 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-3DPSM: A State Machine for Event-Based Egocentric 3D Human Pose Estimation
Apr 09, 2026Event cameras offer multiple advantages in monocular egocentric 3D human pose estimation from head-mounted devices, such as millisecond temporal resolution, high dynamic range, and negligible motion blur. Existing methods effectively leverage these properties, but suffer from low 3D estimation accuracy, insufficient in many applications (e.g., immersive VR/AR). This is due to the design not being fully tailored towards event streams (e.g., their asynchronous and continuous nature), leading to high sensitivity to self-occlusions and temporal jitter in the estimates. This paper rethinks the setting and introduces E-3DPSM, an event-driven continuous pose state machine for event-based egocentric 3D human pose estimation. E-3DPSM aligns continuous human motion with fine-grained event dynamics; it evolves latent states and predicts continuous changes in 3D joint positions associated with observed events, which are fused with direct 3D human pose predictions, leading to stable and drift-free final 3D pose reconstructions. E-3DPSM runs in real-time at 80 Hz on a single workstation and sets a new state of the art in experiments on two benchmarks, improving accuracy by up to 19% (MPJPE) and temporal stability by up to 2.7x. See our project page for the source code and trained models.
Bring Your Rear Cameras for Egocentric 3D Human Pose Estimation
Mar 14, 2025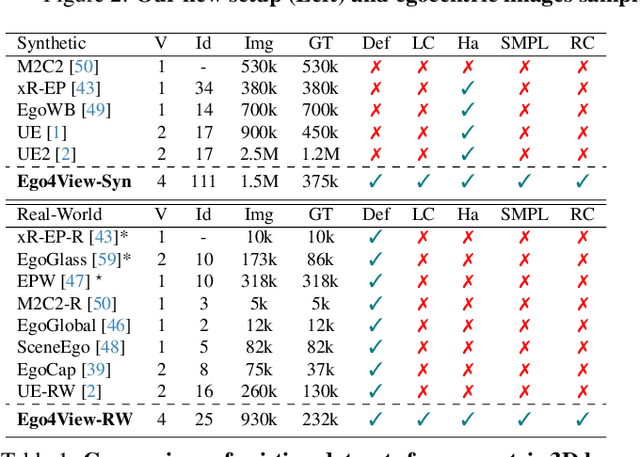

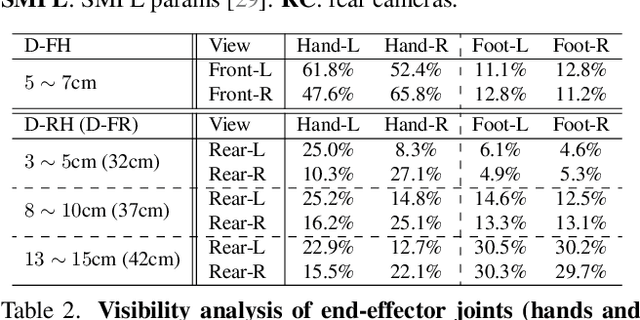
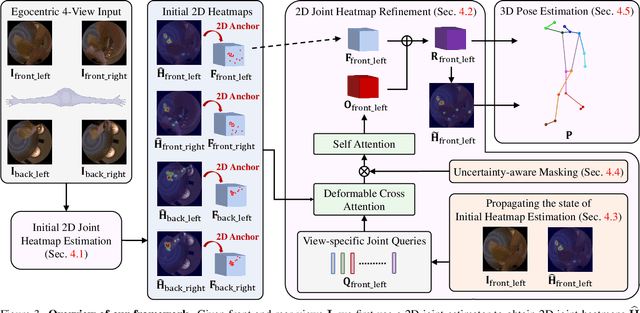
Egocentric 3D human pose estimation has been actively studied using cameras installed in front of a head-mounted device (HMD). While frontal placement is the optimal and the only option for some tasks, such as hand tracking, it remains unclear if the same holds for full-body tracking due to self-occlusion and limited field-of-view coverage. Notably, even the state-of-the-art methods often fail to estimate accurate 3D poses in many scenarios, such as when HMD users tilt their heads upward (a common motion in human activities). A key limitation of existing HMD designs is their neglect of the back of the body, despite its potential to provide crucial 3D reconstruction cues. Hence, this paper investigates the usefulness of rear cameras in the HMD design for full-body tracking. We also show that simply adding rear views to the frontal inputs is not optimal for existing methods due to their dependence on individual 2D joint detectors without effective multi-view integration. To address this issue, we propose a new transformer-based method that refines 2D joint heatmap estimation with multi-view information and heatmap uncertainty, thereby improving 3D pose tracking. Moreover, we introduce two new large-scale datasets, Ego4View-Syn and Ego4View-RW, for a rear-view evaluation. Our experiments show that the new camera configurations with back views provide superior support for 3D pose tracking compared to only frontal placements. The proposed method achieves significant improvement over the current state of the art (>10% on MPJPE). We will release the source code, trained models, and new datasets on our project page https://4dqv.mpi-inf.mpg.de/EgoRear/.
EventEgo3D++: 3D Human Motion Capture from a Head-Mounted Event Camera
Feb 11, 2025Monocular egocentric 3D human motion capture remains a significant challenge, particularly under conditions of low lighting and fast movements, which are common in head-mounted device applications. Existing methods that rely on RGB cameras often fail under these conditions. To address these limitations, we introduce EventEgo3D++, the first approach that leverages a monocular event camera with a fisheye lens for 3D human motion capture. Event cameras excel in high-speed scenarios and varying illumination due to their high temporal resolution, providing reliable cues for accurate 3D human motion capture. EventEgo3D++ leverages the LNES representation of event streams to enable precise 3D reconstructions. We have also developed a mobile head-mounted device (HMD) prototype equipped with an event camera, capturing a comprehensive dataset that includes real event observations from both controlled studio environments and in-the-wild settings, in addition to a synthetic dataset. Additionally, to provide a more holistic dataset, we include allocentric RGB streams that offer different perspectives of the HMD wearer, along with their corresponding SMPL body model. Our experiments demonstrate that EventEgo3D++ achieves superior 3D accuracy and robustness compared to existing solutions, even in challenging conditions. Moreover, our method supports real-time 3D pose updates at a rate of 140Hz. This work is an extension of the EventEgo3D approach (CVPR 2024) and further advances the state of the art in egocentric 3D human motion capture. For more details, visit the project page at https://eventego3d.mpi-inf.mpg.de.
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams
Apr 12, 2024



Monocular egocentric 3D human motion capture is a challenging and actively researched problem. Existing methods use synchronously operating visual sensors (e.g. RGB cameras) and often fail under low lighting and fast motions, which can be restricting in many applications involving head-mounted devices. In response to the existing limitations, this paper 1) introduces a new problem, i.e., 3D human motion capture from an egocentric monocular event camera with a fisheye lens, and 2) proposes the first approach to it called EventEgo3D (EE3D). Event streams have high temporal resolution and provide reliable cues for 3D human motion capture under high-speed human motions and rapidly changing illumination. The proposed EE3D framework is specifically tailored for learning with event streams in the LNES representation, enabling high 3D reconstruction accuracy. We also design a prototype of a mobile head-mounted device with an event camera and record a real dataset with event observations and the ground-truth 3D human poses (in addition to the synthetic dataset). Our EE3D demonstrates robustness and superior 3D accuracy compared to existing solutions across various challenging experiments while supporting real-time 3D pose update rates of 140Hz.
3D Human Pose Perception from Egocentric Stereo Videos
Dec 30, 2023



While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
UnrealEgo: A New Dataset for Robust Egocentric 3D Human Motion Capture
Aug 02, 2022

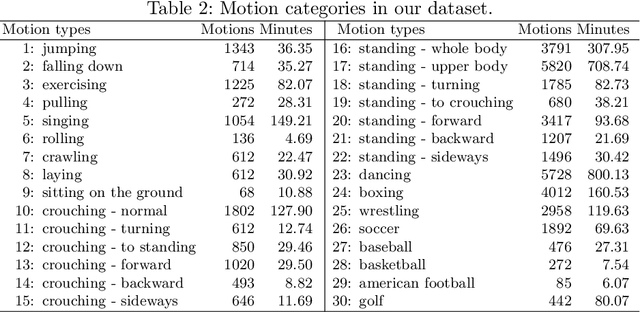
We present UnrealEgo, i.e., a new large-scale naturalistic dataset for egocentric 3D human pose estimation. UnrealEgo is based on an advanced concept of eyeglasses equipped with two fisheye cameras that can be used in unconstrained environments. We design their virtual prototype and attach them to 3D human models for stereo view capture. We next generate a large corpus of human motions. As a consequence, UnrealEgo is the first dataset to provide in-the-wild stereo images with the largest variety of motions among existing egocentric datasets. Furthermore, we propose a new benchmark method with a simple but effective idea of devising a 2D keypoint estimation module for stereo inputs to improve 3D human pose estimation. The extensive experiments show that our approach outperforms the previous state-of-the-art methods qualitatively and quantitatively. UnrealEgo and our source codes are available on our project web page.
* 21 pages, 10 figures, 10 tables; project page: https://4dqv.mpi-inf.mpg.de/UnrealEgo/
Self-Supervised Learning of Domain Invariant Features for Depth Estimation
Jun 08, 2021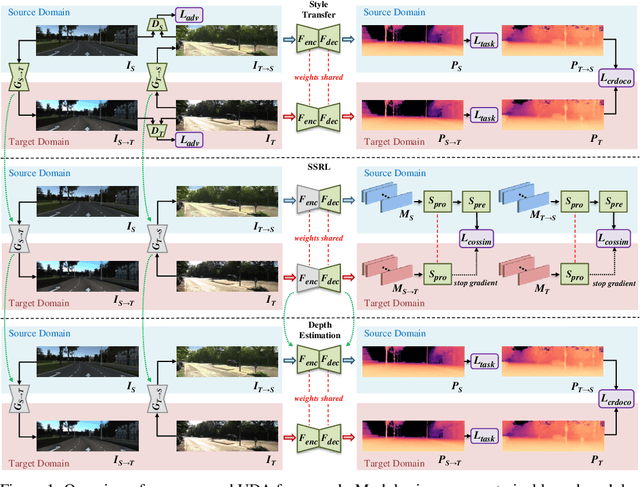
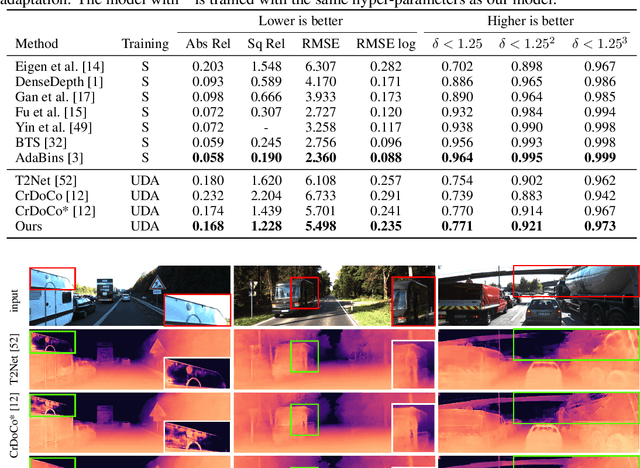
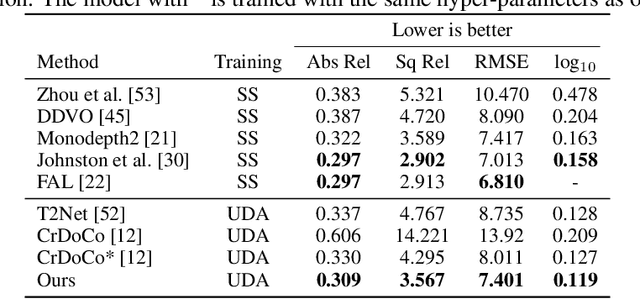

We tackle the problem of unsupervised synthetic-to-realistic domain adaptation for single image depth estimation. An essential building block of single image depth estimation is an encoder-decoder task network that takes RGB images as input and produces depth maps as output. In this paper, we propose a novel training strategy to force the task network to learn domain invariant representations in a self-supervised manner. Specifically, we extend self-supervised learning from traditional representation learning, which works on images from a single domain, to domain invariant representation learning, which works on images from two different domains by utilizing an image-to-image translation network. Firstly, we use our bidirectional image-to-image translation network to transfer domain-specific styles between synthetic and real domains. This style transfer operation allows us to obtain similar images from the different domains. Secondly, we jointly train our task network and Siamese network with the same images from the different domains to obtain domain invariance for the task network. Finally, we fine-tune the task network using labeled synthetic and unlabeled real-world data. Our training strategy yields improved generalization capability in the real-world domain. We carry out an extensive evaluation on two popular datasets for depth estimation, KITTI and Make3D. The results demonstrate that our proposed method outperforms the state-of-the-art both qualitatively and quantitatively. The source code and model weights will be made available.