 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Diffusion Prior for Task-driven Image Restoration
Jul 30, 2025Task-driven image restoration (TDIR) has recently emerged to address performance drops in high-level vision tasks caused by low-quality (LQ) inputs. Previous TDIR methods struggle to handle practical scenarios in which images are degraded by multiple complex factors, leaving minimal clues for restoration. This motivates us to leverage the diffusion prior, one of the most powerful natural image priors. However, while the diffusion prior can help generate visually plausible results, using it to restore task-relevant details remains challenging, even when combined with recent TDIR methods. To address this, we propose EDTR, which effectively harnesses the power of diffusion prior to restore task-relevant details. Specifically, we propose directly leveraging useful clues from LQ images in the diffusion process by generating from pixel-error-based pre-restored LQ images with mild noise added. Moreover, we employ a small number of denoising steps to prevent the generation of redundant details that dilute crucial task-related information. We demonstrate that our method effectively utilizes diffusion prior for TDIR, significantly enhancing task performance and visual quality across diverse tasks with multiple complex degradations.
Beyond Image Super-Resolution for Image Recognition with Task-Driven Perceptual Loss
Apr 04, 2024

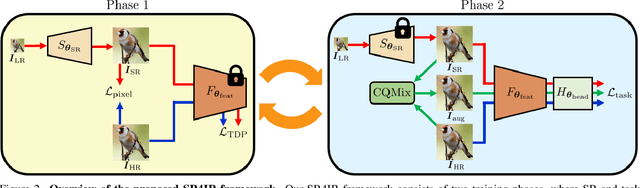

In real-world scenarios, image recognition tasks, such as semantic segmentation and object detection, often pose greater challenges due to the lack of information available within low-resolution (LR) content. Image super-resolution (SR) is one of the promising solutions for addressing the challenges. However, due to the ill-posed property of SR, it is challenging for typical SR methods to restore task-relevant high-frequency contents, which may dilute the advantage of utilizing the SR method. Therefore, in this paper, we propose Super-Resolution for Image Recognition (SR4IR) that effectively guides the generation of SR images beneficial to achieving satisfactory image recognition performance when processing LR images. The critical component of our SR4IR is the task-driven perceptual (TDP) loss that enables the SR network to acquire task-specific knowledge from a network tailored for a specific task. Moreover, we propose a cross-quality patch mix and an alternate training framework that significantly enhances the efficacy of the TDP loss by addressing potential problems when employing the TDP loss. Through extensive experiments, we demonstrate that our SR4IR achieves outstanding task performance by generating SR images useful for a specific image recognition task, including semantic segmentation, object detection, and image classification. The implementation code is available at https://github.com/JaehaKim97/SR4IR.
Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
Mar 27, 2023Hands, one of the most dynamic parts of our body, suffer from blur due to their active movements. However, previous 3D hand mesh recovery methods have mainly focused on sharp hand images rather than considering blur due to the absence of datasets providing blurry hand images. We first present a novel dataset BlurHand, which contains blurry hand images with 3D groundtruths. The BlurHand is constructed by synthesizing motion blur from sequential sharp hand images, imitating realistic and natural motion blurs. In addition to the new dataset, we propose BlurHandNet, a baseline network for accurate 3D hand mesh recovery from a blurry hand image. Our BlurHandNet unfolds a blurry input image to a 3D hand mesh sequence to utilize temporal information in the blurry input image, while previous works output a static single hand mesh. We demonstrate the usefulness of BlurHand for the 3D hand mesh recovery from blurry images in our experiments. The proposed BlurHandNet produces much more robust results on blurry images while generalizing well to in-the-wild images. The training codes and BlurHand dataset are available at https://github.com/JaehaKim97/BlurHand_RELEASE.
Seemo: A new tool for early design window view satisfaction evaluation in residential buildings
Apr 03, 2022



People spend approximately 90% of their lives indoors, and thus arguably, the indoor space design can significantly influence occupant well-being. Adequate views to the outside are one of the most cited indoor qualities related to occupant well-being. However, due to urbanization and densification trends, designers may have difficulties in providing vistas and views to the outside with an assortment of content, which can support the needs of their occupants. To better understand occupant view satisfaction and provide reliable design feedback to architects, existing view satisfaction data must be expanded to capture a wider variety of view scenarios and occupants. Most related research remains challenging in architectural practice due to a lack of easy-to-use early-design analysis tools. However, early assessment of view can be advantageous as design decisions in early design, such as building orientation, plan layout, and facade design, can improve the view quality. This paper, hence, presents results from a 181 participant view satisfaction survey with 590 window views. The survey data is used to train a tree-regression model to predict view satisfaction. The prediction performance was compared to an existing view assessment framework through case studies. The result showed that the new prediction is more accurate to the surveyed result than the framework. Further, the prediction performance was generally high for most responses, verifying the reliability. To facilitate view analysis in early design, this paper describes integrating the satisfaction prediction model and a ray-casting tool to compute view parameters in the CAD environment.
Toward Real-World Super-Resolution via Adaptive Downsampling Models
Sep 08, 2021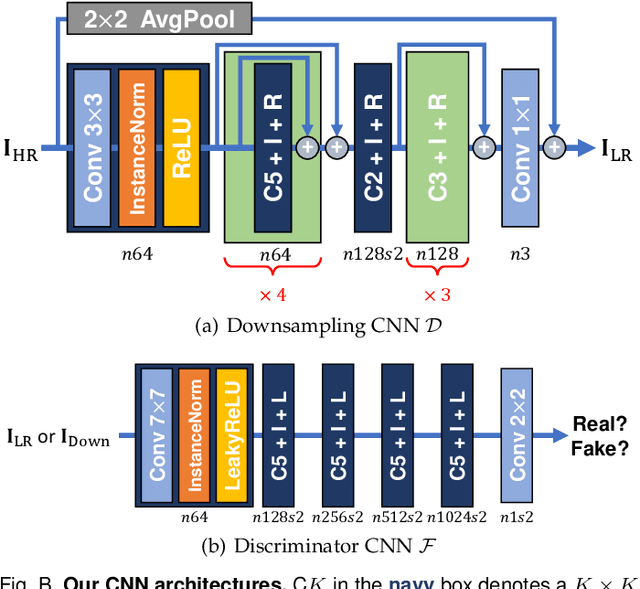

Most image super-resolution (SR) methods are developed on synthetic low-resolution (LR) and high-resolution (HR) image pairs that are constructed by a predetermined operation, e.g., bicubic downsampling. As existing methods typically learn an inverse mapping of the specific function, they produce blurry results when applied to real-world images whose exact formulation is different and unknown. Therefore, several methods attempt to synthesize much more diverse LR samples or learn a realistic downsampling model. However, due to restrictive assumptions on the downsampling process, they are still biased and less generalizable. This study proposes a novel method to simulate an unknown downsampling process without imposing restrictive prior knowledge. We propose a generalizable low-frequency loss (LFL) in the adversarial training framework to imitate the distribution of target LR images without using any paired examples. Furthermore, we design an adaptive data loss (ADL) for the downsampler, which can be adaptively learned and updated from the data during the training loops. Extensive experiments validate that our downsampling model can facilitate existing SR methods to perform more accurate reconstructions on various synthetic and real-world examples than the conventional approaches.