 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation
Mar 29, 2022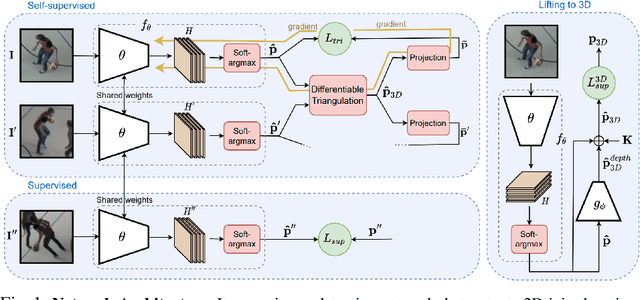

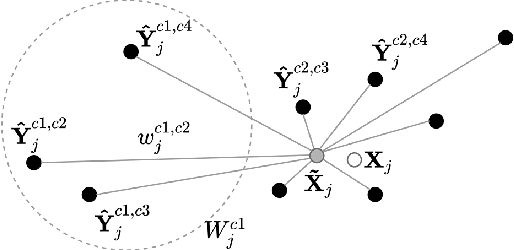
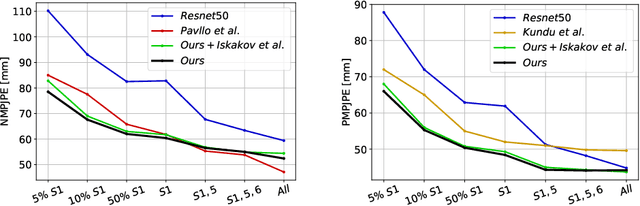
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self-occlusion or occlusion from other subjects. Our experimental results on Human3.6M and MPI-INF-3DHP substantiate the significance of our weighting strategy where we obtain state-of-the-art results in the semi and weakly supervised learning setup. We also contribute a new multi-player sports dataset that features occlusion, and show the effectiveness of our algorithm over baseline triangulation methods.
Adjusting the Ground Truth Annotations for Connectivity-Based Learning to Delineate
Dec 06, 2021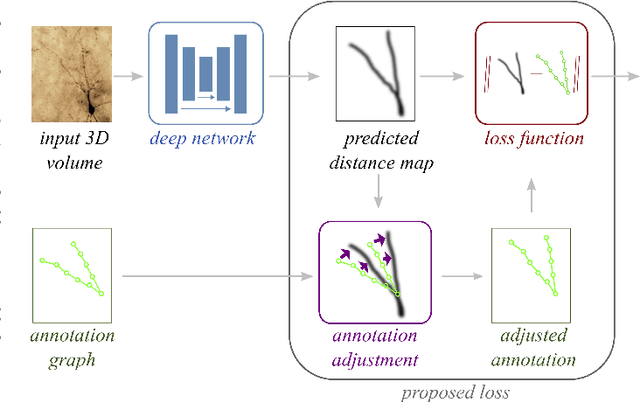
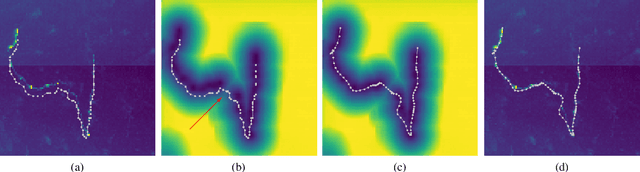
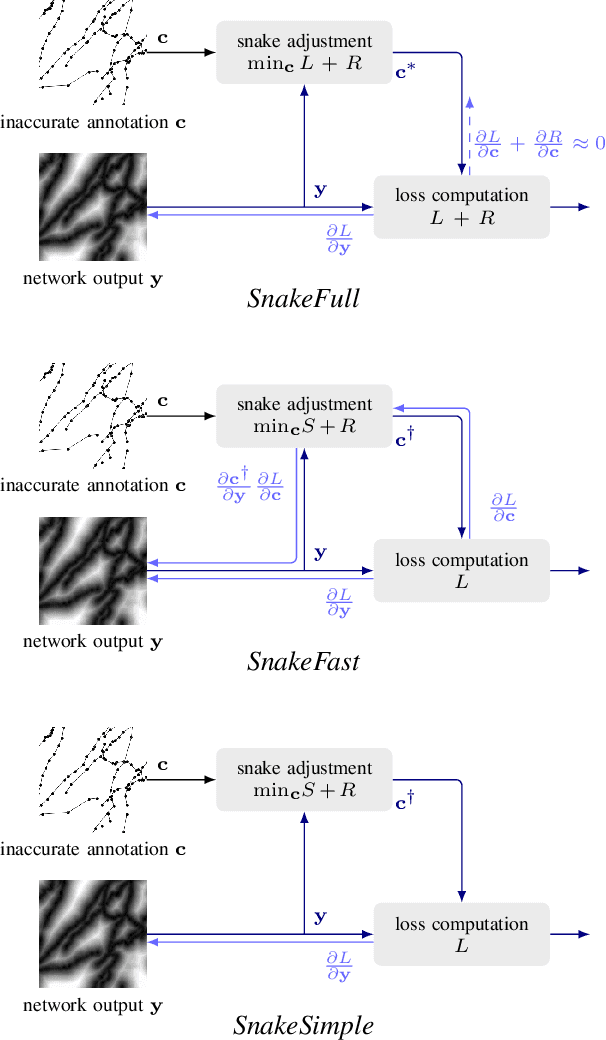

Deep learning-based approaches to delineating 3D structure depend on accurate annotations to train the networks. Yet, in practice, people, no matter how conscientious, have trouble precisely delineating in 3D and on a large scale, in part because the data is often hard to interpret visually and in part because the 3D interfaces are awkward to use. In this paper, we introduce a method that explicitly accounts for annotation inaccuracies. To this end, we treat the annotations as active contour models that can deform themselves while preserving their topology. This enables us to jointly train the network and correct potential errors in the original annotations. The result is an approach that boosts performance of deep networks trained with potentially inaccurate annotations.
Promoting Connectivity of Network-Like Structures by Enforcing Region Separation
Sep 15, 2020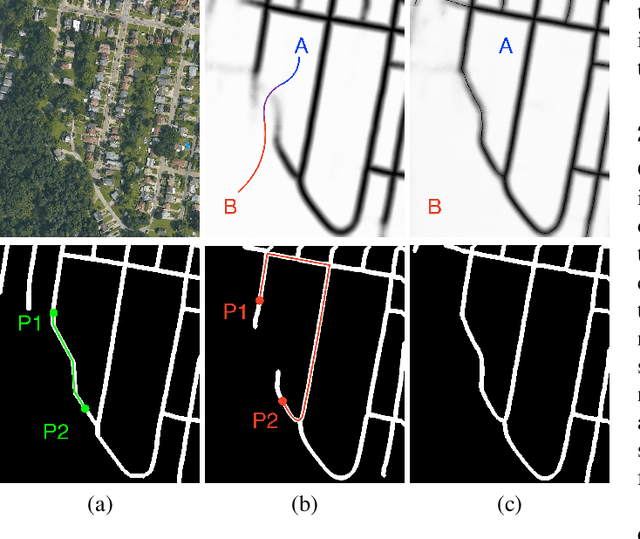
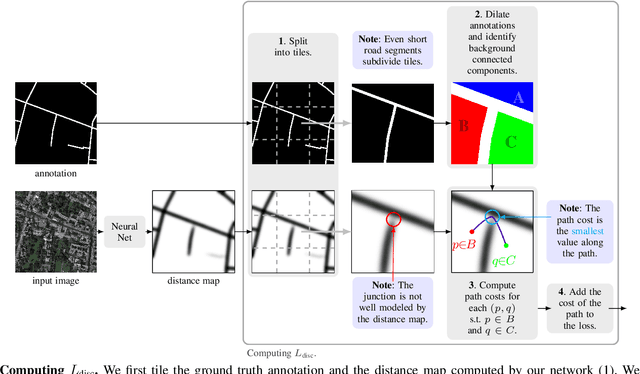
We propose a novel, connectivity-oriented loss function for training deep convolutional networks to reconstruct network-like structures, like roads and irrigation canals, from aerial images. The main idea behind our loss is to express the connectivity of roads, or canals, in terms of disconnections that they create between background regions of the image. In simple terms, a gap in the predicted road causes two background regions, that lie on the opposite sides of a ground truth road, to touch in prediction. Our loss function is designed to prevent such unwanted connections between background regions, and therefore close the gaps in predicted roads. It also prevents predicting false positive roads and canals by penalizing unwarranted disconnections of background regions. In order to capture even short, dead-ending road segments, we evaluate the loss in small image crops. We show, in experiments on two standard road benchmarks and a new data set of irrigation canals, that convnets trained with our loss function recover road connectivity so well, that it suffices to skeletonize their output to produce state of the art maps. A distinct advantage of our approach is that the loss can be plugged in to any existing training setup without further modifications.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020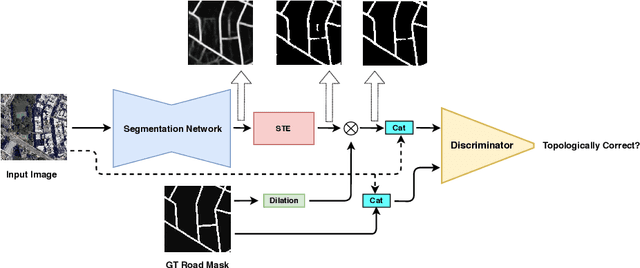



Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
Real-Time Camera Pose Estimation for Sports Fields
Mar 31, 2020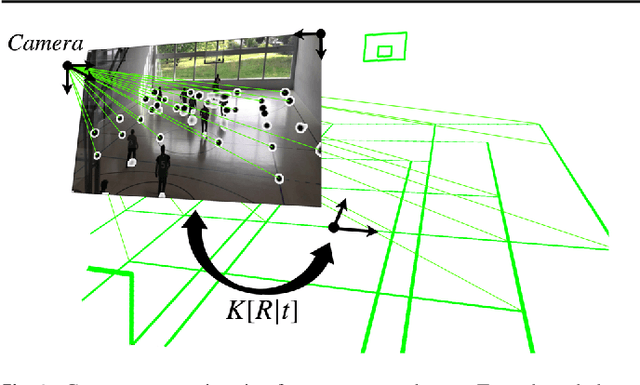
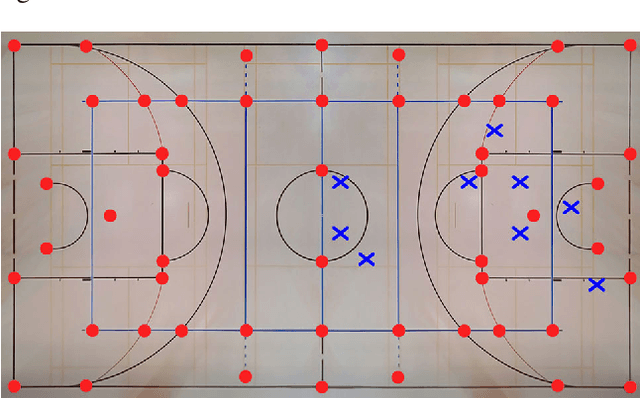
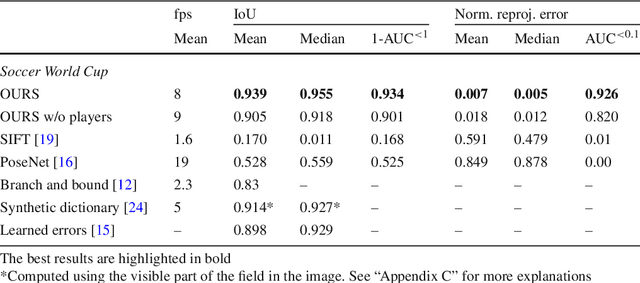
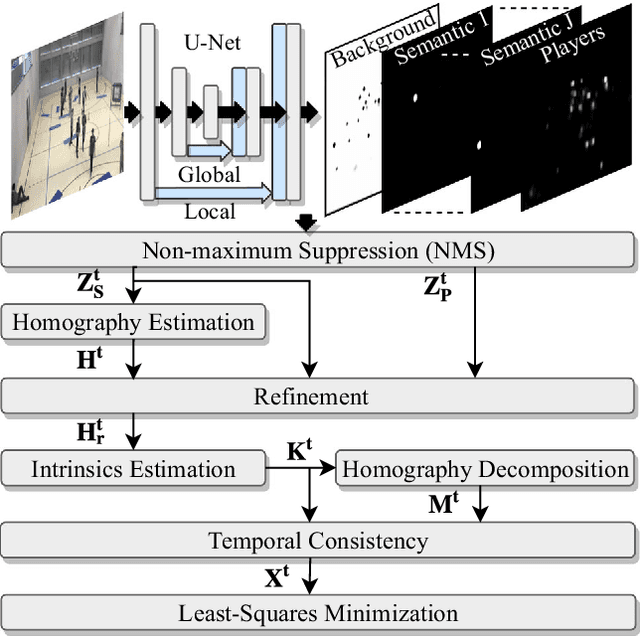
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera. To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture. Our algorithm exploits both the field lines and the players' image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art. We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.
Towards Reliable Evaluation of Road Network Reconstructions
Nov 28, 2019



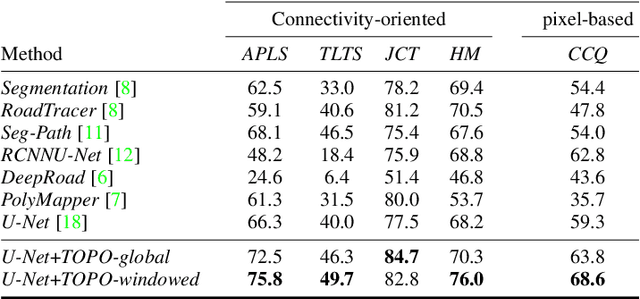
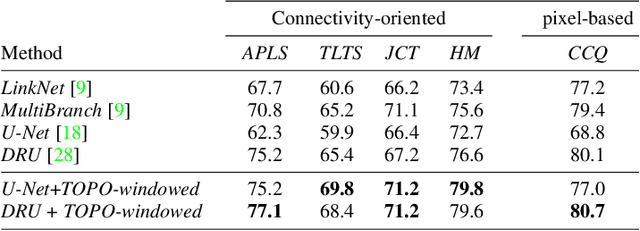
Existing performance measures rank delineation algorithms inconsistently, which makes it difficult to decide which one is best in any given situation. We show that these inconsistencies stem from design flaws that make the metrics insensitive to whole classes of errors. To provide more reliable evaluation, we design three new metrics that are far more consistent even though they use very different approaches to comparing ground-truth and reconstructed road networks. We use both synthetic and real data to demonstrate this and advocate the use of these corrected metrics as a tool to gauge future progress.