 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalBins: Improving Depth Estimation by Learning Local Distributions
Mar 28, 2022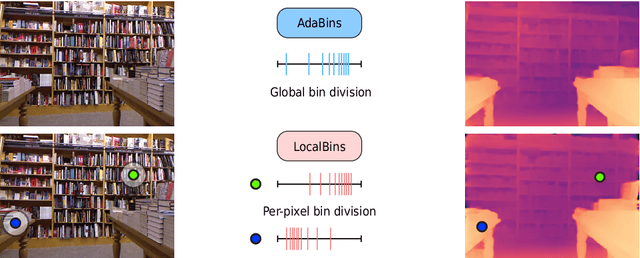



We propose a novel architecture for depth estimation from a single image. The architecture itself is based on the popular encoder-decoder architecture that is frequently used as a starting point for all dense regression tasks. We build on AdaBins which estimates a global distribution of depth values for the input image and evolve the architecture in two ways. First, instead of predicting global depth distributions, we predict depth distributions of local neighborhoods at every pixel. Second, instead of predicting depth distributions only towards the end of the decoder, we involve all layers of the decoder. We call this new architecture LocalBins. Our results demonstrate a clear improvement over the state-of-the-art in all metrics on the NYU-Depth V2 dataset. Code and pretrained models will be made publicly available.
Self-Supervised Learning of Domain Invariant Features for Depth Estimation
Jun 08, 2021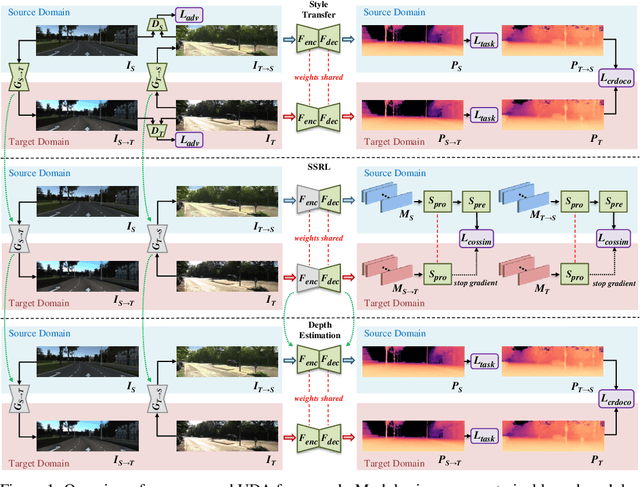
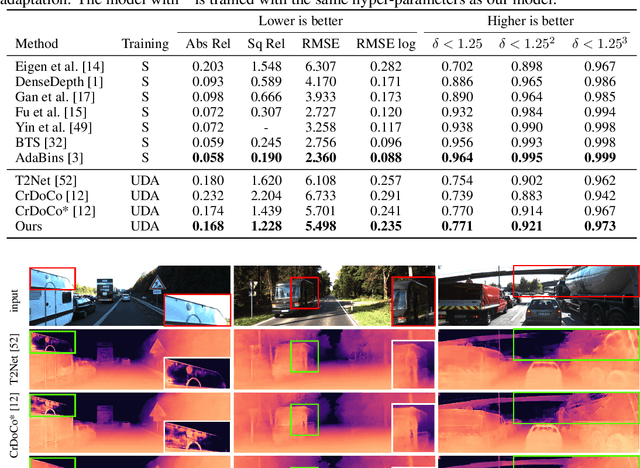
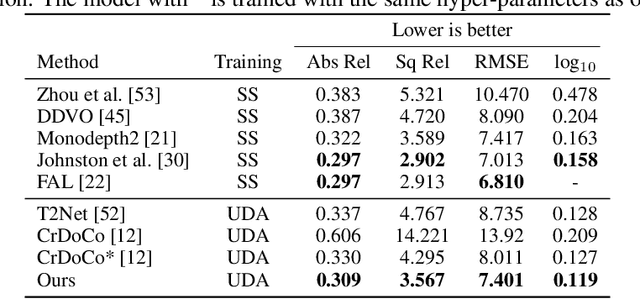

We tackle the problem of unsupervised synthetic-to-realistic domain adaptation for single image depth estimation. An essential building block of single image depth estimation is an encoder-decoder task network that takes RGB images as input and produces depth maps as output. In this paper, we propose a novel training strategy to force the task network to learn domain invariant representations in a self-supervised manner. Specifically, we extend self-supervised learning from traditional representation learning, which works on images from a single domain, to domain invariant representation learning, which works on images from two different domains by utilizing an image-to-image translation network. Firstly, we use our bidirectional image-to-image translation network to transfer domain-specific styles between synthetic and real domains. This style transfer operation allows us to obtain similar images from the different domains. Secondly, we jointly train our task network and Siamese network with the same images from the different domains to obtain domain invariance for the task network. Finally, we fine-tune the task network using labeled synthetic and unlabeled real-world data. Our training strategy yields improved generalization capability in the real-world domain. We carry out an extensive evaluation on two popular datasets for depth estimation, KITTI and Make3D. The results demonstrate that our proposed method outperforms the state-of-the-art both qualitatively and quantitatively. The source code and model weights will be made available.
AdaBins: Depth Estimation using Adaptive Bins
Nov 28, 2020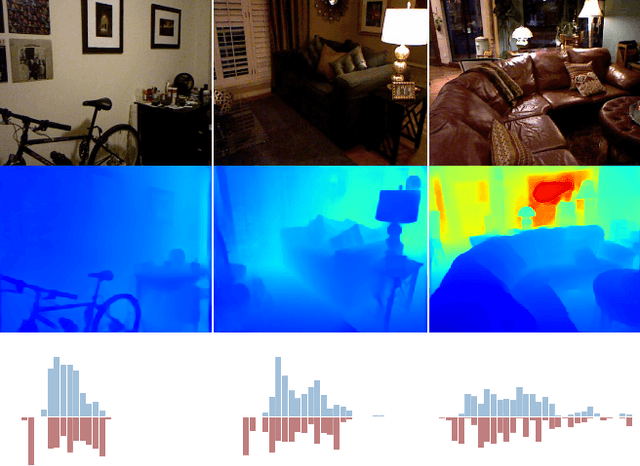

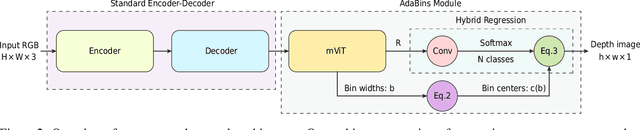
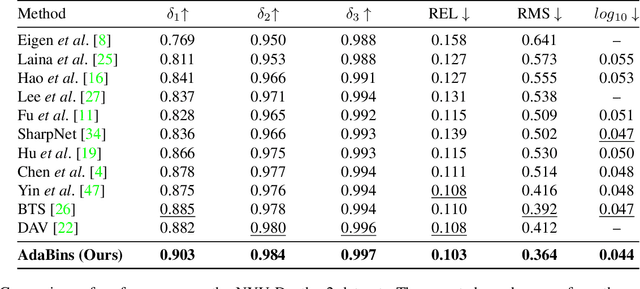
We address the problem of estimating a high quality dense depth map from a single RGB input image. We start out with a baseline encoder-decoder convolutional neural network architecture and pose the question of how the global processing of information can help improve overall depth estimation. To this end, we propose a transformer-based architecture block that divides the depth range into bins whose center value is estimated adaptively per image. The final depth values are estimated as linear combinations of the bin centers. We call our new building block AdaBins. Our results show a decisive improvement over the state-of-the-art on several popular depth datasets across all metrics. We also validate the effectiveness of the proposed block with an ablation study and provide the code and corresponding pre-trained weights of the new state-of-the-art model.
TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures
Apr 29, 2019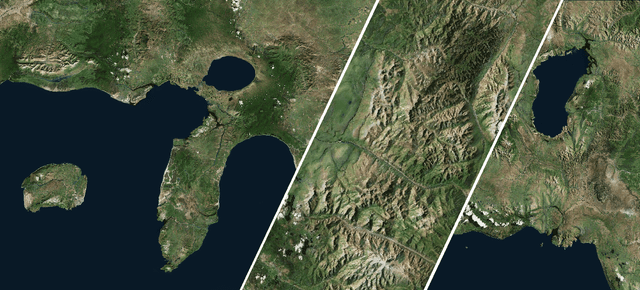
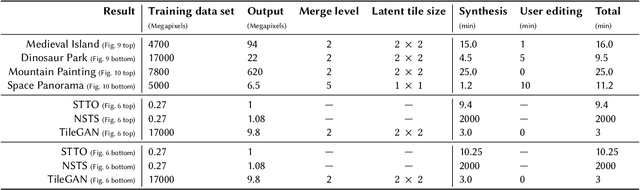


We tackle the problem of texture synthesis in the setting where many input images are given and a large-scale output is required. We build on recent generative adversarial networks and propose two extensions in this paper. First, we propose an algorithm to combine outputs of GANs trained on a smaller resolution to produce a large-scale plausible texture map with virtually no boundary artifacts. Second, we propose a user interface to enable artistic control. Our quantitative and qualitative results showcase the generation of synthesized high-resolution maps consisting of up to hundreds of megapixels as a case in point.
* Code is available at http://github.com/afruehstueck/tileGAN
High Quality Monocular Depth Estimation via Transfer Learning
Dec 31, 2018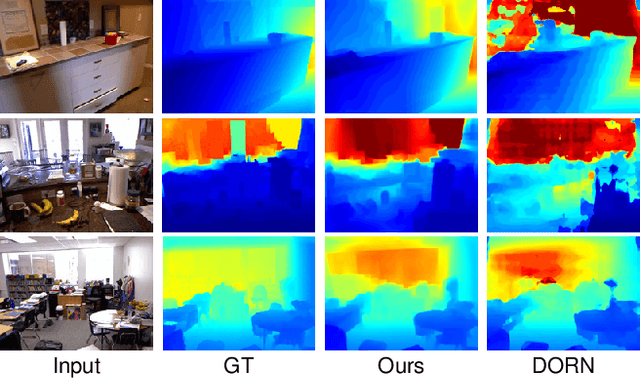
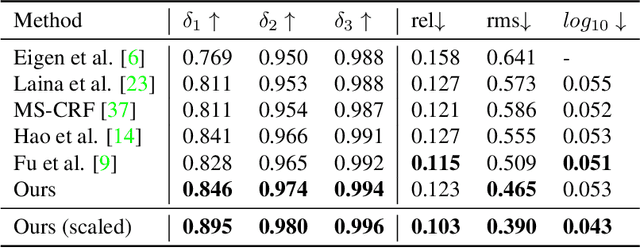
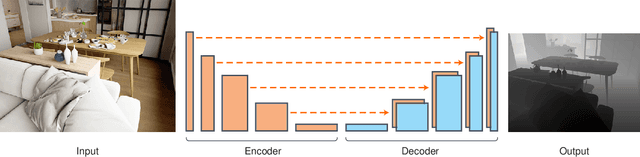
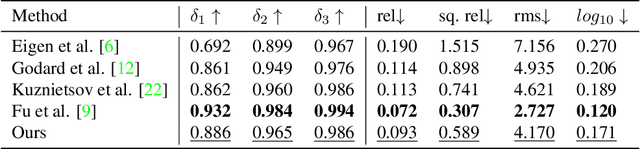
Accurate depth estimation from images is a fundamental task in many applications including scene understanding and reconstruction. Existing solutions for depth estimation often produce blurry approximations of low resolution. This paper presents a convolutional neural network for computing a high-resolution depth map given a single RGB image with the help of transfer learning. Following a standard encoder-decoder architecture, we leverage features extracted using high performing pre-trained networks when initializing our encoder along with augmentation and training strategies that lead to more accurate results. We show how, even for a very simple decoder, our method is able to achieve detailed high-resolution depth maps. Our network, with fewer parameters and training iterations, outperforms state-of-the-art on two datasets and also produces qualitatively better results that capture object boundaries more faithfully. Code and corresponding pre-trained weights are made publicly available.