy and enhances overall full-body pose quality.
PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
Aug 13, 2025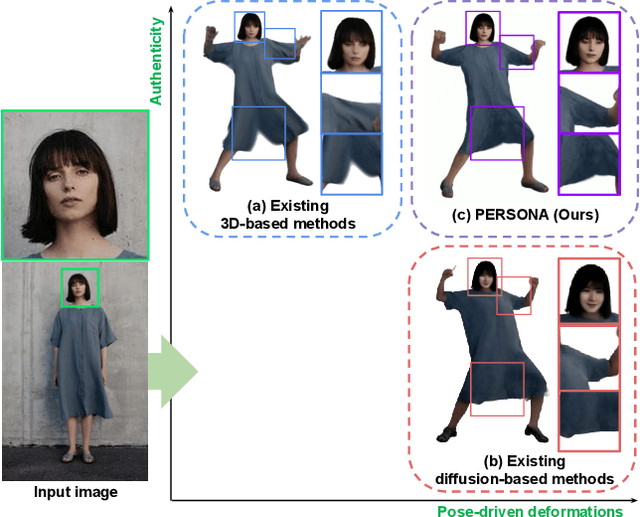



Two major approaches exist for creating animatable human avatars. The first, a 3D-based approach, optimizes a NeRF- or 3DGS-based avatar from videos of a single person, achieving personalization through a disentangled identity representation. However, modeling pose-driven deformations, such as non-rigid cloth deformations, requires numerous pose-rich videos, which are costly and impractical to capture in daily life. The second, a diffusion-based approach, learns pose-driven deformations from large-scale in-the-wild videos but struggles with identity preservation and pose-dependent identity entanglement. We present PERSONA, a framework that combines the strengths of both approaches to obtain a personalized 3D human avatar with pose-driven deformations from a single image. PERSONA leverages a diffusion-based approach to generate pose-rich videos from the input image and optimizes a 3D avatar based on them. To ensure high authenticity and sharp renderings across diverse poses, we introduce balanced sampling and geometry-weighted optimization. Balanced sampling oversamples the input image to mitigate identity shifts in diffusion-generated training videos. Geometry-weighted optimization prioritizes geometry constraints over image loss, preserving rendering quality in diverse poses.
PARTE: Part-Guided Texturing for 3D Human Reconstruction from a Single Image
Jul 24, 2025The misaligned human texture across different human parts is one of the main limitations of existing 3D human reconstruction methods. Each human part, such as a jacket or pants, should maintain a distinct texture without blending into others. The structural coherence of human parts serves as a crucial cue to infer human textures in the invisible regions of a single image. However, most existing 3D human reconstruction methods do not explicitly exploit such part segmentation priors, leading to misaligned textures in their reconstructions. In this regard, we present PARTE, which utilizes 3D human part information as a key guide to reconstruct 3D human textures. Our framework comprises two core components. First, to infer 3D human part information from a single image, we propose a 3D part segmentation module (PartSegmenter) that initially reconstructs a textureless human surface and predicts human part labels based on the textureless surface. Second, to incorporate part information into texture reconstruction, we introduce a part-guided texturing module (PartTexturer), which acquires prior knowledge from a pre-trained image generation network on texture alignment of human parts. Extensive experiments demonstrate that our framework achieves state-of-the-art quality in 3D human reconstruction. The project page is available at https://hygenie1228.github.io/PARTE/.
GLOS: Sign Language Generation with Temporally Aligned Gloss-Level Conditioning
Jun 09, 2025Sign language generation (SLG), or text-to-sign generation, bridges the gap between signers and non-signers. Despite recent progress in SLG, existing methods still often suffer from incorrect lexical ordering and low semantic accuracy. This is primarily due to sentence-level condition, which encodes the entire sentence of the input text into a single feature vector as a condition for SLG. This approach fails to capture the temporal structure of sign language and lacks the granularity of word-level semantics, often leading to disordered sign sequences and ambiguous motions. To overcome these limitations, we propose GLOS, a sign language generation framework with temporally aligned gloss-level conditioning. First, we employ gloss-level conditions, which we define as sequences of gloss embeddings temporally aligned with the motion sequence. This enables the model to access both the temporal structure of sign language and word-level semantics at each timestep. As a result, this allows for fine-grained control of signs and better preservation of lexical order. Second, we introduce a condition fusion module, temporal alignment conditioning (TAC), to efficiently deliver the word-level semantic and temporal structure provided by the gloss-level condition to the corresponding motion timesteps. Our method, which is composed of gloss-level conditions and TAC, generates signs with correct lexical order and high semantic accuracy, outperforming prior methods on CSL-Daily and Phoenix-2014T.
Expressive Whole-Body 3D Gaussian Avatar
Jul 31, 2024



Facial expression and hand motions are necessary to express our emotions and interact with the world. Nevertheless, most of the 3D human avatars modeled from a casually captured video only support body motions without facial expressions and hand motions.In this work, we present ExAvatar, an expressive whole-body 3D human avatar learned from a short monocular video. We design ExAvatar as a combination of the whole-body parametric mesh model (SMPL-X) and 3D Gaussian Splatting (3DGS). The main challenges are 1) a limited diversity of facial expressions and poses in the video and 2) the absence of 3D observations, such as 3D scans and RGBD images. The limited diversity in the video makes animations with novel facial expressions and poses non-trivial. In addition, the absence of 3D observations could cause significant ambiguity in human parts that are not observed in the video, which can result in noticeable artifacts under novel motions. To address them, we introduce our hybrid representation of the mesh and 3D Gaussians. Our hybrid representation treats each 3D Gaussian as a vertex on the surface with pre-defined connectivity information (i.e., triangle faces) between them following the mesh topology of SMPL-X. It makes our ExAvatar animatable with novel facial expressions by driven by the facial expression space of SMPL-X. In addition, by using connectivity-based regularizers, we significantly reduce artifacts in novel facial expressions and poses.
Authentic Hand Avatar from a Phone Scan via Universal Hand Model
May 13, 2024


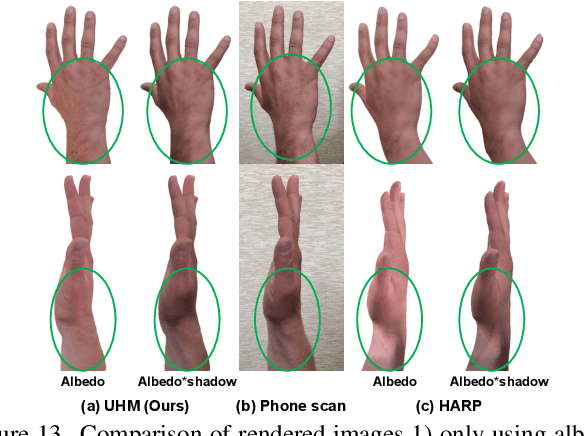
The authentic 3D hand avatar with every identifiable information, such as hand shapes and textures, is necessary for immersive experiences in AR/VR. In this paper, we present a universal hand model (UHM), which 1) can universally represent high-fidelity 3D hand meshes of arbitrary identities (IDs) and 2) can be adapted to each person with a short phone scan for the authentic hand avatar. For effective universal hand modeling, we perform tracking and modeling at the same time, while previous 3D hand models perform them separately. The conventional separate pipeline suffers from the accumulated errors from the tracking stage, which cannot be recovered in the modeling stage. On the other hand, ours does not suffer from the accumulated errors while having a much more concise overall pipeline. We additionally introduce a novel image matching loss function to address a skin sliding during the tracking and modeling, while existing works have not focused on it much. Finally, using learned priors from our UHM, we effectively adapt our UHM to each person's short phone scan for the authentic hand avatar.
Joint Reconstruction of 3D Human and Object via Contact-Based Refinement Transformer
Apr 07, 2024Human-object contact serves as a strong cue to understand how humans physically interact with objects. Nevertheless, it is not widely explored to utilize human-object contact information for the joint reconstruction of 3D human and object from a single image. In this work, we present a novel joint 3D human-object reconstruction method (CONTHO) that effectively exploits contact information between humans and objects. There are two core designs in our system: 1) 3D-guided contact estimation and 2) contact-based 3D human and object refinement. First, for accurate human-object contact estimation, CONTHO initially reconstructs 3D humans and objects and utilizes them as explicit 3D guidance for contact estimation. Second, to refine the initial reconstructions of 3D human and object, we propose a novel contact-based refinement Transformer that effectively aggregates human features and object features based on the estimated human-object contact. The proposed contact-based refinement prevents the learning of erroneous correlation between human and object, which enables accurate 3D reconstruction. As a result, our CONTHO achieves state-of-the-art performance in both human-object contact estimation and joint reconstruction of 3D human and object. The code is publicly available at https://github.com/dqj5182/CONTHO_RELEASE.
URHand: Universal Relightable Hands
Jan 10, 2024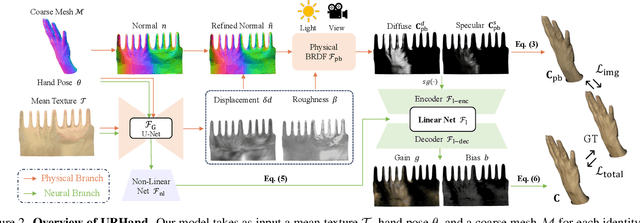
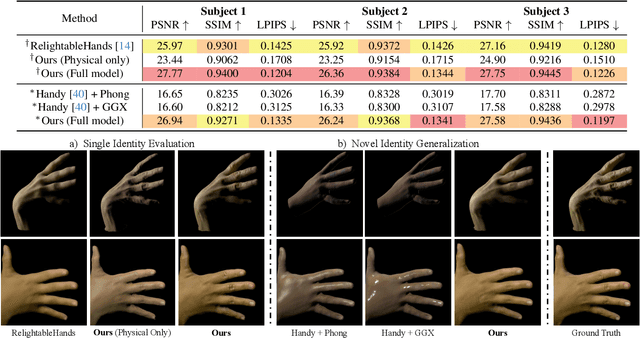
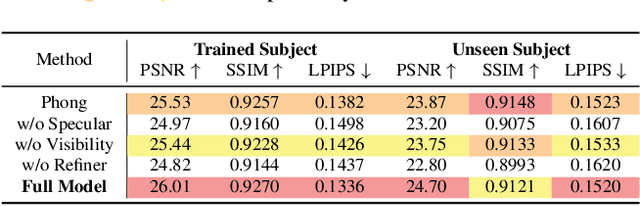
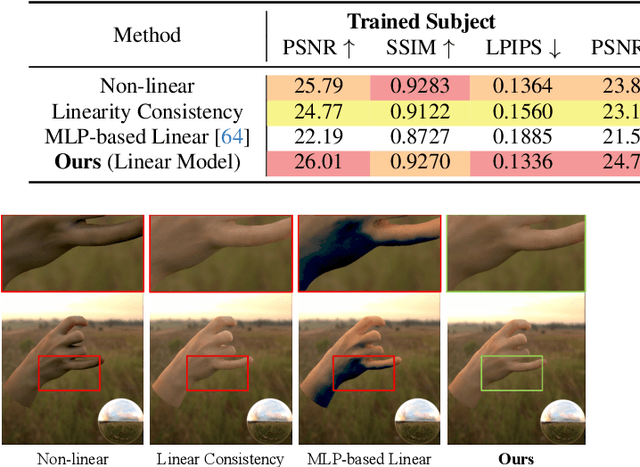
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
A Dataset of Relighted 3D Interacting Hands
Oct 26, 2023



The two-hand interaction is one of the most challenging signals to analyze due to the self-similarity, complicated articulations, and occlusions of hands. Although several datasets have been proposed for the two-hand interaction analysis, all of them do not achieve 1) diverse and realistic image appearances and 2) diverse and large-scale groundtruth (GT) 3D poses at the same time. In this work, we propose Re:InterHand, a dataset of relighted 3D interacting hands that achieve the two goals. To this end, we employ a state-of-the-art hand relighting network with our accurately tracked two-hand 3D poses. We compare our Re:InterHand with existing 3D interacting hands datasets and show the benefit of it. Our Re:InterHand is available in https://mks0601.github.io/ReInterHand/.