 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResEdit: Residual embeddings for precise generative image editing
Jun 15, 2026Conditional diffusion image generators can be repurposed for editing through inversion, without the need for large-scale paired fine-tuning data. However, producing high-quality, targeted edits while maintaining image identity and global consistency remains challenging, as weakly conditioned inversion often embeds conflicting image features into the noise. We demonstrate that incorporating a residual image encoding as additional conditioning enables both improved identity preservation and better editability. We optimize this residual encoding to provide a strong conditioning signal for reconstruction, thereby reducing the reliance on inversion and susceptibility to its aforementioned pitfalls. To ensure this residual does not interfere with desired edits, we incorporate a gradient reversal-based optimization strategy that disentangles the residual from the edited condition. We illustrate our method's ability to produce high-fidelity results across precise intrinsic-based editing and relighting, and show proof-of-concept text-guided manipulation.
PRISM: A Unified Framework for Photorealistic Reconstruction and Intrinsic Scene Modeling
Apr 19, 2025We present PRISM, a unified framework that enables multiple image generation and editing tasks in a single foundational model. Starting from a pre-trained text-to-image diffusion model, PRISM proposes an effective fine-tuning strategy to produce RGB images along with intrinsic maps (referred to as X layers) simultaneously. Unlike previous approaches, which infer intrinsic properties individually or require separate models for decomposition and conditional generation, PRISM maintains consistency across modalities by generating all intrinsic layers jointly. It supports diverse tasks, including text-to-RGBX generation, RGB-to-X decomposition, and X-to-RGBX conditional generation. Additionally, PRISM enables both global and local image editing through conditioning on selected intrinsic layers and text prompts. Extensive experiments demonstrate the competitive performance of PRISM both for intrinsic image decomposition and conditional image generation while preserving the base model's text-to-image generation capability.
SuperGaussian: Repurposing Video Models for 3D Super Resolution
Jun 04, 2024



We present a simple, modular, and generic method that upsamples coarse 3D models by adding geometric and appearance details. While generative 3D models now exist, they do not yet match the quality of their counterparts in image and video domains. We demonstrate that it is possible to directly repurpose existing (pretrained) video models for 3D super-resolution and thus sidestep the problem of the shortage of large repositories of high-quality 3D training models. We describe how to repurpose video upsampling models, which are not 3D consistent, and combine them with 3D consolidation to produce 3D-consistent results. As output, we produce high quality Gaussian Splat models, which are object centric and effective. Our method is category agnostic and can be easily incorporated into existing 3D workflows. We evaluate our proposed SuperGaussian on a variety of 3D inputs, which are diverse both in terms of complexity and representation (e.g., Gaussian Splats or NeRFs), and demonstrate that our simple method significantly improves the fidelity of the final 3D models. Check our project website for details: supergaussian.github.io
VIVE3D: Viewpoint-Independent Video Editing using 3D-Aware GANs
Mar 28, 2023We introduce VIVE3D, a novel approach that extends the capabilities of image-based 3D GANs to video editing and is able to represent the input video in an identity-preserving and temporally consistent way. We propose two new building blocks. First, we introduce a novel GAN inversion technique specifically tailored to 3D GANs by jointly embedding multiple frames and optimizing for the camera parameters. Second, besides traditional semantic face edits (e.g. for age and expression), we are the first to demonstrate edits that show novel views of the head enabled by the inherent properties of 3D GANs and our optical flow-guided compositing technique to combine the head with the background video. Our experiments demonstrate that VIVE3D generates high-fidelity face edits at consistent quality from a range of camera viewpoints which are composited with the original video in a temporally and spatially consistent manner.
InsetGAN for Full-Body Image Generation
Mar 14, 2022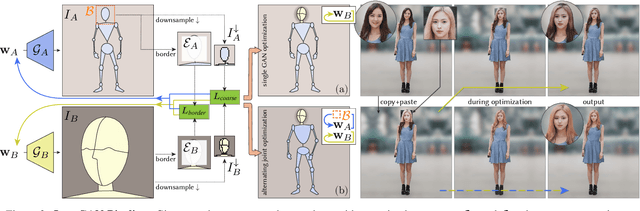



While GANs can produce photo-realistic images in ideal conditions for certain domains, the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose. Instead of modeling this complex domain with a single GAN, we propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas. We model the problem as jointly exploring the respective latent spaces such that the generated images can be combined, by inserting the parts from the specialized generators onto the global canvas, without introducing seams. We demonstrate the setup by combining a full body GAN with a dedicated high-quality face GAN to produce plausible-looking humans. We evaluate our results with quantitative metrics and user studies.
On the Robustness of Quality Measures for GANs
Jan 31, 2022
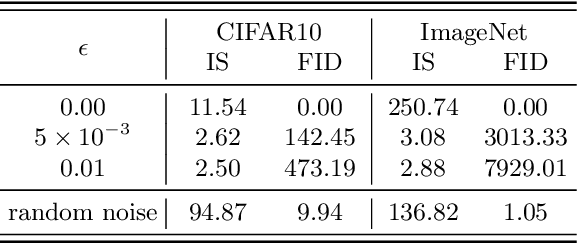


This work evaluates the robustness of quality measures of generative models such as Inception Score (IS) and Fr\'echet Inception Distance (FID). Analogous to the vulnerability of deep models against a variety of adversarial attacks, we show that such metrics can also be manipulated by additive pixel perturbations. Our experiments indicate that one can generate a distribution of images with very high scores but low perceptual quality. Conversely, one can optimize for small imperceptible perturbations that, when added to real world images, deteriorate their scores. Furthermore, we extend our evaluation to generative models themselves, including the state of the art network StyleGANv2. We show the vulnerability of both the generative model and the FID against additive perturbations in the latent space. Finally, we show that the FID can be robustified by directly replacing the Inception model by a robustly trained Inception. We validate the effectiveness of the robustified metric through extensive experiments, which show that it is more robust against manipulation.
TileGAN: Synthesis of Large-Scale Non-Homogeneous Textures
Apr 29, 2019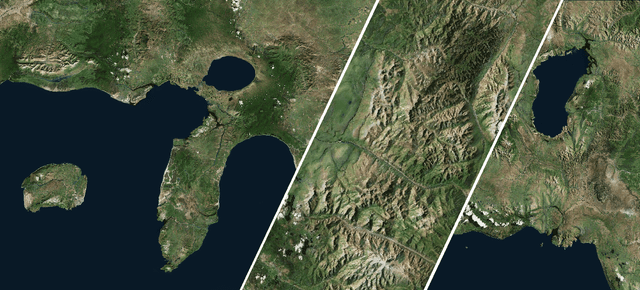
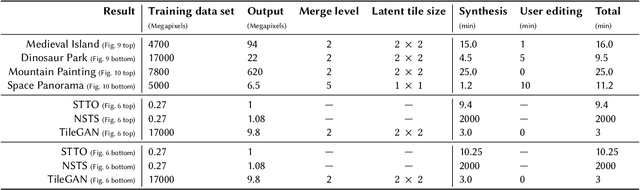


We tackle the problem of texture synthesis in the setting where many input images are given and a large-scale output is required. We build on recent generative adversarial networks and propose two extensions in this paper. First, we propose an algorithm to combine outputs of GANs trained on a smaller resolution to produce a large-scale plausible texture map with virtually no boundary artifacts. Second, we propose a user interface to enable artistic control. Our quantitative and qualitative results showcase the generation of synthesized high-resolution maps consisting of up to hundreds of megapixels as a case in point.
* Code is available at http://github.com/afruehstueck/tileGAN