 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
ExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models
Jun 10, 2024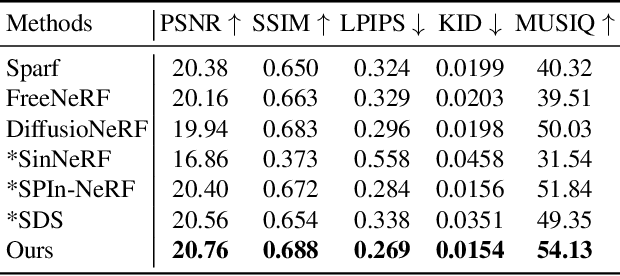
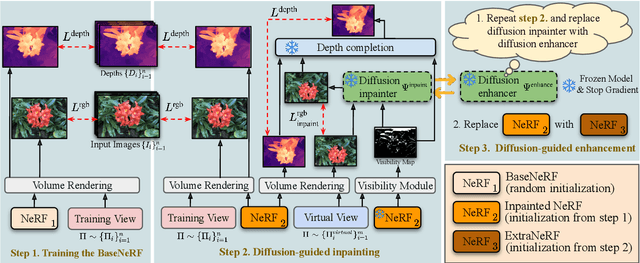
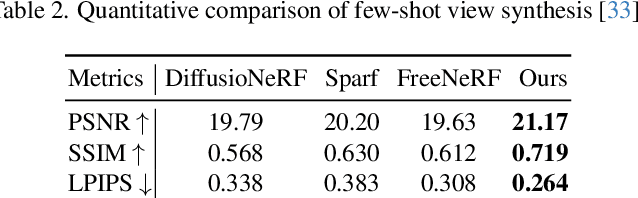
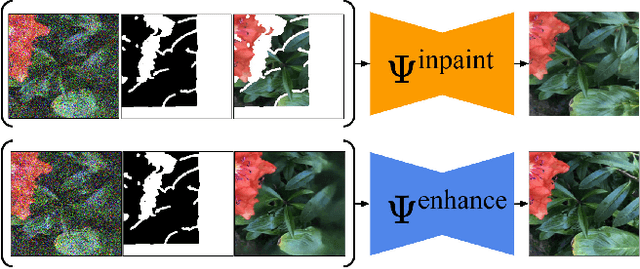
We propose ExtraNeRF, a novel method for extrapolating the range of views handled by a Neural Radiance Field (NeRF). Our main idea is to leverage NeRFs to model scene-specific, fine-grained details, while capitalizing on diffusion models to extrapolate beyond our observed data. A key ingredient is to track visibility to determine what portions of the scene have not been observed, and focus on reconstructing those regions consistently with diffusion models. Our primary contributions include a visibility-aware diffusion-based inpainting module that is fine-tuned on the input imagery, yielding an initial NeRF with moderate quality (often blurry) inpainted regions, followed by a second diffusion model trained on the input imagery to consistently enhance, notably sharpen, the inpainted imagery from the first pass. We demonstrate high-quality results, extrapolating beyond a small number of (typically six or fewer) input views, effectively outpainting the NeRF as well as inpainting newly disoccluded regions inside the original viewing volume. We compare with related work both quantitatively and qualitatively and show significant gains over prior art.
Video Interpolation with Diffusion Models
Apr 01, 2024We present VIDIM, a generative model for video interpolation, which creates short videos given a start and end frame. In order to achieve high fidelity and generate motions unseen in the input data, VIDIM uses cascaded diffusion models to first generate the target video at low resolution, and then generate the high-resolution video conditioned on the low-resolution generated video. We compare VIDIM to previous state-of-the-art methods on video interpolation, and demonstrate how such works fail in most settings where the underlying motion is complex, nonlinear, or ambiguous while VIDIM can easily handle such cases. We additionally demonstrate how classifier-free guidance on the start and end frame and conditioning the super-resolution model on the original high-resolution frames without additional parameters unlocks high-fidelity results. VIDIM is fast to sample from as it jointly denoises all the frames to be generated, requires less than a billion parameters per diffusion model to produce compelling results, and still enjoys scalability and improved quality at larger parameter counts.
Generative Powers of Ten
Dec 04, 2023We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
3D Moments from Near-Duplicate Photos
May 12, 2022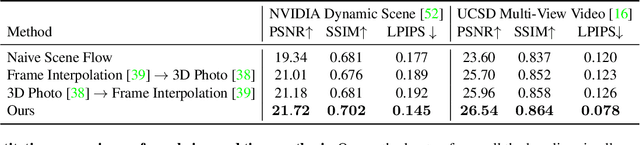
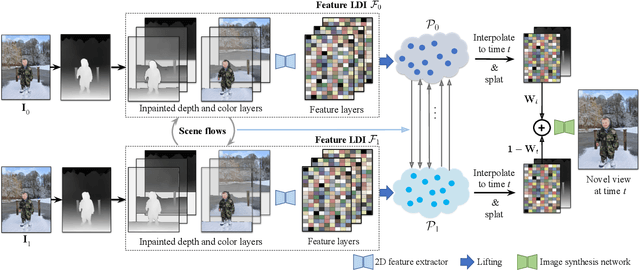
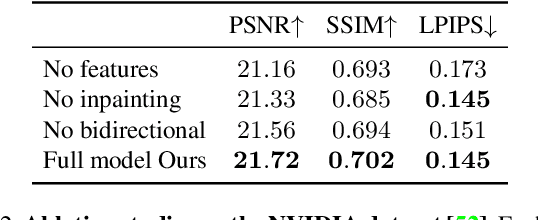
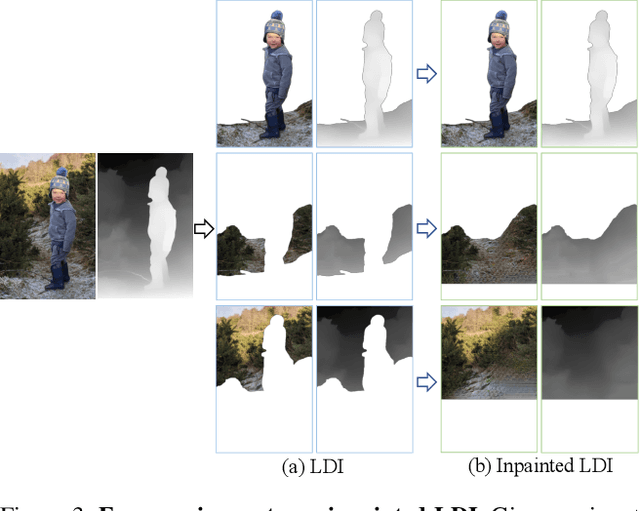
We introduce 3D Moments, a new computational photography effect. As input we take a pair of near-duplicate photos, i.e., photos of moving subjects from similar viewpoints, common in people's photo collections. As output, we produce a video that smoothly interpolates the scene motion from the first photo to the second, while also producing camera motion with parallax that gives a heightened sense of 3D. To achieve this effect, we represent the scene as a pair of feature-based layered depth images augmented with scene flow. This representation enables motion interpolation along with independent control of the camera viewpoint. Our system produces photorealistic space-time videos with motion parallax and scene dynamics, while plausibly recovering regions occluded in the original views. We conduct extensive experiments demonstrating superior performance over baselines on public datasets and in-the-wild photos. Project page: https://3d-moments.github.io/
FILM: Frame Interpolation for Large Motion
Feb 12, 2022



We present a frame interpolation algorithm that synthesizes multiple intermediate frames from two input images with large in-between motion. Recent methods use multiple networks to estimate optical flow or depth and a separate network dedicated to frame synthesis. This is often complex and requires scarce optical flow or depth ground-truth. In this work, we present a single unified network, distinguished by a multi-scale feature extractor that shares weights at all scales, and is trainable from frames alone. To synthesize crisp and pleasing frames, we propose to optimize our network with the Gram matrix loss that measures the correlation difference between feature maps. Our approach outperforms state-of-the-art methods on the Xiph large motion benchmark. We also achieve higher scores on Vimeo-90K, Middlebury and UCF101, when comparing to methods that use perceptual losses. We study the effect of weight sharing and of training with datasets of increasing motion range. Finally, we demonstrate our model's effectiveness in synthesizing high quality and temporally coherent videos on a challenging near-duplicate photos dataset. Codes and pre-trained models are available at https://github.com/google-research/frame-interpolation.
No Shadow Left Behind: Removing Objects and their Shadows using Approximate Lighting and Geometry
Dec 19, 2020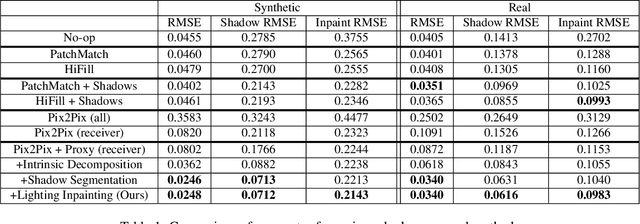
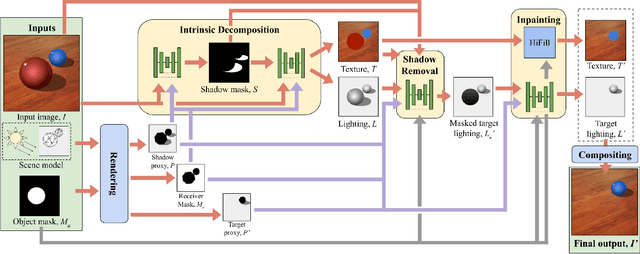


Removing objects from images is a challenging problem that is important for many applications, including mixed reality. For believable results, the shadows that the object casts should also be removed. Current inpainting-based methods only remove the object itself, leaving shadows behind, or at best require specifying shadow regions to inpaint. We introduce a deep learning pipeline for removing a shadow along with its caster. We leverage rough scene models in order to remove a wide variety of shadows (hard or soft, dark or subtle, large or thin) from surfaces with a wide variety of textures. We train our pipeline on synthetically rendered data, and show qualitative and quantitative results on both synthetic and real scenes.