 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysMoDPO: Physically-Plausible Humanoid Motion with Preference Optimization
Mar 16, 2026Recent progress in text-conditioned human motion generation has been largely driven by diffusion models trained on large-scale human motion data. Building on this progress, recent methods attempt to transfer such models for character animation and real robot control by applying a Whole-Body Controller (WBC) that converts diffusion-generated motions into executable trajectories. While WBC trajectories become compliant with physics, they may expose substantial deviations from original motion. To address this issue, we here propose PhysMoDPO, a Direct Preference Optimization framework. Unlike prior work that relies on hand-crafted physics-aware heuristics such as foot-sliding penalties, we integrate WBC into our training pipeline and optimize diffusion model such that the output of WBC becomes compliant both with physics and original text instructions. To train PhysMoDPO we deploy physics-based and task-specific rewards and use them to assign preference to synthesized trajectories. Our extensive experiments on text-to-motion and spatial control tasks demonstrate consistent improvements of PhysMoDPO in both physical realism and task-related metrics on simulated robots. Moreover, we demonstrate that PhysMoDPO results in significant improvements when applied to zero-shot motion transfer in simulation and for real-world deployment on a G1 humanoid robot.
Automated Counting of Stacked Objects in Industrial Inspection
Mar 16, 2026Visual object counting is a fundamental computer vision task in industrial inspection, where accurate, high-throughput inventory tracking and quality assurance are critical. Moreover, manufactured parts are often too light to reliably deduce their count from their weight, or too heavy to move the stack on a scale safely and practically, making automated visual counting the more robust solution in many scenarios. However, existing methods struggle with stacked 3D items in containers, pallets, or bins, where most objects are heavily occluded and only a few are directly visible. To address this important yet underexplored challenge, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems: estimating the 3D geometry of the stack and its occupancy ratio from multi-view images. By combining geometric reconstruction with deep learning-based depth analysis, our method can accurately count identical manufactured parts inside containers, even when they are irregularly stacked and partially hidden. We validate our 3D counting pipeline on large-scale synthetic and diverse real-world data with manually verified total counts, demonstrating robust performance under realistic inspection conditions.
Spatio-Temporal Garment Reconstruction Using Diffusion Mapping via Pattern Coordinates
Feb 27, 2026Reconstructing 3D clothed humans from monocular images and videos is a fundamental problem with applications in virtual try-on, avatar creation, and mixed reality. Despite significant progress in human body recovery, accurately reconstructing garment geometry, particularly for loose-fitting clothing, remains an open challenge. We propose a unified framework for high-fidelity 3D garment reconstruction from both single images and video sequences. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn expressive garment shape priors in 2D UV space. Leveraging these priors, we introduce a mapping model that establishes correspondences between image pixels, UV pattern coordinates, and 3D geometry, enabling accurate and detailed garment reconstruction from single images. We further extend this formulation to dynamic reconstruction by introducing a spatio-temporal diffusion scheme with test-time guidance to enforce long-range temporal consistency. We also develop analytic projection-based constraints that preserve image-aligned geometry in visible regions while enforcing coherent completion in occluded areas over time. Although trained exclusively on synthetically simulated cloth data, our method generalizes well to real-world imagery and consistently outperforms existing approaches on both tight- and loose-fitting garments. The reconstructed garments preserve fine geometric detail while exhibiting realistic dynamic motion, supporting downstream applications such as texture editing, garment retargeting, and animation.
SuperPoint-E: local features for 3D reconstruction via tracking adaptation in endoscopy
Feb 04, 2026In this work, we focus on boosting the feature extraction to improve the performance of Structure-from-Motion (SfM) in endoscopy videos. We present SuperPoint-E, a new local feature extraction method that, using our proposed Tracking Adaptation supervision strategy, significantly improves the quality of feature detection and description in endoscopy. Extensive experimentation on real endoscopy recordings studies our approach's most suitable configuration and evaluates SuperPoint-E feature quality. The comparison with other baselines also shows that our 3D reconstructions are denser and cover more and longer video segments because our detector fires more densely and our features are more likely to survive (i.e. higher detection precision). In addition, our descriptor is more discriminative, making the guided matching step almost redundant. The presented approach brings significant improvements in the 3D reconstructions obtained, via SfM on endoscopy videos, compared to the original SuperPoint and the gold standard SfM COLMAP pipeline.
Single View Garment Reconstruction Using Diffusion Mapping Via Pattern Coordinates
Apr 11, 2025Reconstructing 3D clothed humans from images is fundamental to applications like virtual try-on, avatar creation, and mixed reality. While recent advances have enhanced human body recovery, accurate reconstruction of garment geometry -- especially for loose-fitting clothing -- remains an open challenge. We present a novel method for high-fidelity 3D garment reconstruction from single images that bridges 2D and 3D representations. Our approach combines Implicit Sewing Patterns (ISP) with a generative diffusion model to learn rich garment shape priors in a 2D UV space. A key innovation is our mapping model that establishes correspondences between 2D image pixels, UV pattern coordinates, and 3D geometry, enabling joint optimization of both 3D garment meshes and the corresponding 2D patterns by aligning learned priors with image observations. Despite training exclusively on synthetically simulated cloth data, our method generalizes effectively to real-world images, outperforming existing approaches on both tight- and loose-fitting garments. The reconstructed garments maintain physical plausibility while capturing fine geometric details, enabling downstream applications including garment retargeting and texture manipulation.
Do you understand epistemic uncertainty? Think again! Rigorous frequentist epistemic uncertainty estimation in regression
Mar 17, 2025Quantifying model uncertainty is critical for understanding prediction reliability, yet distinguishing between aleatoric and epistemic uncertainty remains challenging. We extend recent work from classification to regression to provide a novel frequentist approach to epistemic and aleatoric uncertainty estimation. We train models to generate conditional predictions by feeding their initial output back as an additional input. This method allows for a rigorous measurement of model uncertainty by observing how prediction responses change when conditioned on the model's previous answer. We provide a complete theoretical framework to analyze epistemic uncertainty in regression in a frequentist way, and explain how it can be exploited in practice to gauge a model's uncertainty, with minimal changes to the original architecture.
D3DR: Lighting-Aware Object Insertion in Gaussian Splatting
Mar 09, 2025Gaussian Splatting has become a popular technique for various 3D Computer Vision tasks, including novel view synthesis, scene reconstruction, and dynamic scene rendering. However, the challenge of natural-looking object insertion, where the object's appearance seamlessly matches the scene, remains unsolved. In this work, we propose a method, dubbed D3DR, for inserting a 3DGS-parametrized object into 3DGS scenes while correcting its lighting, shadows, and other visual artifacts to ensure consistency, a problem that has not been successfully addressed before. We leverage advances in diffusion models, which, trained on real-world data, implicitly understand correct scene lighting. After inserting the object, we optimize a diffusion-based Delta Denoising Score (DDS)-inspired objective to adjust its 3D Gaussian parameters for proper lighting correction. Utilizing diffusion model personalization techniques to improve optimization quality, our approach ensures seamless object insertion and natural appearance. Finally, we demonstrate the method's effectiveness by comparing it to existing approaches, achieving 0.5 PSNR and 0.15 SSIM improvements in relighting quality.
DiffAtlas: GenAI-fying Atlas Segmentation via Image-Mask Diffusion
Mar 09, 2025Accurate medical image segmentation is crucial for precise anatomical delineation. Deep learning models like U-Net have shown great success but depend heavily on large datasets and struggle with domain shifts, complex structures, and limited training samples. Recent studies have explored diffusion models for segmentation by iteratively refining masks. However, these methods still retain the conventional image-to-mask mapping, making them highly sensitive to input data, which hampers stability and generalization. In contrast, we introduce DiffAtlas, a novel generative framework that models both images and masks through diffusion during training, effectively ``GenAI-fying'' atlas-based segmentation. During testing, the model is guided to generate a specific target image-mask pair, from which the corresponding mask is obtained. DiffAtlas retains the robustness of the atlas paradigm while overcoming its scalability and domain-specific limitations. Extensive experiments on CT and MRI across same-domain, cross-modality, varying-domain, and different data-scale settings using the MMWHS and TotalSegmentator datasets demonstrate that our approach outperforms existing methods, particularly in limited-data and zero-shot modality segmentation. Code is available at https://github.com/M3DV/DiffAtlas.
PartSDF: Part-Based Implicit Neural Representation for Composite 3D Shape Parametrization and Optimization
Feb 18, 2025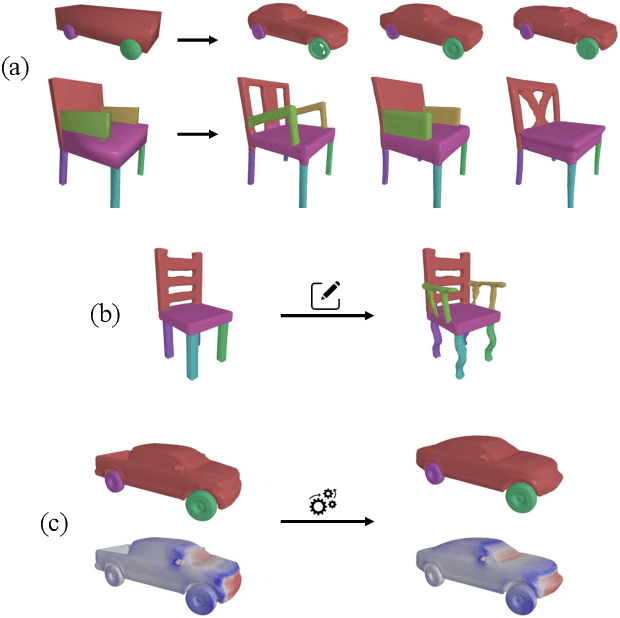
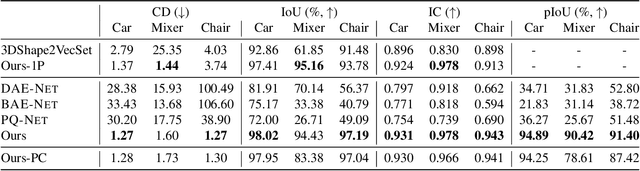
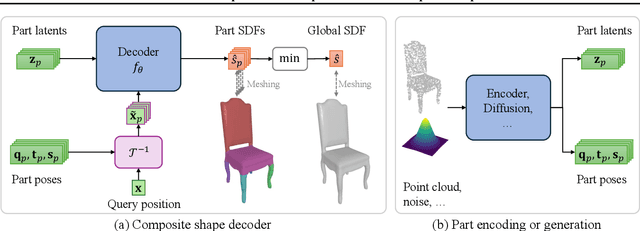
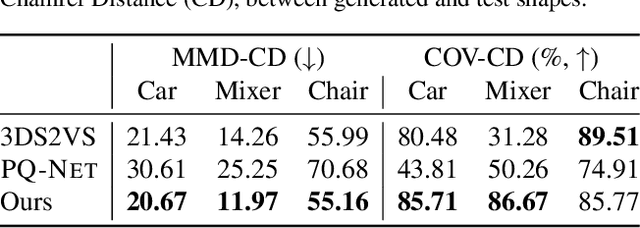
Accurate 3D shape representation is essential in engineering applications such as design, optimization, and simulation. In practice, engineering workflows require structured, part-aware representations, as objects are inherently designed as assemblies of distinct components. However, most existing methods either model shapes holistically or decompose them without predefined part structures, limiting their applicability in real-world design tasks. We propose PartSDF, a supervised implicit representation framework that explicitly models composite shapes with independent, controllable parts while maintaining shape consistency. Despite its simple single-decoder architecture, PartSDF outperforms both supervised and unsupervised baselines in reconstruction and generation tasks. We further demonstrate its effectiveness as a structured shape prior for engineering applications, enabling precise control over individual components while preserving overall coherence. Code available at https://github.com/cvlab-epfl/PartSDF.
Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
Dec 17, 2024



Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.