 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Unified Framework for Photorealistic Reconstruction and Intrinsic Scene Modeling
Apr 19, 2025We present PRISM, a unified framework that enables multiple image generation and editing tasks in a single foundational model. Starting from a pre-trained text-to-image diffusion model, PRISM proposes an effective fine-tuning strategy to produce RGB images along with intrinsic maps (referred to as X layers) simultaneously. Unlike previous approaches, which infer intrinsic properties individually or require separate models for decomposition and conditional generation, PRISM maintains consistency across modalities by generating all intrinsic layers jointly. It supports diverse tasks, including text-to-RGBX generation, RGB-to-X decomposition, and X-to-RGBX conditional generation. Additionally, PRISM enables both global and local image editing through conditioning on selected intrinsic layers and text prompts. Extensive experiments demonstrate the competitive performance of PRISM both for intrinsic image decomposition and conditional image generation while preserving the base model's text-to-image generation capability.
A Repulsive Force Unit for Garment Collision Handling in Neural Networks
Jul 28, 2022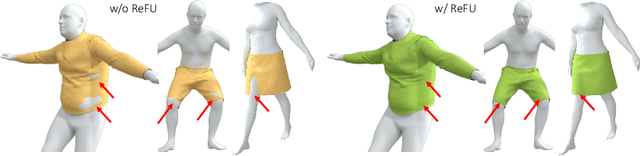
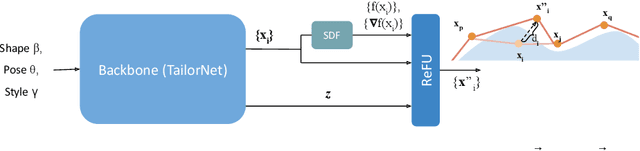
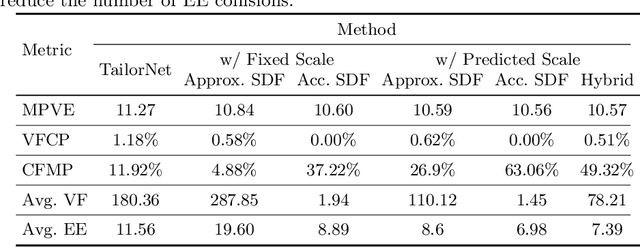
Despite recent success, deep learning-based methods for predicting 3D garment deformation under body motion suffer from interpenetration problems between the garment and the body. To address this problem, we propose a novel collision handling neural network layer called Repulsive Force Unit (ReFU). Based on the signed distance function (SDF) of the underlying body and the current garment vertex positions, ReFU predicts the per-vertex offsets that push any interpenetrating vertex to a collision-free configuration while preserving the fine geometric details. We show that ReFU is differentiable with trainable parameters and can be integrated into different network backbones that predict 3D garment deformations. Our experiments show that ReFU significantly reduces the number of collisions between the body and the garment and better preserves geometric details compared to prior methods based on collision loss or post-processing optimization.
Dynamic Neural Garments
Feb 23, 2021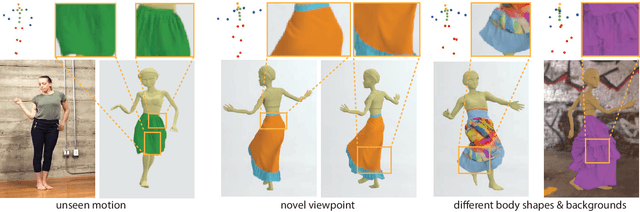
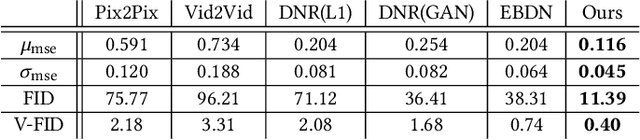


A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to jointly simulate and render plausible dynamic garment appearance from an unseen viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative improvements.