 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMIC: Agentic Sketch Comedy Generation
Mar 11, 2026We propose a fully automated AI system that produces short comedic videos similar to sketch shows such as Saturday Night Live. Starting with character references, the system employs a population of agents loosely based on real production studio roles, structured to optimize the quality and diversity of ideas and outputs through iterative competition, evaluation, and improvement. A key contribution is the introduction of LLM critics aligned with real viewer preferences through the analysis of a corpus of comedy videos on YouTube to automatically evaluate humor. Our experiments show that our framework produces results approaching the quality of professionally produced sketches while demonstrating state-of-the-art performance in video generation.
How Animals Dance (When You're Not Looking)
May 29, 2025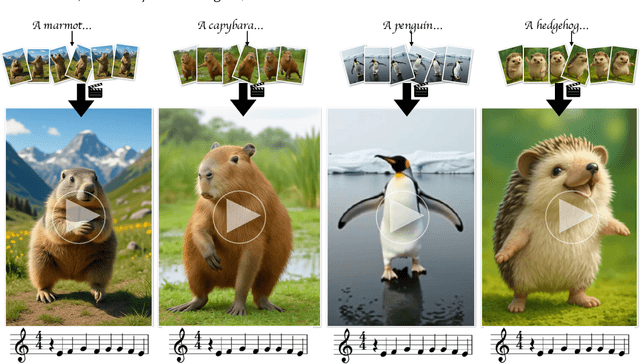
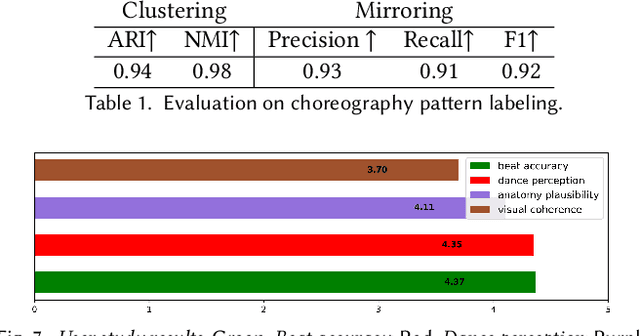

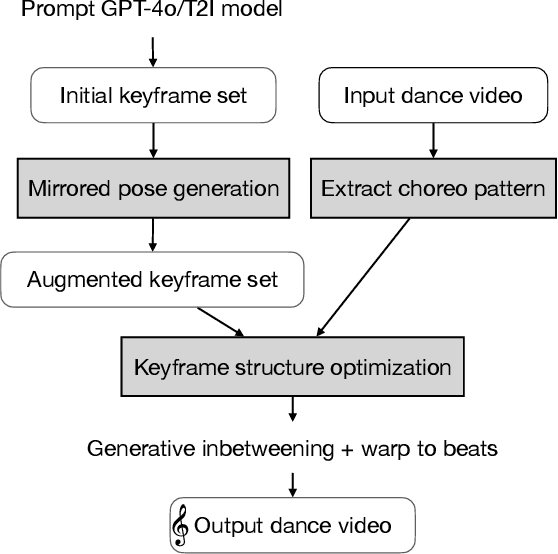
We present a keyframe-based framework for generating music-synchronized, choreography aware animal dance videos. Starting from a few keyframes representing distinct animal poses -- generated via text-to-image prompting or GPT-4o -- we formulate dance synthesis as a graph optimization problem: find the optimal keyframe structure that satisfies a specified choreography pattern of beats, which can be automatically estimated from a reference dance video. We also introduce an approach for mirrored pose image generation, essential for capturing symmetry in dance. In-between frames are synthesized using an video diffusion model. With as few as six input keyframes, our method can produce up to 30 second dance videos across a wide range of animals and music tracks.
Generative Powers of Ten
Dec 04, 2023We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
Animating Street View
Oct 12, 2023We present a system that automatically brings street view imagery to life by populating it with naturally behaving, animated pedestrians and vehicles. Our approach is to remove existing people and vehicles from the input image, insert moving objects with proper scale, angle, motion, and appearance, plan paths and traffic behavior, as well as render the scene with plausible occlusion and shadowing effects. The system achieves these by reconstructing the still image street scene, simulating crowd behavior, and rendering with consistent lighting, visibility, occlusions, and shadows. We demonstrate results on a diverse range of street scenes including regular still images and panoramas.
Total Selfie: Generating Full-Body Selfies
Aug 28, 2023



We present a method to generate full-body selfies -- photos that you take of yourself, but capturing your whole body as if someone else took the photo of you from a few feet away. Our approach takes as input a pre-captured video of your body, a target pose photo, and a selfie + background pair for each location. We introduce a novel diffusion-based approach to combine all of this information into high quality, well-composed photos of you with the desired pose and background.
A Light Stage on Every Desk
May 17, 2021
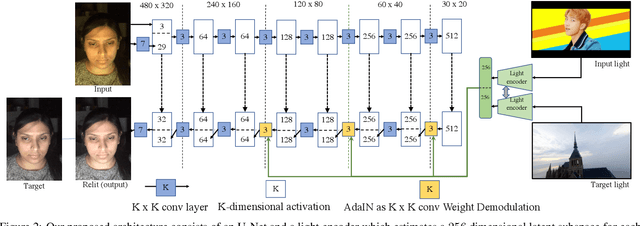
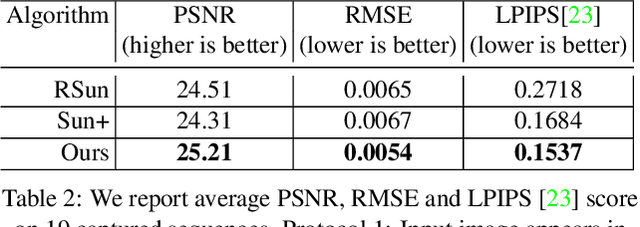
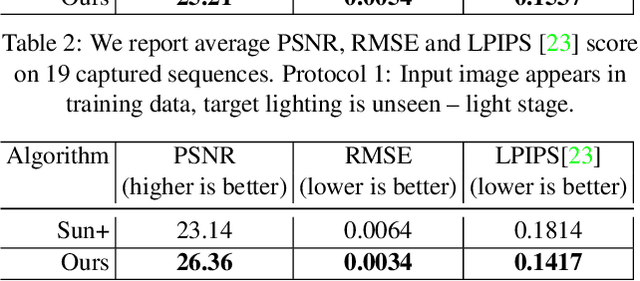
Every time you sit in front of a TV or monitor, your face is actively illuminated by time-varying patterns of light. This paper proposes to use this time-varying illumination for synthetic relighting of your face with any new illumination condition. In doing so, we take inspiration from the light stage work of Debevec et al., who first demonstrated the ability to relight people captured in a controlled lighting environment. Whereas existing light stages require expensive, room-scale spherical capture gantries and exist in only a few labs in the world, we demonstrate how to acquire useful data from a normal TV or desktop monitor. Instead of subjecting the user to uncomfortable rapidly flashing light patterns, we operate on images of the user watching a YouTube video or other standard content. We train a deep network on images plus monitor patterns of a given user and learn to predict images of that user under any target illumination (monitor pattern). Experimental evaluation shows that our method produces realistic relighting results. Video results are available at http://grail.cs.washington.edu/projects/Light_Stage_on_Every_Desk/.
Real-Time High-Resolution Background Matting
Dec 14, 2020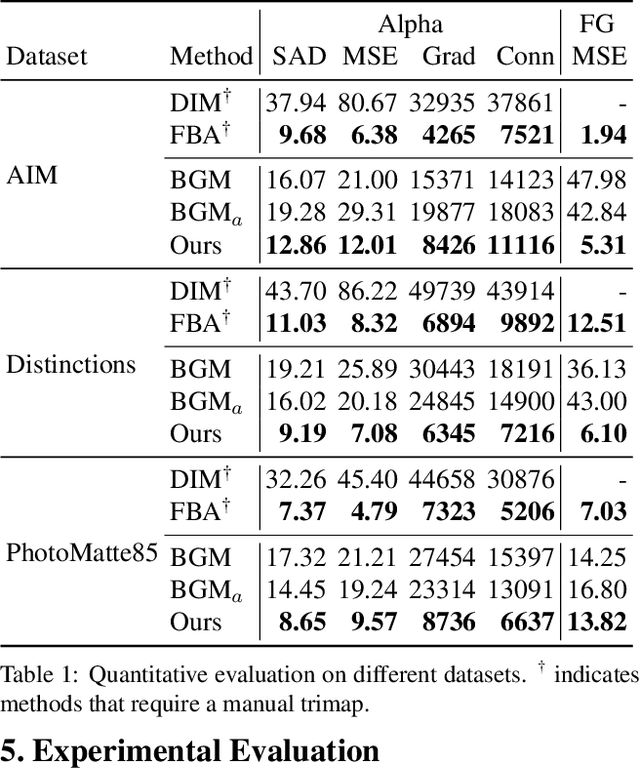

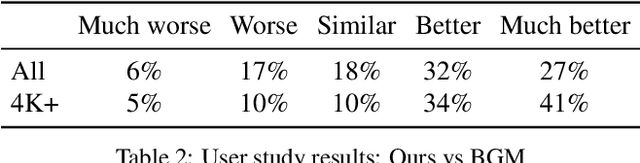
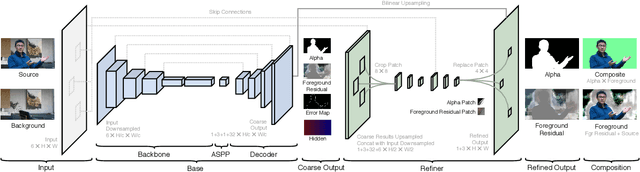
We introduce a real-time, high-resolution background replacement technique which operates at 30fps in 4K resolution, and 60fps for HD on a modern GPU. Our technique is based on background matting, where an additional frame of the background is captured and used in recovering the alpha matte and the foreground layer. The main challenge is to compute a high-quality alpha matte, preserving strand-level hair details, while processing high-resolution images in real-time. To achieve this goal, we employ two neural networks; a base network computes a low-resolution result which is refined by a second network operating at high-resolution on selective patches. We introduce two largescale video and image matting datasets: VideoMatte240K and PhotoMatte13K/85. Our approach yields higher quality results compared to the previous state-of-the-art in background matting, while simultaneously yielding a dramatic boost in both speed and resolution.
The Cone of Silence: Speech Separation by Localization
Oct 12, 2020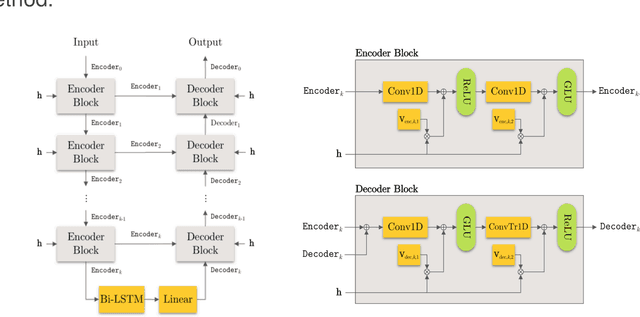
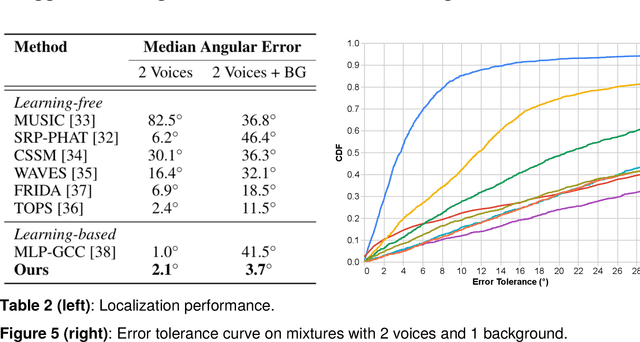
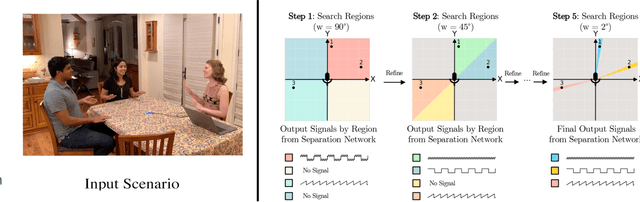
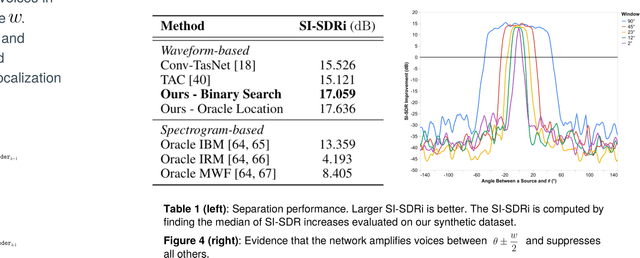
Given a multi-microphone recording of an unknown number of speakers talking concurrently, we simultaneously localize the sources and separate the individual speakers. At the core of our method is a deep network, in the waveform domain, which isolates sources within an angular region $\theta \pm w/2$, given an angle of interest $\theta$ and angular window size $w$. By exponentially decreasing $w$, we can perform a binary search to localize and separate all sources in logarithmic time. Our algorithm allows for an arbitrary number of potentially moving speakers at test time, including more speakers than seen during training. Experiments demonstrate state-of-the-art performance for both source separation and source localization, particularly in high levels of background noise.
Reconstructing NBA Players
Jul 27, 2020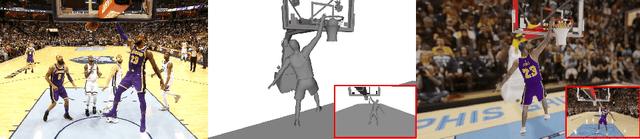

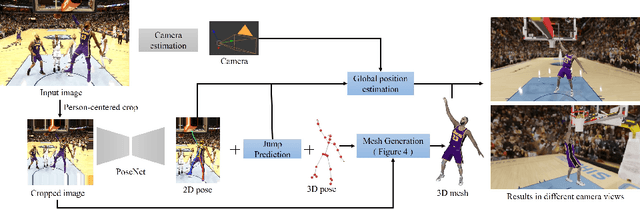

Great progress has been made in 3D body pose and shape estimation from a single photo. Yet, state-of-the-art results still suffer from errors due to challenging body poses, modeling clothing, and self occlusions. The domain of basketball games is particularly challenging, as it exhibits all of these challenges. In this paper, we introduce a new approach for reconstruction of basketball players that outperforms the state-of-the-art. Key to our approach is a new method for creating poseable, skinned models of NBA players, and a large database of meshes (derived from the NBA2K19 video game), that we are releasing to the research community. Based on these models, we introduce a new method that takes as input a single photo of a clothed player in any basketball pose and outputs a high resolution mesh and 3D pose for that player. We demonstrate substantial improvement over state-of-the-art, single-image methods for body shape reconstruction.
People as Scene Probes
Jul 17, 2020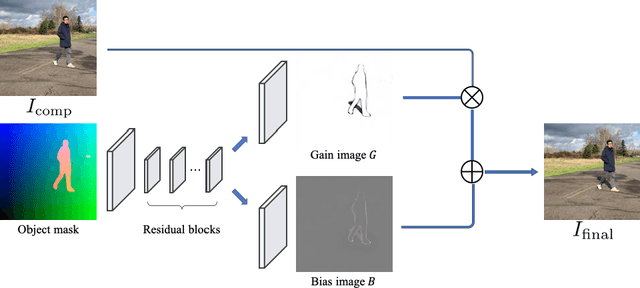


By analyzing the motion of people and other objects in a scene, we demonstrate how to infer depth, occlusion, lighting, and shadow information from video taken from a single camera viewpoint. This information is then used to composite new objects into the same scene with a high degree of automation and realism. In particular, when a user places a new object (2D cut-out) in the image, it is automatically rescaled, relit, occluded properly, and casts realistic shadows in the correct direction relative to the sun, and which conform properly to scene geometry. We demonstrate results (best viewed in supplementary video) on a range of scenes and compare to alternative methods for depth estimation and shadow compositing.