 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVHOI: Controllable Video Generation of Human-Object Interactions from Sparse Trajectories via Motion Densification
Dec 10, 2025Synthesizing realistic human-object interactions (HOI) in video is challenging due to the complex, instance-specific interaction dynamics of both humans and objects. Incorporating controllability in video generation further adds to the complexity. Existing controllable video generation approaches face a trade-off: sparse controls like keypoint trajectories are easy to specify but lack instance-awareness, while dense signals such as optical flow, depths or 3D meshes are informative but costly to obtain. We propose VHOI, a two-stage framework that first densifies sparse trajectories into HOI mask sequences, and then fine-tunes a video diffusion model conditioned on these dense masks. We introduce a novel HOI-aware motion representation that uses color encodings to distinguish not only human and object motion, but also body-part-specific dynamics. This design incorporates a human prior into the conditioning signal and strengthens the model's ability to understand and generate realistic HOI dynamics. Experiments demonstrate state-of-the-art results in controllable HOI video generation. VHOI is not limited to interaction-only scenarios and can also generate full human navigation leading up to object interactions in an end-to-end manner. Project page: https://vcai.mpi-inf.mpg.de/projects/vhoi/.
Follow My Hold: Hand-Object Interaction Reconstruction through Geometric Guidance
Aug 25, 2025We propose a novel diffusion-based framework for reconstructing 3D geometry of hand-held objects from monocular RGB images by leveraging hand-object interaction as geometric guidance. Our method conditions a latent diffusion model on an inpainted object appearance and uses inference-time guidance to optimize the object reconstruction, while simultaneously ensuring plausible hand-object interactions. Unlike prior methods that rely on extensive post-processing or produce low-quality reconstructions, our approach directly generates high-quality object geometry during the diffusion process by introducing guidance with an optimization-in-the-loop design. Specifically, we guide the diffusion model by applying supervision to the velocity field while simultaneously optimizing the transformations of both the hand and the object being reconstructed. This optimization is driven by multi-modal geometric cues, including normal and depth alignment, silhouette consistency, and 2D keypoint reprojection. We further incorporate signed distance field supervision and enforce contact and non-intersection constraints to ensure physical plausibility of hand-object interaction. Our method yields accurate, robust and coherent reconstructions under occlusion while generalizing well to in-the-wild scenarios.
Physics-based Human Pose Estimation from a Single Moving RGB Camera
Jul 23, 2025Most monocular and physics-based human pose tracking methods, while achieving state-of-the-art results, suffer from artifacts when the scene does not have a strictly flat ground plane or when the camera is moving. Moreover, these methods are often evaluated on in-the-wild real world videos without ground-truth data or on synthetic datasets, which fail to model the real world light transport, camera motion, and pose-induced appearance and geometry changes. To tackle these two problems, we introduce MoviCam, the first non-synthetic dataset containing ground-truth camera trajectories of a dynamically moving monocular RGB camera, scene geometry, and 3D human motion with human-scene contact labels. Additionally, we propose PhysDynPose, a physics-based method that incorporates scene geometry and physical constraints for more accurate human motion tracking in case of camera motion and non-flat scenes. More precisely, we use a state-of-the-art kinematics estimator to obtain the human pose and a robust SLAM method to capture the dynamic camera trajectory, enabling the recovery of the human pose in the world frame. We then refine the kinematic pose estimate using our scene-aware physics optimizer. From our new benchmark, we found that even state-of-the-art methods struggle with this inherently challenging setting, i.e. a moving camera and non-planar environments, while our method robustly estimates both human and camera poses in world coordinates.
Attention (as Discrete-Time Markov) Chains
Jul 23, 2025We introduce a new interpretation of the attention matrix as a discrete-time Markov chain. Our interpretation sheds light on common operations involving attention scores such as selection, summation, and averaging in a unified framework. It further extends them by considering indirect attention, propagated through the Markov chain, as opposed to previous studies that only model immediate effects. Our main observation is that tokens corresponding to semantically similar regions form a set of metastable states, where the attention clusters, while noisy attention scores tend to disperse. Metastable states and their prevalence can be easily computed through simple matrix multiplication and eigenanalysis, respectively. Using these lightweight tools, we demonstrate state-of-the-art zero-shot segmentation. Lastly, we define TokenRank -- the steady state vector of the Markov chain, which measures global token importance. We demonstrate that using it brings improvements in unconditional image generation. We believe our framework offers a fresh view of how tokens are being attended in modern visual transformers.
Ego4o: Egocentric Human Motion Capture and Understanding from Multi-Modal Input
Apr 11, 2025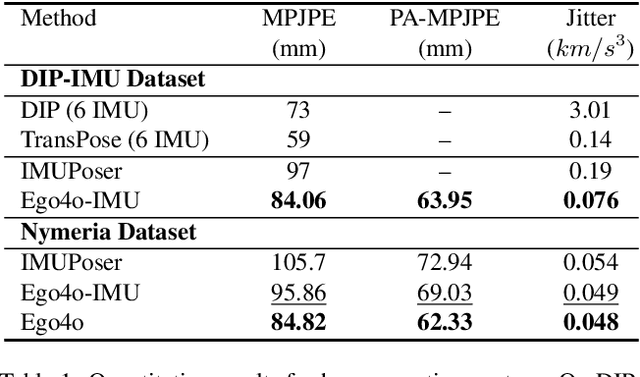
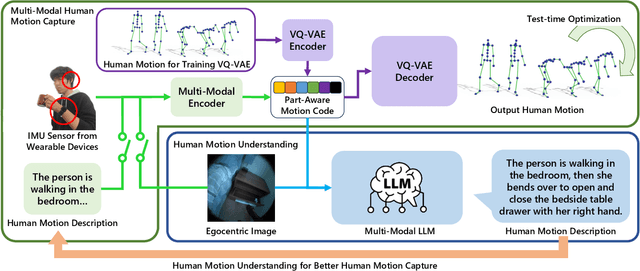

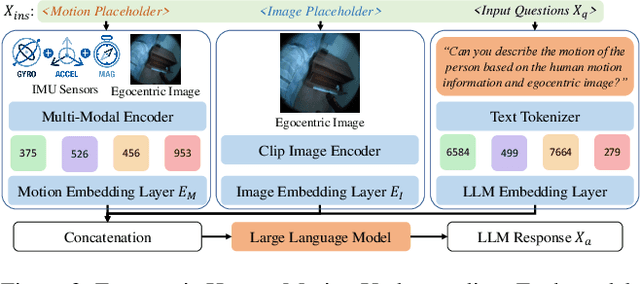
This work focuses on tracking and understanding human motion using consumer wearable devices, such as VR/AR headsets, smart glasses, cellphones, and smartwatches. These devices provide diverse, multi-modal sensor inputs, including egocentric images, and 1-3 sparse IMU sensors in varied combinations. Motion descriptions can also accompany these signals. The diverse input modalities and their intermittent availability pose challenges for consistent motion capture and understanding. In this work, we present Ego4o (o for omni), a new framework for simultaneous human motion capture and understanding from multi-modal egocentric inputs. This method maintains performance with partial inputs while achieving better results when multiple modalities are combined. First, the IMU sensor inputs, the optional egocentric image, and text description of human motion are encoded into the latent space of a motion VQ-VAE. Next, the latent vectors are sent to the VQ-VAE decoder and optimized to track human motion. When motion descriptions are unavailable, the latent vectors can be input into a multi-modal LLM to generate human motion descriptions, which can further enhance motion capture accuracy. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in predicting accurate human motion and high-quality motion descriptions.
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Mar 29, 2025



Egocentric motion capture with a head-mounted body-facing stereo camera is crucial for VR and AR applications but presents significant challenges such as heavy occlusions and limited annotated real-world data. Existing methods rely on synthetic pretraining and struggle to generate smooth and accurate predictions in real-world settings, particularly for lower limbs. Our work addresses these limitations by introducing a lightweight VR-based data collection setup with on-board, real-time 6D pose tracking. Using this setup, we collected the most extensive real-world dataset for ego-facing ego-mounted cameras to date in size and motion variability. Effectively integrating this multimodal input -- device pose and camera feeds -- is challenging due to the differing characteristics of each data source. To address this, we propose FRAME, a simple yet effective architecture that combines device pose and camera feeds for state-of-the-art body pose prediction through geometrically sound multimodal integration and can run at 300 FPS on modern hardware. Lastly, we showcase a novel training strategy to enhance the model's generalization capabilities. Our approach exploits the problem's geometric properties, yielding high-quality motion capture free from common artifacts in prior works. Qualitative and quantitative evaluations, along with extensive comparisons, demonstrate the effectiveness of our method. Data, code, and CAD designs will be available at https://vcai.mpi-inf.mpg.de/projects/FRAME/
3HANDS Dataset: Learning from Humans for Generating Naturalistic Handovers with Supernumerary Robotic Limbs
Mar 06, 2025



Supernumerary robotic limbs (SRLs) are robotic structures integrated closely with the user's body, which augment human physical capabilities and necessitate seamless, naturalistic human-machine interaction. For effective assistance in physical tasks, enabling SRLs to hand over objects to humans is crucial. Yet, designing heuristic-based policies for robots is time-consuming, difficult to generalize across tasks, and results in less human-like motion. When trained with proper datasets, generative models are powerful alternatives for creating naturalistic handover motions. We introduce 3HANDS, a novel dataset of object handover interactions between a participant performing a daily activity and another participant enacting a hip-mounted SRL in a naturalistic manner. 3HANDS captures the unique characteristics of SRL interactions: operating in intimate personal space with asymmetric object origins, implicit motion synchronization, and the user's engagement in a primary task during the handover. To demonstrate the effectiveness of our dataset, we present three models: one that generates naturalistic handover trajectories, another that determines the appropriate handover endpoints, and a third that predicts the moment to initiate a handover. In a user study (N=10), we compare the handover interaction performed with our method compared to a baseline. The findings show that our method was perceived as significantly more natural, less physically demanding, and more comfortable.
Betsu-Betsu: Multi-View Separable 3D Reconstruction of Two Interacting Objects
Feb 19, 2025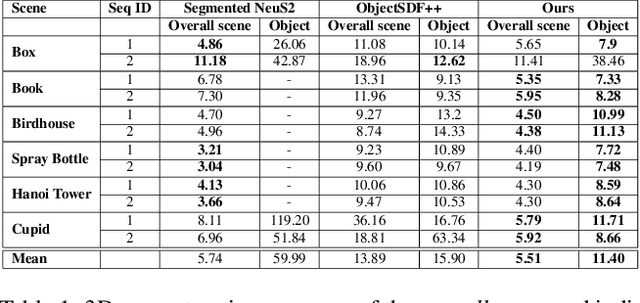
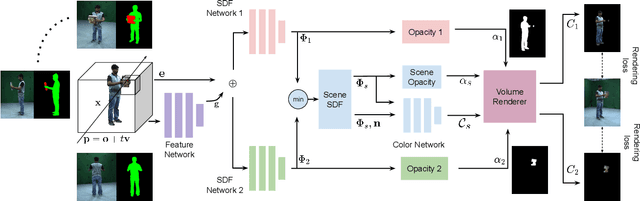
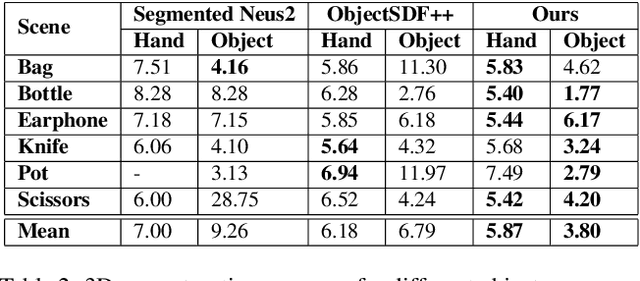
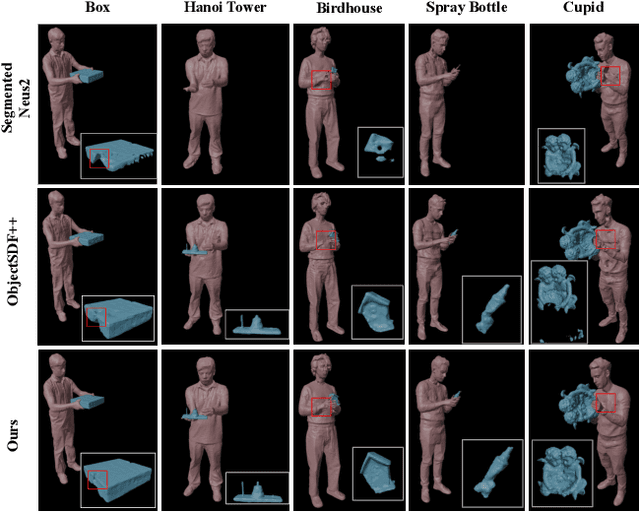
Separable 3D reconstruction of multiple objects from multi-view RGB images -- resulting in two different 3D shapes for the two objects with a clear separation between them -- remains a sparsely researched problem. It is challenging due to severe mutual occlusions and ambiguities along the objects' interaction boundaries. This paper investigates the setting and introduces a new neuro-implicit method that can reconstruct the geometry and appearance of two objects undergoing close interactions while disjoining both in 3D, avoiding surface inter-penetrations and enabling novel-view synthesis of the observed scene. The framework is end-to-end trainable and supervised using a novel alpha-blending regularisation that ensures that the two geometries are well separated even under extreme occlusions. Our reconstruction method is markerless and can be applied to rigid as well as articulated objects. We introduce a new dataset consisting of close interactions between a human and an object and also evaluate on two scenes of humans performing martial arts. The experiments confirm the effectiveness of our framework and substantial improvements using 3D and novel view synthesis metrics compared to several existing approaches applicable in our setting.
Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
Dec 17, 2024



Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
Retrieving Semantics from the Deep: an RAG Solution for Gesture Synthesis
Dec 09, 2024



Non-verbal communication often comprises of semantically rich gestures that help convey the meaning of an utterance. Producing such semantic co-speech gestures has been a major challenge for the existing neural systems that can generate rhythmic beat gestures, but struggle to produce semantically meaningful gestures. Therefore, we present RAG-Gesture, a diffusion-based gesture generation approach that leverages Retrieval Augmented Generation (RAG) to produce natural-looking and semantically rich gestures. Our neuro-explicit gesture generation approach is designed to produce semantic gestures grounded in interpretable linguistic knowledge. We achieve this by using explicit domain knowledge to retrieve exemplar motions from a database of co-speech gestures. Once retrieved, we then inject these semantic exemplar gestures into our diffusion-based gesture generation pipeline using DDIM inversion and retrieval guidance at the inference time without any need of training. Further, we propose a control paradigm for guidance, that allows the users to modulate the amount of influence each retrieval insertion has over the generated sequence. Our comparative evaluations demonstrate the validity of our approach against recent gesture generation approaches. The reader is urged to explore the results on our project page.