 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-ID: Test-Time Geometric Consensus for Cross-View Consistent Intrinsics
Mar 14, 2026Intrinsic image decomposition aims to estimate physically based rendering (PBR) parameters such as albedo, roughness, and metallicity from images. While recent methods achieve strong single-view predictions, applying them independently to multiple views of the same scene often yields inconsistent estimates, limiting their use in downstream applications such as editable neural scenes and 3D reconstruction. Video-based models can improve cross-frame consistency but require dense, ordered sequences and substantial compute, limiting their applicability to sparse, unordered image collections. We propose Geo-ID, a novel test-time framework that repurposes pretrained single-view intrinsic predictors to produce cross-view consistent decompositions by coupling independent per-view predictions through sparse geometric correspondences that form uncertainty-aware consensus targets. Geo-ID is model-agnostic, requires no retraining or inverse rendering, and applies directly to off-the-shelf intrinsic predictors. Experiments on synthetic benchmarks and real-world scenes demonstrate substantial improvements in cross-view intrinsic consistency as the number of views increases, while maintaining comparable single-view decomposition performance. We further show that the resulting consistent intrinsics enable coherent appearance editing and relighting in downstream neural scene representations.
PRISM: A Unified Framework for Photorealistic Reconstruction and Intrinsic Scene Modeling
Apr 19, 2025We present PRISM, a unified framework that enables multiple image generation and editing tasks in a single foundational model. Starting from a pre-trained text-to-image diffusion model, PRISM proposes an effective fine-tuning strategy to produce RGB images along with intrinsic maps (referred to as X layers) simultaneously. Unlike previous approaches, which infer intrinsic properties individually or require separate models for decomposition and conditional generation, PRISM maintains consistency across modalities by generating all intrinsic layers jointly. It supports diverse tasks, including text-to-RGBX generation, RGB-to-X decomposition, and X-to-RGBX conditional generation. Additionally, PRISM enables both global and local image editing through conditioning on selected intrinsic layers and text prompts. Extensive experiments demonstrate the competitive performance of PRISM both for intrinsic image decomposition and conditional image generation while preserving the base model's text-to-image generation capability.
3D-LatentMapper: View Agnostic Single-View Reconstruction of 3D Shapes
Dec 05, 2022Computer graphics, 3D computer vision and robotics communities have produced multiple approaches to represent and generate 3D shapes, as well as a vast number of use cases. However, single-view reconstruction remains a challenging topic that can unlock various interesting use cases such as interactive design. In this work, we propose a novel framework that leverages the intermediate latent spaces of Vision Transformer (ViT) and a joint image-text representational model, CLIP, for fast and efficient Single View Reconstruction (SVR). More specifically, we propose a novel mapping network architecture that learns a mapping between deep features extracted from ViT and CLIP, and the latent space of a base 3D generative model. Unlike previous work, our method enables view-agnostic reconstruction of 3D shapes, even in the presence of large occlusions. We use the ShapeNetV2 dataset and perform extensive experiments with comparisons to SOTA methods to demonstrate our method's effectiveness.
XDGAN: Multi-Modal 3D Shape Generation in 2D Space
Oct 06, 2022

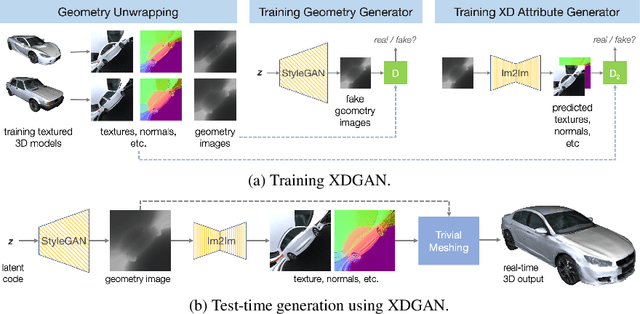
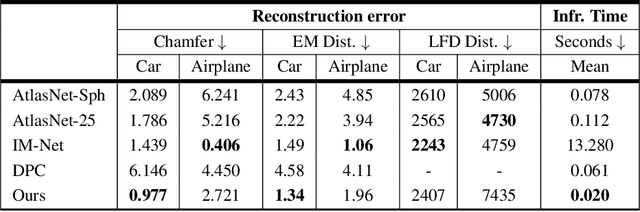
Generative models for 2D images has recently seen tremendous progress in quality, resolution and speed as a result of the efficiency of 2D convolutional architectures. However it is difficult to extend this progress into the 3D domain since most current 3D representations rely on custom network components. This paper addresses a central question: Is it possible to directly leverage 2D image generative models to generate 3D shapes instead? To answer this, we propose XDGAN, an effective and fast method for applying 2D image GAN architectures to the generation of 3D object geometry combined with additional surface attributes, like color textures and normals. Specifically, we propose a novel method to convert 3D shapes into compact 1-channel geometry images and leverage StyleGAN3 and image-to-image translation networks to generate 3D objects in 2D space. The generated geometry images are quick to convert to 3D meshes, enabling real-time 3D object synthesis, visualization and interactive editing. Moreover, the use of standard 2D architectures can help bring more 2D advances into the 3D realm. We show both quantitatively and qualitatively that our method is highly effective at various tasks such as 3D shape generation, single view reconstruction and shape manipulation, while being significantly faster and more flexible compared to recent 3D generative models.
FairStyle: Debiasing StyleGAN2 with Style Channel Manipulations
Feb 13, 2022Recent advances in generative adversarial networks have shown that it is possible to generate high-resolution and hyperrealistic images. However, the images produced by GANs are only as fair and representative as the datasets on which they are trained. In this paper, we propose a method for directly modifying a pre-trained StyleGAN2 model that can be used to generate a balanced set of images with respect to one (e.g., eyeglasses) or more attributes (e.g., gender and eyeglasses). Our method takes advantage of the style space of the StyleGAN2 model to perform disentangled control of the target attributes to be debiased. Our method does not require training additional models and directly debiases the GAN model, paving the way for its use in various downstream applications. Our experiments show that our method successfully debiases the GAN model within a few minutes without compromising the quality of the generated images. To promote fair generative models, we share the code and debiased models at http://catlab-team.github.io/fairstyle.
Text and Image Guided 3D Avatar Generation and Manipulation
Feb 12, 2022The manipulation of latent space has recently become an interesting topic in the field of generative models. Recent research shows that latent directions can be used to manipulate images towards certain attributes. However, controlling the generation process of 3D generative models remains a challenge. In this work, we propose a novel 3D manipulation method that can manipulate both the shape and texture of the model using text or image-based prompts such as 'a young face' or 'a surprised face'. We leverage the power of Contrastive Language-Image Pre-training (CLIP) model and a pre-trained 3D GAN model designed to generate face avatars, and create a fully differentiable rendering pipeline to manipulate meshes. More specifically, our method takes an input latent code and modifies it such that the target attribute specified by a text or image prompt is present or enhanced, while leaving other attributes largely unaffected. Our method requires only 5 minutes per manipulation, and we demonstrate the effectiveness of our approach with extensive results and comparisons.
StyleMC: Multi-Channel Based Fast Text-Guided Image Generation and Manipulation
Dec 15, 2021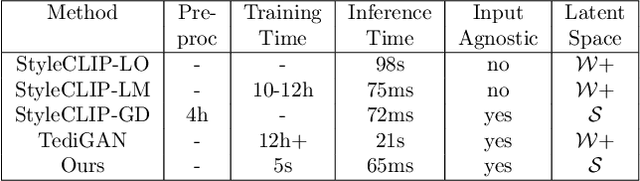
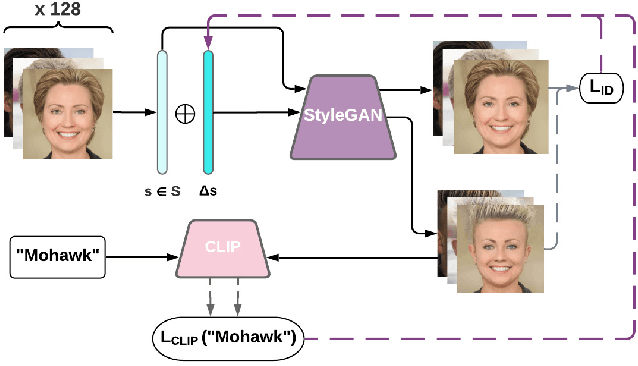


Discovering meaningful directions in the latent space of GANs to manipulate semantic attributes typically requires large amounts of labeled data. Recent work aims to overcome this limitation by leveraging the power of Contrastive Language-Image Pre-training (CLIP), a joint text-image model. While promising, these methods require several hours of preprocessing or training to achieve the desired manipulations. In this paper, we present StyleMC, a fast and efficient method for text-driven image generation and manipulation. StyleMC uses a CLIP-based loss and an identity loss to manipulate images via a single text prompt without significantly affecting other attributes. Unlike prior work, StyleMC requires only a few seconds of training per text prompt to find stable global directions, does not require prompt engineering and can be used with any pre-trained StyleGAN2 model. We demonstrate the effectiveness of our method and compare it to state-of-the-art methods. Our code can be found at http://catlab-team.github.io/stylemc.
Controlled Cue Generation for Play Scripts
Dec 13, 2021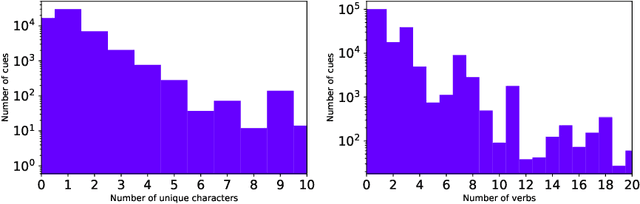
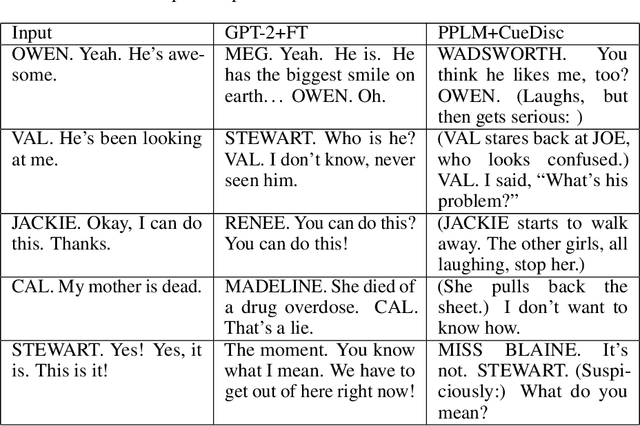


In this paper, we use a large-scale play scripts dataset to propose the novel task of theatrical cue generation from dialogues. Using over one million lines of dialogue and cues, we approach the problem of cue generation as a controlled text generation task, and show how cues can be used to enhance the impact of dialogue using a language model conditioned on a dialogue/cue discriminator. In addition, we explore the use of topic keywords and emotions for controlled text generation. Extensive quantitative and qualitative experiments show that language models can be successfully used to generate plausible and attribute-controlled texts in highly specialised domains such as play scripts. Supporting materials can be found at: https://catlab-team.github.io/cuegen.