 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraZoom: Generating Gigapixel Images from Regular Photos
Jun 16, 2025We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
Constrained Diffusion Implicit Models
Nov 01, 2024



This paper describes an efficient algorithm for solving noisy linear inverse problems using pretrained diffusion models. Extending the paradigm of denoising diffusion implicit models (DDIM), we propose constrained diffusion implicit models (CDIM) that modify the diffusion updates to enforce a constraint upon the final output. For noiseless inverse problems, CDIM exactly satisfies the constraints; in the noisy case, we generalize CDIM to satisfy an exact constraint on the residual distribution of the noise. Experiments across a variety of tasks and metrics show strong performance of CDIM, with analogous inference acceleration to unconstrained DDIM: 10 to 50 times faster than previous conditional diffusion methods. We demonstrate the versatility of our approach on many problems including super-resolution, denoising, inpainting, deblurring, and 3D point cloud reconstruction.
HRTF Estimation in the Wild
Nov 06, 2023



Head Related Transfer Functions (HRTFs) play a crucial role in creating immersive spatial audio experiences. However, HRTFs differ significantly from person to person, and traditional methods for estimating personalized HRTFs are expensive, time-consuming, and require specialized equipment. We imagine a world where your personalized HRTF can be determined by capturing data through earbuds in everyday environments. In this paper, we propose a novel approach for deriving personalized HRTFs that only relies on in-the-wild binaural recordings and head tracking data. By analyzing how sounds change as the user rotates their head through different environments with different noise sources, we can accurately estimate their personalized HRTF. Our results show that our predicted HRTFs closely match ground-truth HRTFs measured in an anechoic chamber. Furthermore, listening studies demonstrate that our personalized HRTFs significantly improve sound localization and reduce front-back confusion in virtual environments. Our approach offers an efficient and accessible method for deriving personalized HRTFs and has the potential to greatly improve spatial audio experiences.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022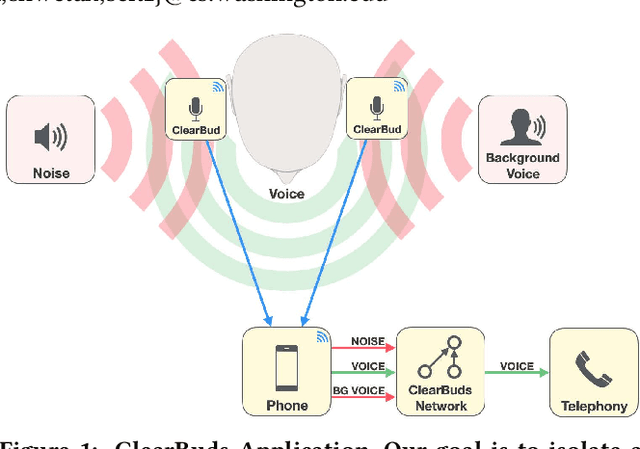

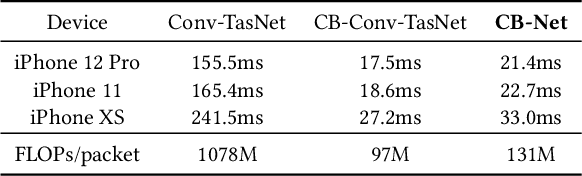
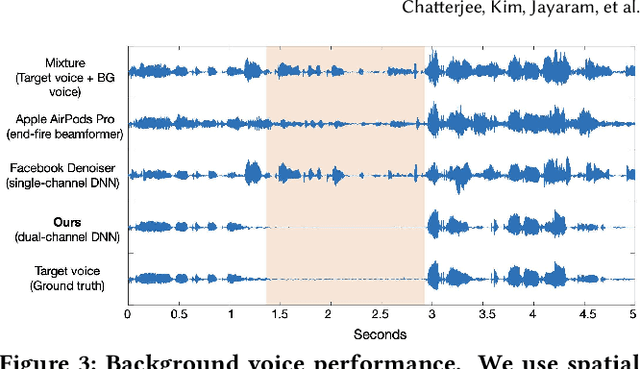
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
Parallel and Flexible Sampling from Autoregressive Models via Langevin Dynamics
May 17, 2021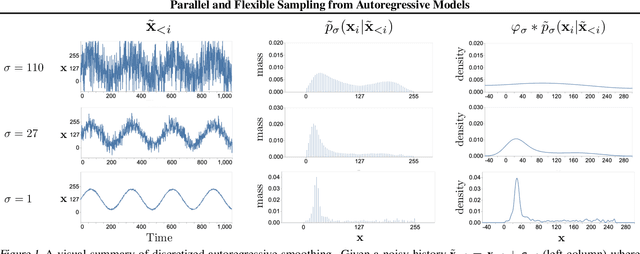
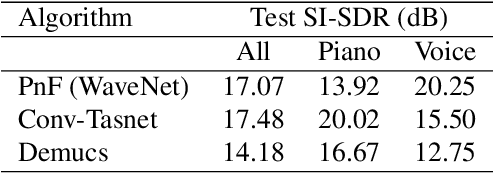
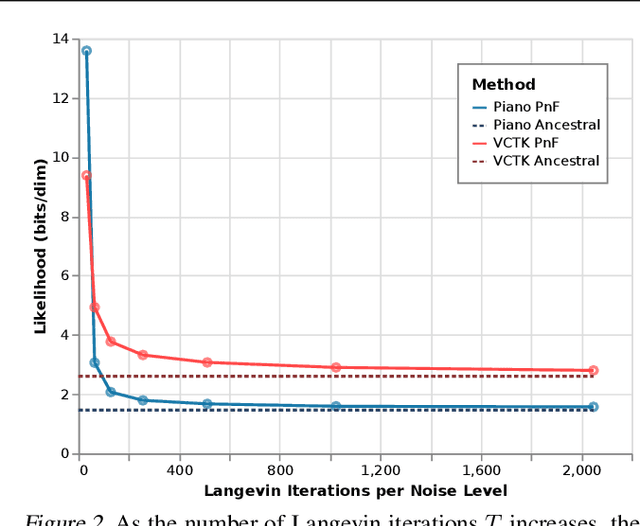
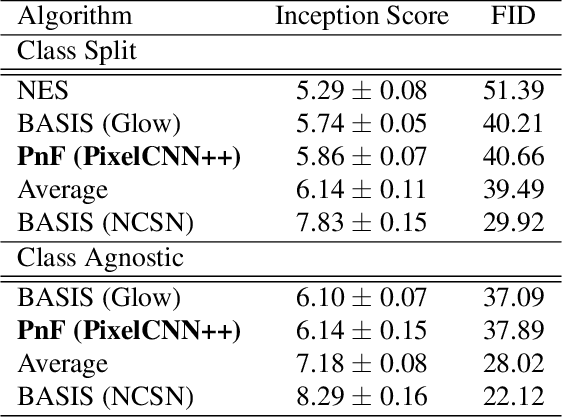
This paper introduces an alternative approach to sampling from autoregressive models. Autoregressive models are typically sampled sequentially, according to the transition dynamics defined by the model. Instead, we propose a sampling procedure that initializes a sequence with white noise and follows a Markov chain defined by Langevin dynamics on the global log-likelihood of the sequence. This approach parallelizes the sampling process and generalizes to conditional sampling. Using an autoregressive model as a Bayesian prior, we can steer the output of a generative model using a conditional likelihood or constraints. We apply these techniques to autoregressive models in the visual and audio domains, with competitive results for audio source separation, super-resolution, and inpainting.
The Cone of Silence: Speech Separation by Localization
Oct 12, 2020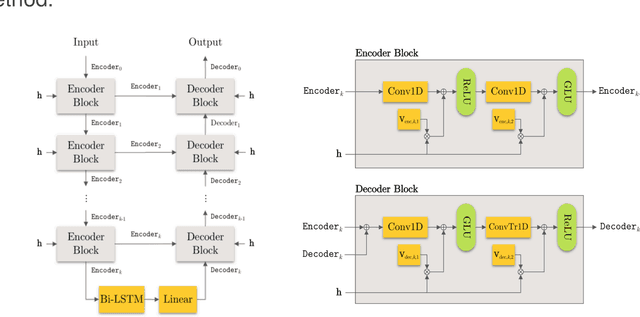
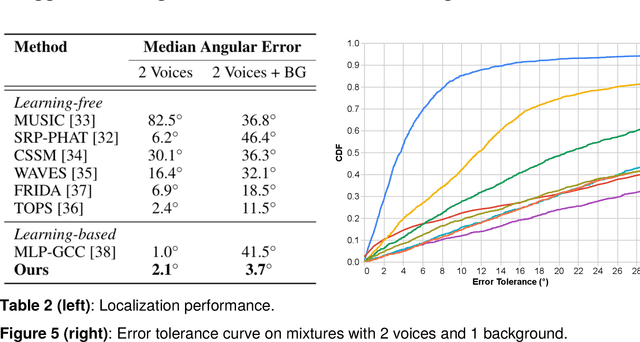
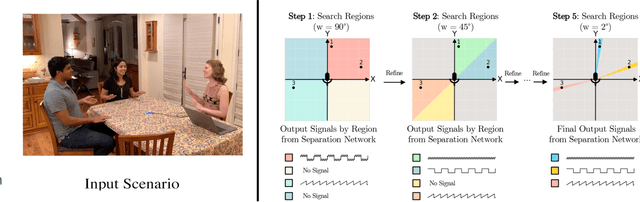
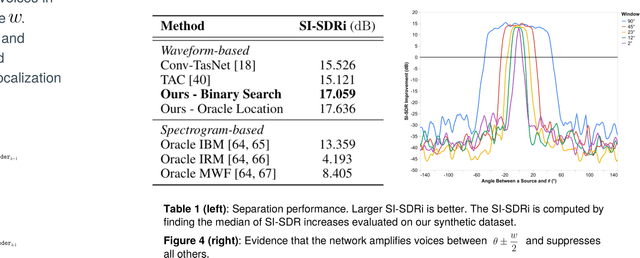
Given a multi-microphone recording of an unknown number of speakers talking concurrently, we simultaneously localize the sources and separate the individual speakers. At the core of our method is a deep network, in the waveform domain, which isolates sources within an angular region $\theta \pm w/2$, given an angle of interest $\theta$ and angular window size $w$. By exponentially decreasing $w$, we can perform a binary search to localize and separate all sources in logarithmic time. Our algorithm allows for an arbitrary number of potentially moving speakers at test time, including more speakers than seen during training. Experiments demonstrate state-of-the-art performance for both source separation and source localization, particularly in high levels of background noise.
Background Matting: The World is Your Green Screen
Apr 10, 2020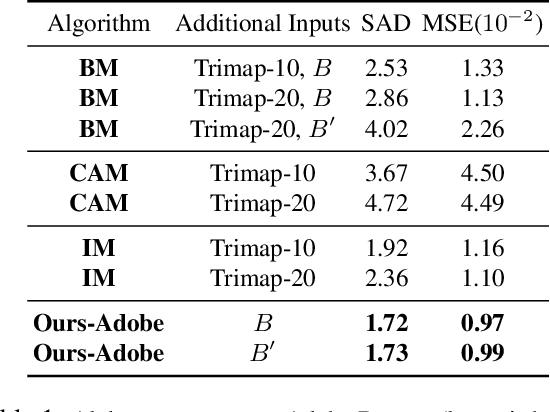
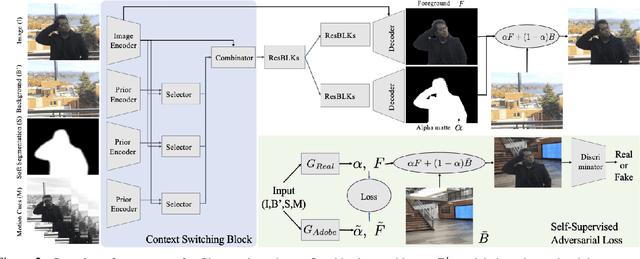
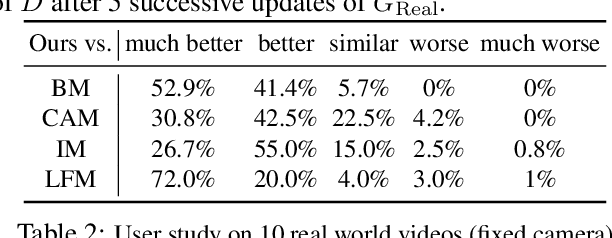

We propose a method for creating a matte -- the per-pixel foreground color and alpha -- of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte. Automatic, trimap-free methods are appearing, but are not of comparable quality. In our trimap free approach, we ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less time-consuming than creating a trimap. We train a deep network with an adversarial loss to predict the matte. We first train a matting network with supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, we train another matting network guided by the first network and by a discriminator that judges the quality of composites. We demonstrate results on a wide variety of photos and videos and show significant improvement over the state of the art.
Real-Time Camera Pose Estimation for Sports Fields
Mar 31, 2020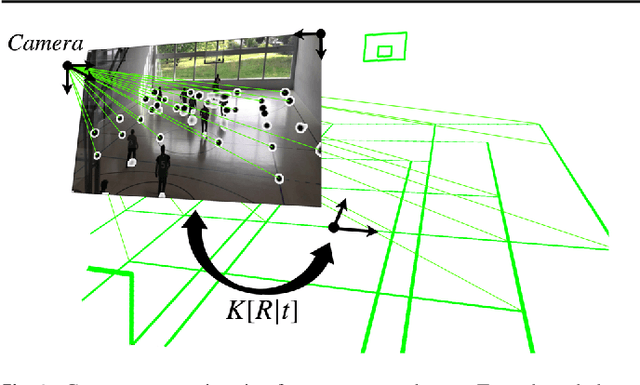
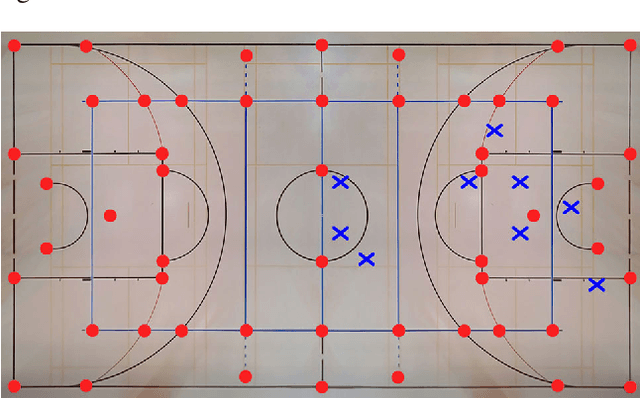
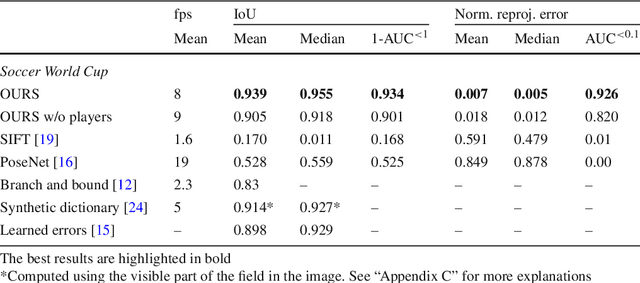
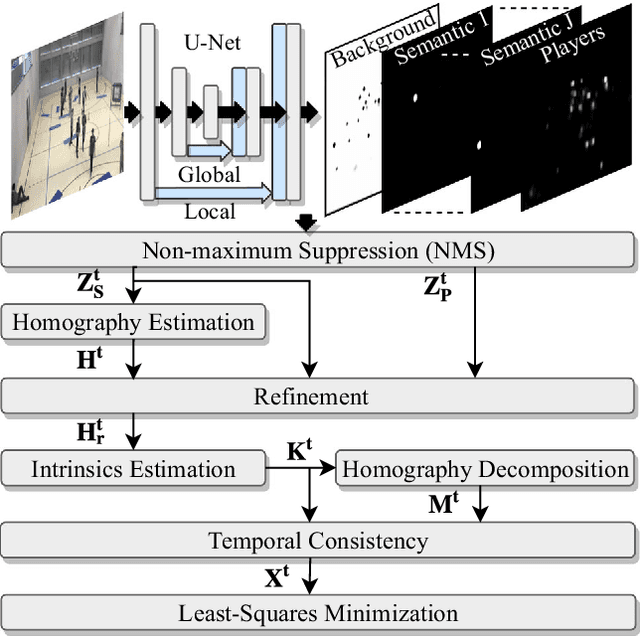
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera. To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture. Our algorithm exploits both the field lines and the players' image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art. We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.
Source Separation with Deep Generative Priors
Feb 19, 2020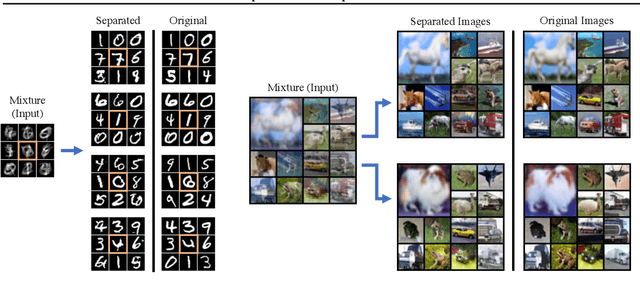
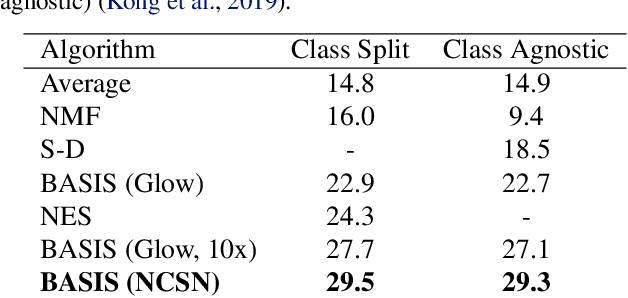
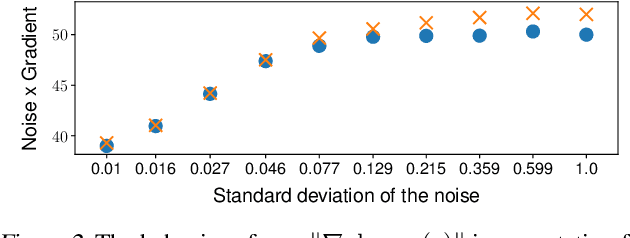
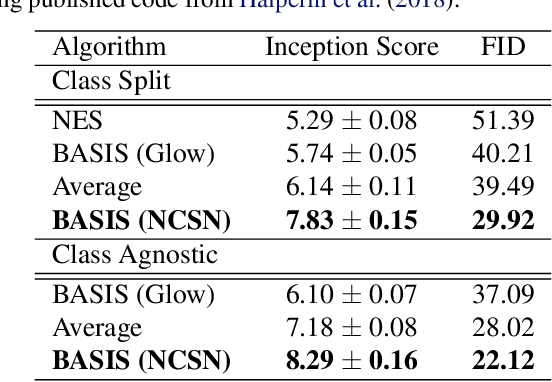
Despite substantial progress in signal source separation, results for richly structured data continue to contain perceptible artifacts. In contrast, recent deep generative models can produce authentic samples in a variety of domains that are indistinguishable from samples of the data distribution. This paper introduces a Bayesian approach to source separation that uses generative models as priors over the components of a mixture of sources, and Langevin dynamics to sample from the posterior distribution of sources given a mixture. This decouples the source separation problem from generative modeling, enabling us to directly use cutting-edge generative models as priors. The method achieves state-of-the-art performance for MNIST digit separation. We introduce new methodology for evaluating separation quality on richer datasets, providing quantitative evaluation of separation results on CIFAR-10. We also provide qualitative results on LSUN.