 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwoSquared: 4D Generation from 2D Image Pairs
Apr 17, 2025



Despite the astonishing progress in generative AI, 4D dynamic object generation remains an open challenge. With limited high-quality training data and heavy computing requirements, the combination of hallucinating unseen geometry together with unseen movement poses great challenges to generative models. In this work, we propose TwoSquared as a method to obtain a 4D physically plausible sequence starting from only two 2D RGB images corresponding to the beginning and end of the action. Instead of directly solving the 4D generation problem, TwoSquared decomposes the problem into two steps: 1) an image-to-3D module generation based on the existing generative model trained on high-quality 3D assets, and 2) a physically inspired deformation module to predict intermediate movements. To this end, our method does not require templates or object-class-specific prior knowledge and can take in-the-wild images as input. In our experiments, we demonstrate that TwoSquared is capable of producing texture-consistent and geometry-consistent 4D sequences only given 2D images.
4Deform: Neural Surface Deformation for Robust Shape Interpolation
Feb 27, 2025Generating realistic intermediate shapes between non-rigidly deformed shapes is a challenging task in computer vision, especially with unstructured data (e.g., point clouds) where temporal consistency across frames is lacking, and topologies are changing. Most interpolation methods are designed for structured data (i.e., meshes) and do not apply to real-world point clouds. In contrast, our approach, 4Deform, leverages neural implicit representation (NIR) to enable free topology changing shape deformation. Unlike previous mesh-based methods that learn vertex-based deformation fields, our method learns a continuous velocity field in Euclidean space. Thus, it is suitable for less structured data such as point clouds. Additionally, our method does not require intermediate-shape supervision during training; instead, we incorporate physical and geometrical constraints to regularize the velocity field. We reconstruct intermediate surfaces using a modified level-set equation, directly linking our NIR with the velocity field. Experiments show that our method significantly outperforms previous NIR approaches across various scenarios (e.g., noisy, partial, topology-changing, non-isometric shapes) and, for the first time, enables new applications like 4D Kinect sequence upsampling and real-world high-resolution mesh deformation.
Implicit Neural Surface Deformation with Explicit Velocity Fields
Jan 23, 2025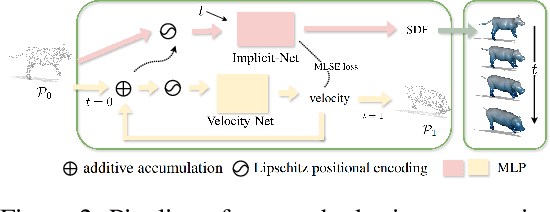
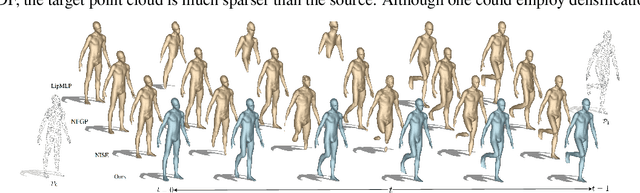
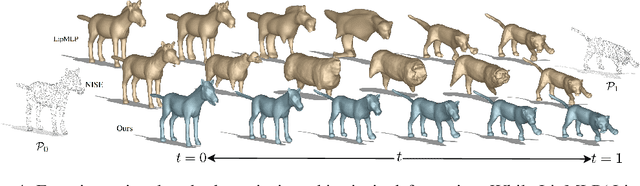
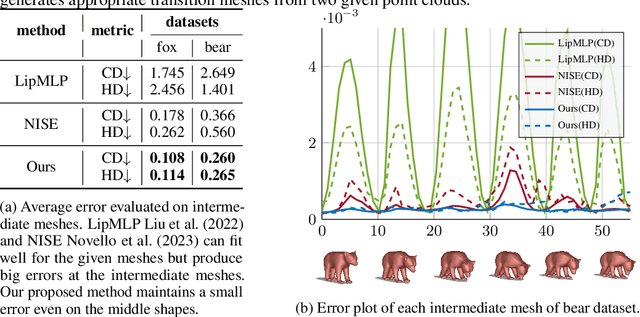
In this work, we introduce the first unsupervised method that simultaneously predicts time-varying neural implicit surfaces and deformations between pairs of point clouds. We propose to model the point movement using an explicit velocity field and directly deform a time-varying implicit field using the modified level-set equation. This equation utilizes an iso-surface evolution with Eikonal constraints in a compact formulation, ensuring the integrity of the signed distance field. By applying a smooth, volume-preserving constraint to the velocity field, our method successfully recovers physically plausible intermediate shapes. Our method is able to handle both rigid and non-rigid deformations without any intermediate shape supervision. Our experimental results demonstrate that our method significantly outperforms existing works, delivering superior results in both quality and efficiency.
Text and Image Guided 3D Avatar Generation and Manipulation
Feb 12, 2022The manipulation of latent space has recently become an interesting topic in the field of generative models. Recent research shows that latent directions can be used to manipulate images towards certain attributes. However, controlling the generation process of 3D generative models remains a challenge. In this work, we propose a novel 3D manipulation method that can manipulate both the shape and texture of the model using text or image-based prompts such as 'a young face' or 'a surprised face'. We leverage the power of Contrastive Language-Image Pre-training (CLIP) model and a pre-trained 3D GAN model designed to generate face avatars, and create a fully differentiable rendering pipeline to manipulate meshes. More specifically, our method takes an input latent code and modifies it such that the target attribute specified by a text or image prompt is present or enhanced, while leaving other attributes largely unaffected. Our method requires only 5 minutes per manipulation, and we demonstrate the effectiveness of our approach with extensive results and comparisons.