 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
Efficient Hybrid Zoom using Camera Fusion on Mobile Phones
Jan 02, 2024DSLR cameras can achieve multiple zoom levels via shifting lens distances or swapping lens types. However, these techniques are not possible on smartphone devices due to space constraints. Most smartphone manufacturers adopt a hybrid zoom system: commonly a Wide (W) camera at a low zoom level and a Telephoto (T) camera at a high zoom level. To simulate zoom levels between W and T, these systems crop and digitally upsample images from W, leading to significant detail loss. In this paper, we propose an efficient system for hybrid zoom super-resolution on mobile devices, which captures a synchronous pair of W and T shots and leverages machine learning models to align and transfer details from T to W. We further develop an adaptive blending method that accounts for depth-of-field mismatches, scene occlusion, flow uncertainty, and alignment errors. To minimize the domain gap, we design a dual-phone camera rig to capture real-world inputs and ground-truths for supervised training. Our method generates a 12-megapixel image in 500ms on a mobile platform and compares favorably against state-of-the-art methods under extensive evaluation on real-world scenarios.
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
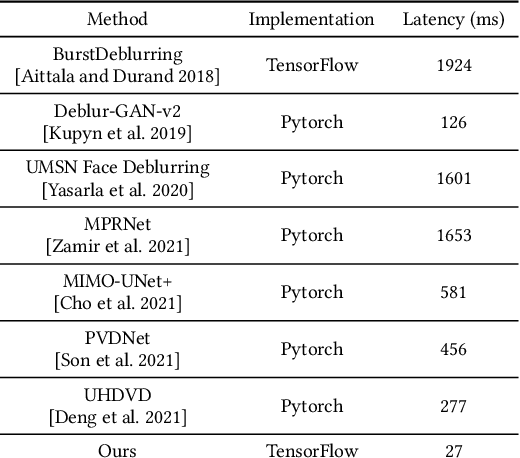

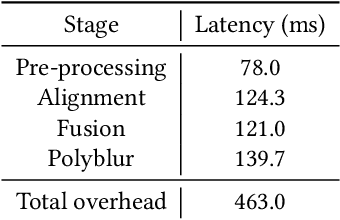
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
Vision Transformer for NeRF-Based View Synthesis from a Single Input Image
Jul 12, 2022

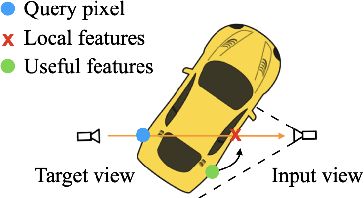
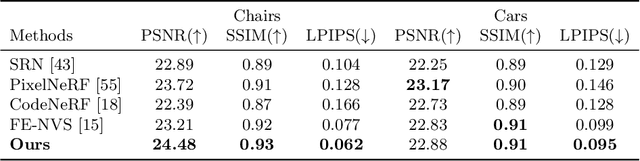
Although neural radiance fields (NeRF) have shown impressive advances for novel view synthesis, most methods typically require multiple input images of the same scene with accurate camera poses. In this work, we seek to substantially reduce the inputs to a single unposed image. Existing approaches condition on local image features to reconstruct a 3D object, but often render blurry predictions at viewpoints that are far away from the source view. To address this issue, we propose to leverage both the global and local features to form an expressive 3D representation. The global features are learned from a vision transformer, while the local features are extracted from a 2D convolutional network. To synthesize a novel view, we train a multilayer perceptron (MLP) network conditioned on the learned 3D representation to perform volume rendering. This novel 3D representation allows the network to reconstruct unseen regions without enforcing constraints like symmetry or canonical coordinate systems. Our method can render novel views from only a single input image and generalize across multiple object categories using a single model. Quantitative and qualitative evaluations demonstrate that the proposed method achieves state-of-the-art performance and renders richer details than existing approaches.
Deep Image Deblurring: A Survey
Jan 26, 2022
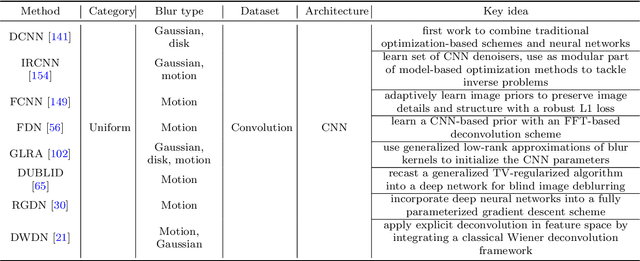
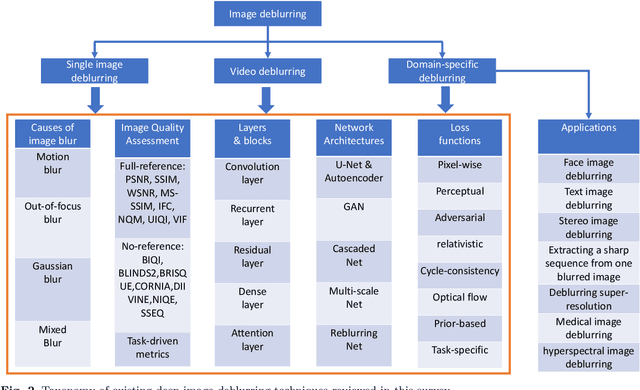
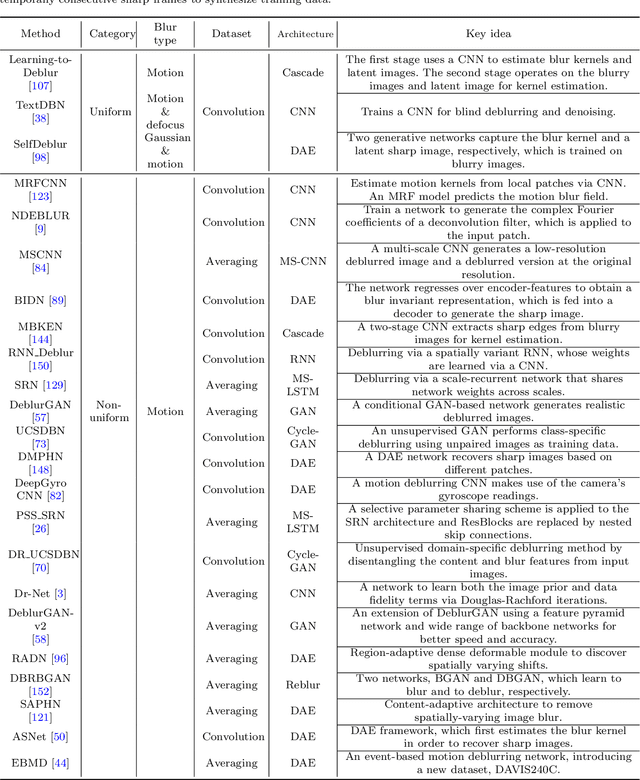
Image deblurring is a classic problem in low-level computer vision, which aims to recover a sharp image from a blurred input image. Recent advances in deep learning have led to significant progress in solving this problem, and a large number of deblurring networks have been proposed. This paper presents a comprehensive and timely survey of recently published deep-learning based image deblurring approaches, aiming to serve the community as a useful literature review. We start by discussing common causes of image blur, introduce benchmark datasets and performance metrics, and summarize different problem formulations. Next we present a taxonomy of methods using convolutional neural networks (CNN) based on architecture, loss function, and application, offering a detailed review and comparison. In addition, we discuss some domain-specific deblurring applications including face images, text, and stereo image pairs. We conclude by discussing key challenges and future research directions.
Correcting Face Distortion in Wide-Angle Videos
Nov 18, 2021


Video blogs and selfies are popular social media formats, which are often captured by wide-angle cameras to show human subjects and expanded background. Unfortunately, due to perspective projection, faces near corners and edges exhibit apparent distortions that stretch and squish the facial features, resulting in poor video quality. In this work, we present a video warping algorithm to correct these distortions. Our key idea is to apply stereographic projection locally on the facial regions. We formulate a mesh warp problem using spatial-temporal energy minimization and minimize background deformation using a line-preservation term to maintain the straight edges in the background. To address temporal coherency, we constrain the temporal smoothness on the warping meshes and facial trajectories through the latent variables. For performance evaluation, we develop a wide-angle video dataset with a wide range of focal lengths. The user study shows that 83.9% of users prefer our algorithm over other alternatives based on perspective projection.
Toward Real-World Super-Resolution via Adaptive Downsampling Models
Sep 08, 2021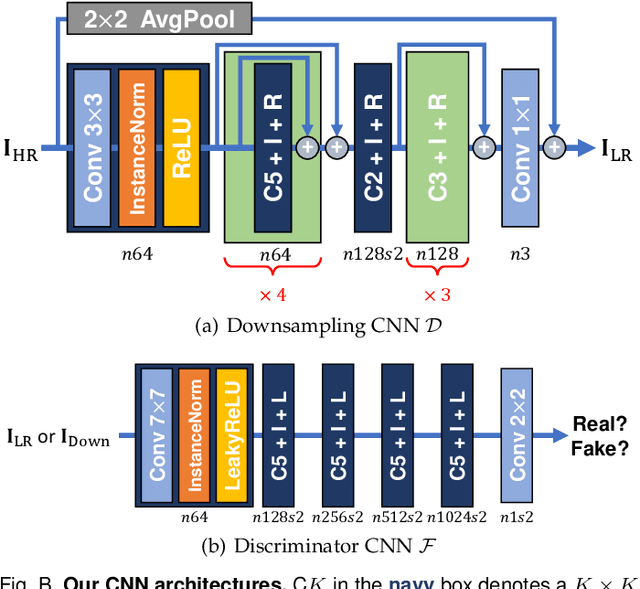

Most image super-resolution (SR) methods are developed on synthetic low-resolution (LR) and high-resolution (HR) image pairs that are constructed by a predetermined operation, e.g., bicubic downsampling. As existing methods typically learn an inverse mapping of the specific function, they produce blurry results when applied to real-world images whose exact formulation is different and unknown. Therefore, several methods attempt to synthesize much more diverse LR samples or learn a realistic downsampling model. However, due to restrictive assumptions on the downsampling process, they are still biased and less generalizable. This study proposes a novel method to simulate an unknown downsampling process without imposing restrictive prior knowledge. We propose a generalizable low-frequency loss (LFL) in the adversarial training framework to imitate the distribution of target LR images without using any paired examples. Furthermore, we design an adaptive data loss (ADL) for the downsampler, which can be adaptively learned and updated from the data during the training loops. Extensive experiments validate that our downsampling model can facilitate existing SR methods to perform more accurate reconstructions on various synthetic and real-world examples than the conventional approaches.
Neural Re-rendering for Full-frame Video Stabilization
Feb 12, 2021
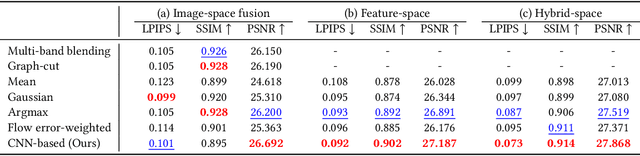
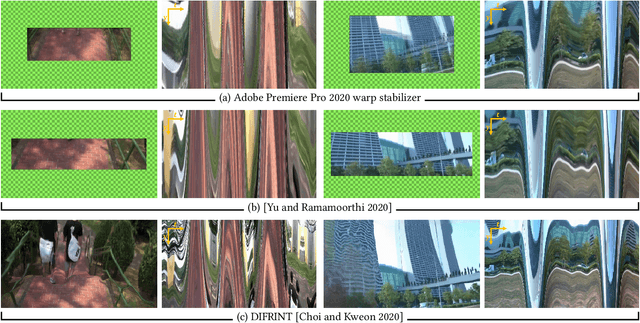
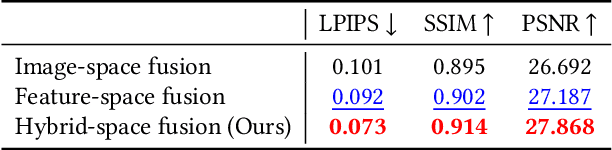
Existing video stabilization methods either require aggressive cropping of frame boundaries or generate distortion artifacts on the stabilized frames. In this work, we present an algorithm for full-frame video stabilization by first estimating dense warp fields. Full-frame stabilized frames can then be synthesized by fusing warped contents from neighboring frames. The core technical novelty lies in our learning-based hybrid-space fusion that alleviates artifacts caused by optical flow inaccuracy and fast-moving objects. We validate the effectiveness of our method on the NUS and selfie video datasets. Extensive experiment results demonstrate the merits of our approach over prior video stabilization methods.
Deep Online Fused Video Stabilization
Feb 02, 2021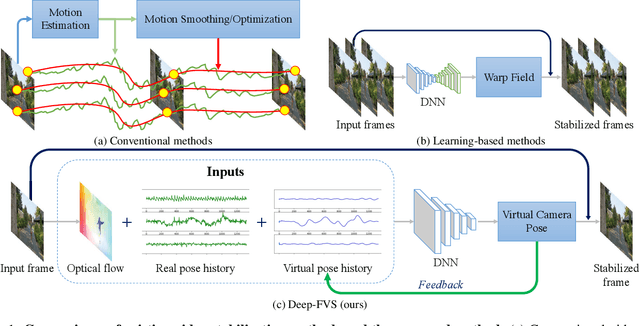

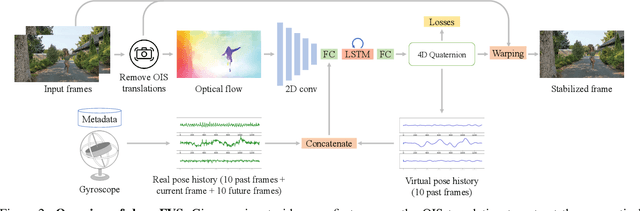
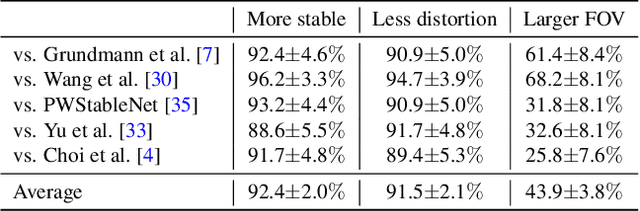
We present a deep neural network (DNN) that uses both sensor data (gyroscope) and image content (optical flow) to stabilize videos through unsupervised learning. The network fuses optical flow with real/virtual camera pose histories into a joint motion representation. Next, the LSTM block infers the new virtual camera pose, and this virtual pose is used to generate a warping grid that stabilizes the frame. Novel relative motion representation as well as a multi-stage training process are presented to optimize our model without any supervision. To the best of our knowledge, this is the first DNN solution that adopts both sensor data and image for stabilization. We validate the proposed framework through ablation studies and demonstrated the proposed method outperforms the state-of-art alternative solutions via quantitative evaluations and a user study.
Portrait Neural Radiance Fields from a Single Image
Dec 10, 2020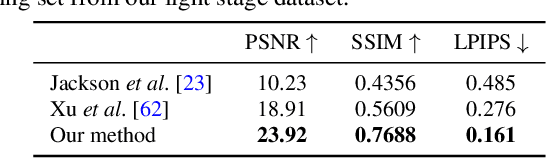
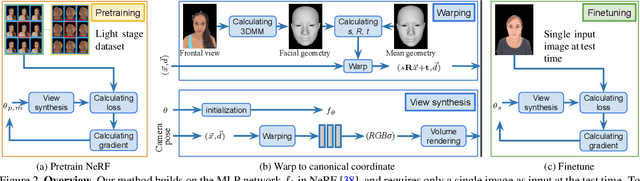
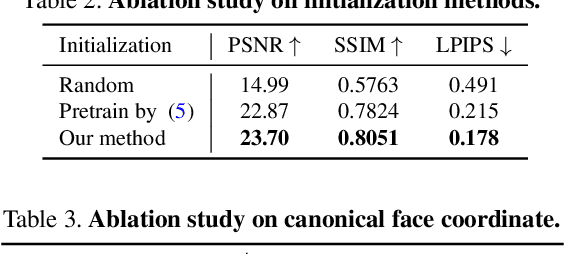
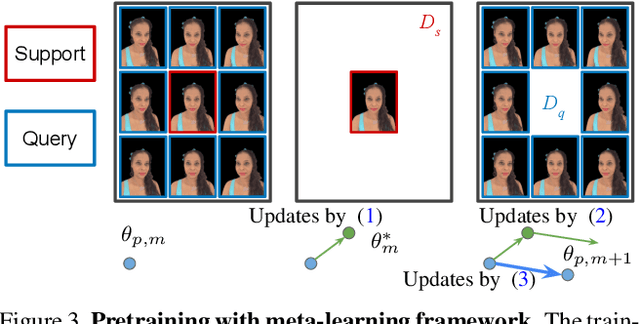
We present a method for estimating Neural Radiance Fields (NeRF) from a single headshot portrait. While NeRF has demonstrated high-quality view synthesis, it requires multiple images of static scenes and thus impractical for casual captures and moving subjects. In this work, we propose to pretrain the weights of a multilayer perceptron (MLP), which implicitly models the volumetric density and colors, with a meta-learning framework using a light stage portrait dataset. To improve the generalization to unseen faces, we train the MLP in the canonical coordinate space approximated by 3D face morphable models. We quantitatively evaluate the method using controlled captures and demonstrate the generalization to real portrait images, showing favorable results against state-of-the-arts.