 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based Human Pose Estimation from a Single Moving RGB Camera
Jul 23, 2025Most monocular and physics-based human pose tracking methods, while achieving state-of-the-art results, suffer from artifacts when the scene does not have a strictly flat ground plane or when the camera is moving. Moreover, these methods are often evaluated on in-the-wild real world videos without ground-truth data or on synthetic datasets, which fail to model the real world light transport, camera motion, and pose-induced appearance and geometry changes. To tackle these two problems, we introduce MoviCam, the first non-synthetic dataset containing ground-truth camera trajectories of a dynamically moving monocular RGB camera, scene geometry, and 3D human motion with human-scene contact labels. Additionally, we propose PhysDynPose, a physics-based method that incorporates scene geometry and physical constraints for more accurate human motion tracking in case of camera motion and non-flat scenes. More precisely, we use a state-of-the-art kinematics estimator to obtain the human pose and a robust SLAM method to capture the dynamic camera trajectory, enabling the recovery of the human pose in the world frame. We then refine the kinematic pose estimate using our scene-aware physics optimizer. From our new benchmark, we found that even state-of-the-art methods struggle with this inherently challenging setting, i.e. a moving camera and non-planar environments, while our method robustly estimates both human and camera poses in world coordinates.
Ego4o: Egocentric Human Motion Capture and Understanding from Multi-Modal Input
Apr 11, 2025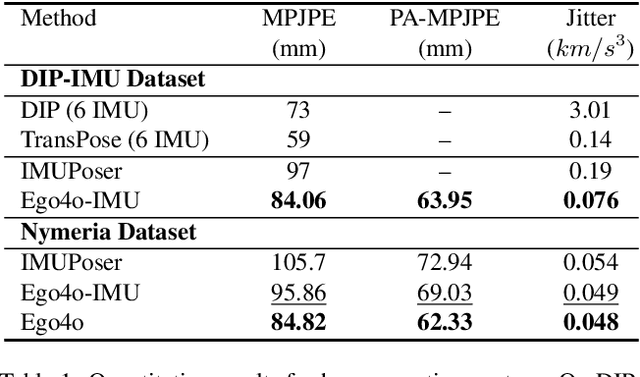
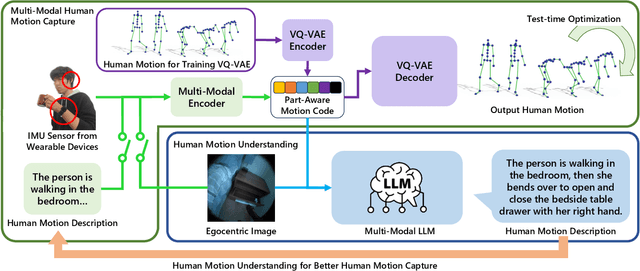

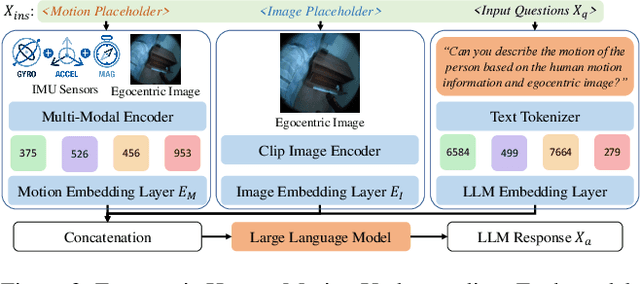
This work focuses on tracking and understanding human motion using consumer wearable devices, such as VR/AR headsets, smart glasses, cellphones, and smartwatches. These devices provide diverse, multi-modal sensor inputs, including egocentric images, and 1-3 sparse IMU sensors in varied combinations. Motion descriptions can also accompany these signals. The diverse input modalities and their intermittent availability pose challenges for consistent motion capture and understanding. In this work, we present Ego4o (o for omni), a new framework for simultaneous human motion capture and understanding from multi-modal egocentric inputs. This method maintains performance with partial inputs while achieving better results when multiple modalities are combined. First, the IMU sensor inputs, the optional egocentric image, and text description of human motion are encoded into the latent space of a motion VQ-VAE. Next, the latent vectors are sent to the VQ-VAE decoder and optimized to track human motion. When motion descriptions are unavailable, the latent vectors can be input into a multi-modal LLM to generate human motion descriptions, which can further enhance motion capture accuracy. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in predicting accurate human motion and high-quality motion descriptions.
EventEgo3D++: 3D Human Motion Capture from a Head-Mounted Event Camera
Feb 11, 2025Monocular egocentric 3D human motion capture remains a significant challenge, particularly under conditions of low lighting and fast movements, which are common in head-mounted device applications. Existing methods that rely on RGB cameras often fail under these conditions. To address these limitations, we introduce EventEgo3D++, the first approach that leverages a monocular event camera with a fisheye lens for 3D human motion capture. Event cameras excel in high-speed scenarios and varying illumination due to their high temporal resolution, providing reliable cues for accurate 3D human motion capture. EventEgo3D++ leverages the LNES representation of event streams to enable precise 3D reconstructions. We have also developed a mobile head-mounted device (HMD) prototype equipped with an event camera, capturing a comprehensive dataset that includes real event observations from both controlled studio environments and in-the-wild settings, in addition to a synthetic dataset. Additionally, to provide a more holistic dataset, we include allocentric RGB streams that offer different perspectives of the HMD wearer, along with their corresponding SMPL body model. Our experiments demonstrate that EventEgo3D++ achieves superior 3D accuracy and robustness compared to existing solutions, even in challenging conditions. Moreover, our method supports real-time 3D pose updates at a rate of 140Hz. This work is an extension of the EventEgo3D approach (CVPR 2024) and further advances the state of the art in egocentric 3D human motion capture. For more details, visit the project page at https://eventego3d.mpi-inf.mpg.de.
PocoLoco: A Point Cloud Diffusion Model of Human Shape in Loose Clothing
Nov 06, 2024
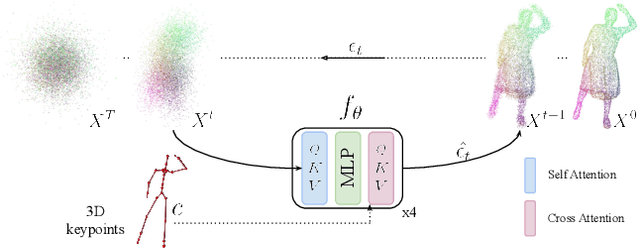
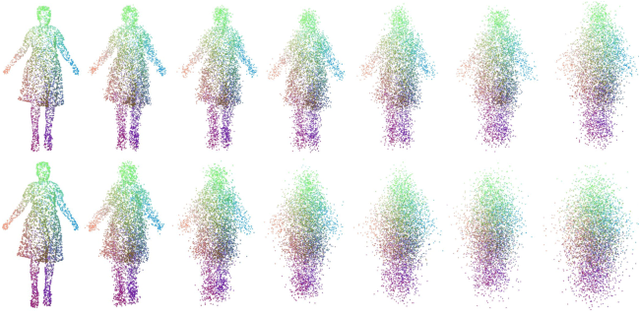
Modeling a human avatar that can plausibly deform to articulations is an active area of research. We present PocoLoco -- the first template-free, point-based, pose-conditioned generative model for 3D humans in loose clothing. We motivate our work by noting that most methods require a parametric model of the human body to ground pose-dependent deformations. Consequently, they are restricted to modeling clothing that is topologically similar to the naked body and do not extend well to loose clothing. The few methods that attempt to model loose clothing typically require either canonicalization or a UV-parameterization and need to address the challenging problem of explicitly estimating correspondences for the deforming clothes. In this work, we formulate avatar clothing deformation as a conditional point-cloud generation task within the denoising diffusion framework. Crucially, our framework operates directly on unordered point clouds, eliminating the need for a parametric model or a clothing template. This also enables a variety of practical applications, such as point-cloud completion and pose-based editing -- important features for virtual human animation. As current datasets for human avatars in loose clothing are far too small for training diffusion models, we release a dataset of two subjects performing various poses in loose clothing with a total of 75K point clouds. By contributing towards tackling the challenging task of effectively modeling loose clothing and expanding the available data for training these models, we aim to set the stage for further innovation in digital humans. The source code is available at https://github.com/sidsunny/pocoloco .
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams
Apr 12, 2024



Monocular egocentric 3D human motion capture is a challenging and actively researched problem. Existing methods use synchronously operating visual sensors (e.g. RGB cameras) and often fail under low lighting and fast motions, which can be restricting in many applications involving head-mounted devices. In response to the existing limitations, this paper 1) introduces a new problem, i.e., 3D human motion capture from an egocentric monocular event camera with a fisheye lens, and 2) proposes the first approach to it called EventEgo3D (EE3D). Event streams have high temporal resolution and provide reliable cues for 3D human motion capture under high-speed human motions and rapidly changing illumination. The proposed EE3D framework is specifically tailored for learning with event streams in the LNES representation, enabling high 3D reconstruction accuracy. We also design a prototype of a mobile head-mounted device with an event camera and record a real dataset with event observations and the ground-truth 3D human poses (in addition to the synthetic dataset). Our EE3D demonstrates robustness and superior 3D accuracy compared to existing solutions across various challenging experiments while supporting real-time 3D pose update rates of 140Hz.
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera
Dec 21, 2023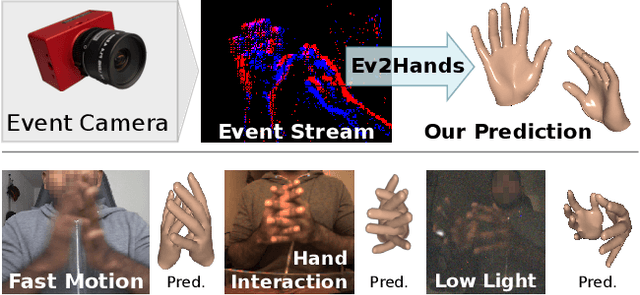

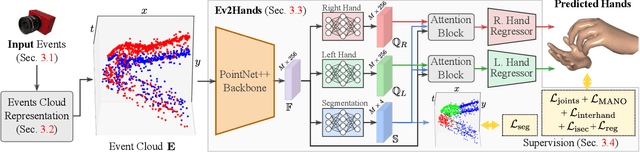

3D hand tracking from a monocular video is a very challenging problem due to hand interactions, occlusions, left-right hand ambiguity, and fast motion. Most existing methods rely on RGB inputs, which have severe limitations under low-light conditions and suffer from motion blur. In contrast, event cameras capture local brightness changes instead of full image frames and do not suffer from the described effects. Unfortunately, existing image-based techniques cannot be directly applied to events due to significant differences in the data modalities. In response to these challenges, this paper introduces the first framework for 3D tracking of two fast-moving and interacting hands from a single monocular event camera. Our approach tackles the left-right hand ambiguity with a novel semi-supervised feature-wise attention mechanism and integrates an intersection loss to fix hand collisions. To facilitate advances in this research domain, we release a new synthetic large-scale dataset of two interacting hands, Ev2Hands-S, and a new real benchmark with real event streams and ground-truth 3D annotations, Ev2Hands-R. Our approach outperforms existing methods in terms of the 3D reconstruction accuracy and generalises to real data under severe light conditions.
* 17 pages, 12 figures, 7 tables; project page: https://4dqv.mpi-inf.mpg.de/Ev2Hands/
Relightable Neural Actor with Intrinsic Decomposition and Pose Control
Dec 18, 2023Creating a digital human avatar that is relightable, drivable, and photorealistic is a challenging and important problem in Vision and Graphics. Humans are highly articulated creating pose-dependent appearance effects like self-shadows and wrinkles, and skin as well as clothing require complex and space-varying BRDF models. While recent human relighting approaches can recover plausible material-light decompositions from multi-view video, they do not generalize to novel poses and still suffer from visual artifacts. To address this, we propose Relightable Neural Actor, the first video-based method for learning a photorealistic neural human model that can be relighted, allows appearance editing, and can be controlled by arbitrary skeletal poses. Importantly, for learning our human avatar, we solely require a multi-view recording of the human under a known, but static lighting condition. To achieve this, we represent the geometry of the actor with a drivable density field that models pose-dependent clothing deformations and provides a mapping between 3D and UV space, where normal, visibility, and materials are encoded. To evaluate our approach in real-world scenarios, we collect a new dataset with four actors recorded under different light conditions, indoors and outdoors, providing the first benchmark of its kind for human relighting, and demonstrating state-of-the-art relighting results for novel human poses.
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras
Dec 12, 2023



We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
Dec 02, 2023
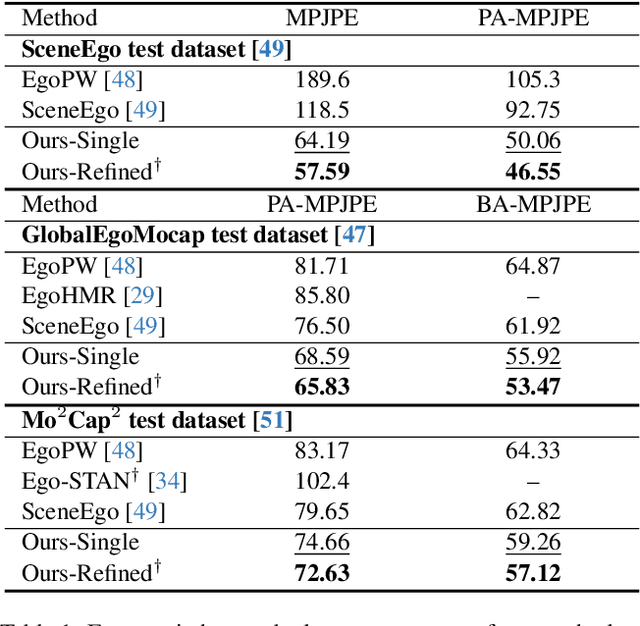
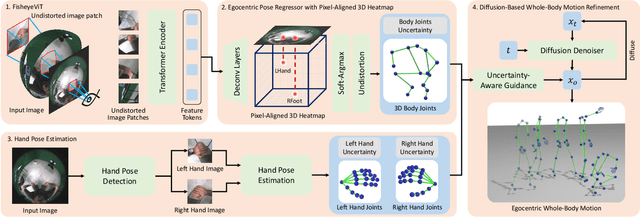
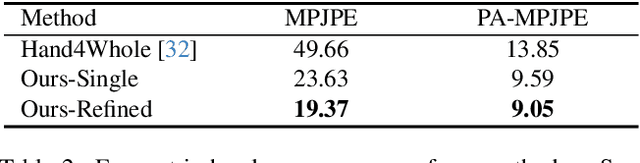
In this work, we explore egocentric whole-body motion capture using a single fisheye camera, which simultaneously estimates human body and hand motion. This task presents significant challenges due to three factors: the lack of high-quality datasets, fisheye camera distortion, and human body self-occlusion. To address these challenges, we propose a novel approach that leverages FisheyeViT to extract fisheye image features, which are subsequently converted into pixel-aligned 3D heatmap representations for 3D human body pose prediction. For hand tracking, we incorporate dedicated hand detection and hand pose estimation networks for regressing 3D hand poses. Finally, we develop a diffusion-based whole-body motion prior model to refine the estimated whole-body motion while accounting for joint uncertainties. To train these networks, we collect a large synthetic dataset, EgoWholeBody, comprising 840,000 high-quality egocentric images captured across a diverse range of whole-body motion sequences. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in producing high-quality whole-body motion estimates from a single egocentric camera.
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera
Jan 12, 2023In this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.