 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation
Paper and Code
Mar 29, 2022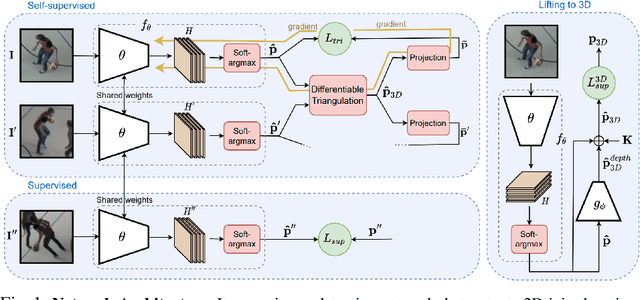

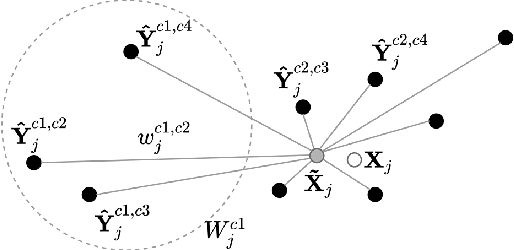
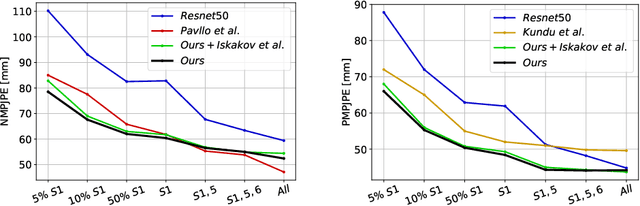
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self-occlusion or occlusion from other subjects. Our experimental results on Human3.6M and MPI-INF-3DHP substantiate the significance of our weighting strategy where we obtain state-of-the-art results in the semi and weakly supervised learning setup. We also contribute a new multi-player sports dataset that features occlusion, and show the effectiveness of our algorithm over baseline triangulation methods.