 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rigid 3D Shape Correspondences: From Foundations to Open Challenges and Opportunities
Apr 01, 2026Estimating correspondences between deformed shape instances is a long-standing problem in computer graphics; numerous applications, from texture transfer to statistical modelling, rely on recovering an accurate correspondence map. Many methods have thus been proposed to tackle this challenging problem from varying perspectives, depending on the downstream application. This state-of-the-art report is geared towards researchers, practitioners, and students seeking to understand recent trends and advances in the field. We categorise developments into three paradigms: spectral methods based on functional maps, combinatorial formulations that impose discrete constraints, and deformation-based methods that directly recover a global alignment. Each school of thought offers different advantages and disadvantages, which we discuss throughout the report. Meanwhile, we highlight the latest developments in each area and suggest new potential research directions. Finally, we provide an overview of emerging challenges and opportunities in this growing field, including the recent use of vision foundation models for zero-shot correspondence and the particularly challenging task of matching partial shapes.
Hyper Diffusion Avatars: Dynamic Human Avatar Generation using Network Weight Space Diffusion
Sep 04, 2025Creating human avatars is a highly desirable yet challenging task. Recent advancements in radiance field rendering have achieved unprecedented photorealism and real-time performance for personalized dynamic human avatars. However, these approaches are typically limited to person-specific rendering models trained on multi-view video data for a single individual, limiting their ability to generalize across different identities. On the other hand, generative approaches leveraging prior knowledge from pre-trained 2D diffusion models can produce cartoonish, static human avatars, which are animated through simple skeleton-based articulation. Therefore, the avatars generated by these methods suffer from lower rendering quality compared to person-specific rendering methods and fail to capture pose-dependent deformations such as cloth wrinkles. In this paper, we propose a novel approach that unites the strengths of person-specific rendering and diffusion-based generative modeling to enable dynamic human avatar generation with both high photorealism and realistic pose-dependent deformations. Our method follows a two-stage pipeline: first, we optimize a set of person-specific UNets, with each network representing a dynamic human avatar that captures intricate pose-dependent deformations. In the second stage, we train a hyper diffusion model over the optimized network weights. During inference, our method generates network weights for real-time, controllable rendering of dynamic human avatars. Using a large-scale, cross-identity, multi-view video dataset, we demonstrate that our approach outperforms state-of-the-art human avatar generation methods.
TwoSquared: 4D Generation from 2D Image Pairs
Apr 17, 2025



Despite the astonishing progress in generative AI, 4D dynamic object generation remains an open challenge. With limited high-quality training data and heavy computing requirements, the combination of hallucinating unseen geometry together with unseen movement poses great challenges to generative models. In this work, we propose TwoSquared as a method to obtain a 4D physically plausible sequence starting from only two 2D RGB images corresponding to the beginning and end of the action. Instead of directly solving the 4D generation problem, TwoSquared decomposes the problem into two steps: 1) an image-to-3D module generation based on the existing generative model trained on high-quality 3D assets, and 2) a physically inspired deformation module to predict intermediate movements. To this end, our method does not require templates or object-class-specific prior knowledge and can take in-the-wild images as input. In our experiments, we demonstrate that TwoSquared is capable of producing texture-consistent and geometry-consistent 4D sequences only given 2D images.
4Deform: Neural Surface Deformation for Robust Shape Interpolation
Feb 27, 2025Generating realistic intermediate shapes between non-rigidly deformed shapes is a challenging task in computer vision, especially with unstructured data (e.g., point clouds) where temporal consistency across frames is lacking, and topologies are changing. Most interpolation methods are designed for structured data (i.e., meshes) and do not apply to real-world point clouds. In contrast, our approach, 4Deform, leverages neural implicit representation (NIR) to enable free topology changing shape deformation. Unlike previous mesh-based methods that learn vertex-based deformation fields, our method learns a continuous velocity field in Euclidean space. Thus, it is suitable for less structured data such as point clouds. Additionally, our method does not require intermediate-shape supervision during training; instead, we incorporate physical and geometrical constraints to regularize the velocity field. We reconstruct intermediate surfaces using a modified level-set equation, directly linking our NIR with the velocity field. Experiments show that our method significantly outperforms previous NIR approaches across various scenarios (e.g., noisy, partial, topology-changing, non-isometric shapes) and, for the first time, enables new applications like 4D Kinect sequence upsampling and real-world high-resolution mesh deformation.
Implicit Neural Surface Deformation with Explicit Velocity Fields
Jan 23, 2025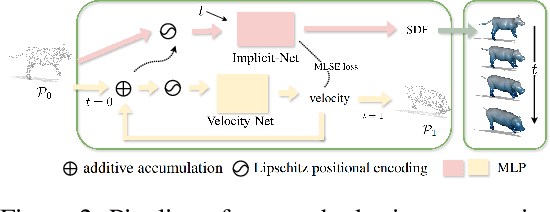
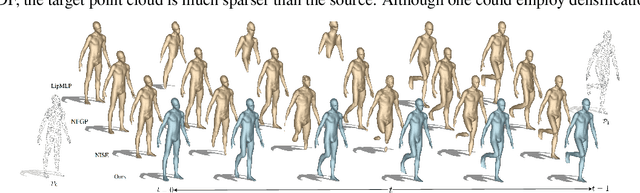
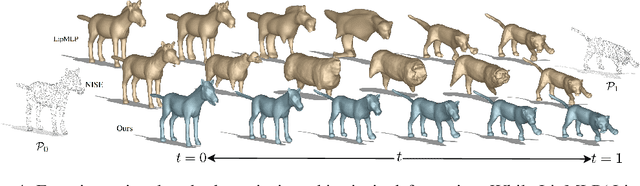
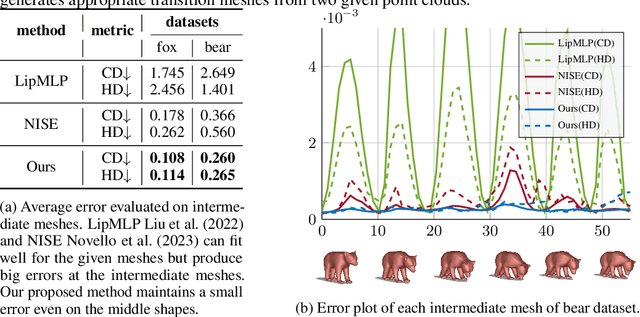
In this work, we introduce the first unsupervised method that simultaneously predicts time-varying neural implicit surfaces and deformations between pairs of point clouds. We propose to model the point movement using an explicit velocity field and directly deform a time-varying implicit field using the modified level-set equation. This equation utilizes an iso-surface evolution with Eikonal constraints in a compact formulation, ensuring the integrity of the signed distance field. By applying a smooth, volume-preserving constraint to the velocity field, our method successfully recovers physically plausible intermediate shapes. Our method is able to handle both rigid and non-rigid deformations without any intermediate shape supervision. Our experimental results demonstrate that our method significantly outperforms existing works, delivering superior results in both quality and efficiency.
Beyond Complete Shapes: A quantitative Evaluation of 3D Shape Matching Algorithms
Nov 05, 2024

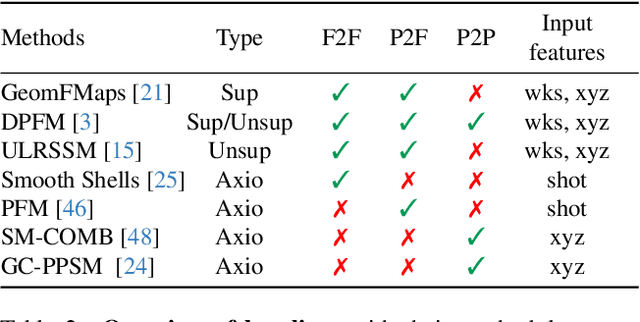
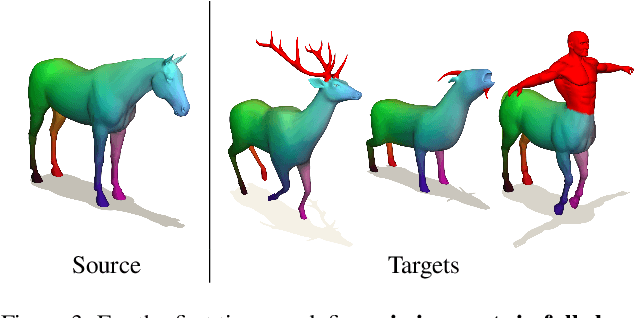
Finding correspondences between 3D shapes is an important and long-standing problem in computer vision, graphics and beyond. While approaches based on machine learning dominate modern 3D shape matching, almost all existing (learning-based) methods require that at least one of the involved shapes is complete. In contrast, the most challenging and arguably most practically relevant setting of matching partially observed shapes, is currently underexplored. One important factor is that existing datasets contain only a small number of shapes (typically below 100), which are unable to serve data-hungry machine learning approaches, particularly in the unsupervised regime. In addition, the type of partiality present in existing datasets is often artificial and far from realistic. To address these limitations and to encourage research on these relevant settings, we provide a generic and flexible framework for the procedural generation of challenging partial shape matching scenarios. Our framework allows for a virtually infinite generation of partial shape matching instances from a finite set of shapes with complete geometry. Further, we manually create cross-dataset correspondences between seven existing (complete geometry) shape matching datasets, leading to a total of 2543 shapes. Based on this, we propose several challenging partial benchmark settings, for which we evaluate respective state-of-the-art methods as baselines.
Synchronous Diffusion for Unsupervised Smooth Non-Rigid 3D Shape Matching
Jul 11, 2024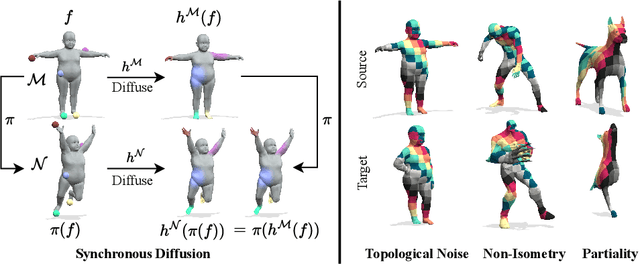


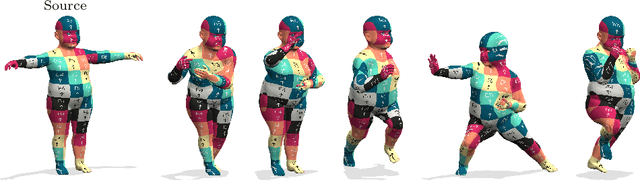
Most recent unsupervised non-rigid 3D shape matching methods are based on the functional map framework due to its efficiency and superior performance. Nevertheless, respective methods struggle to obtain spatially smooth pointwise correspondences due to the lack of proper regularisation. In this work, inspired by the success of message passing on graphs, we propose a synchronous diffusion process which we use as regularisation to achieve smoothness in non-rigid 3D shape matching problems. The intuition of synchronous diffusion is that diffusing the same input function on two different shapes results in consistent outputs. Using different challenging datasets, we demonstrate that our novel regularisation can substantially improve the state-of-the-art in shape matching, especially in the presence of topological noise.
Spectral Meets Spatial: Harmonising 3D Shape Matching and Interpolation
Mar 13, 2024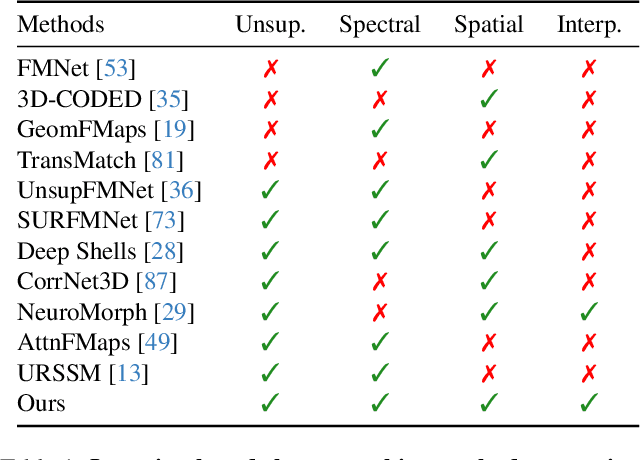
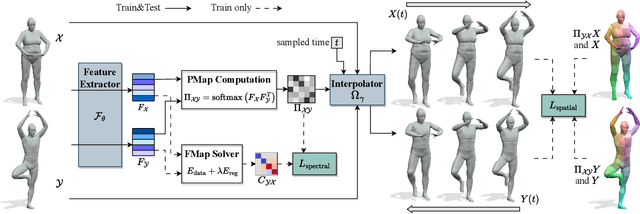
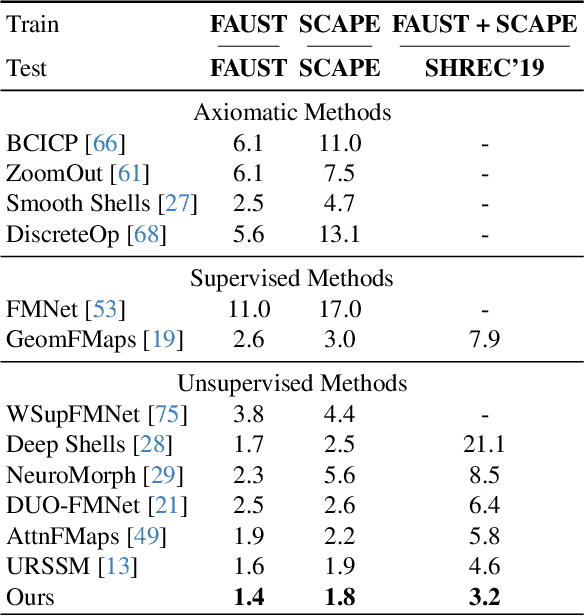
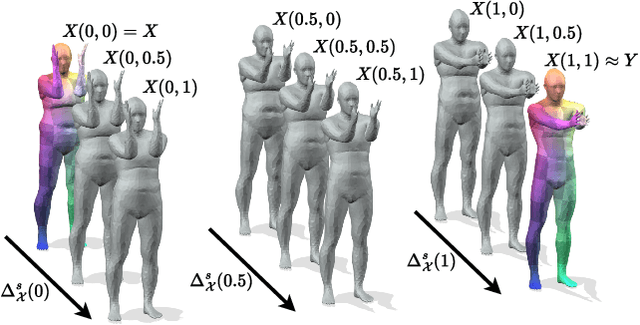
Although 3D shape matching and interpolation are highly interrelated, they are often studied separately and applied sequentially to relate different 3D shapes, thus resulting in sub-optimal performance. In this work we present a unified framework to predict both point-wise correspondences and shape interpolation between 3D shapes. To this end, we combine the deep functional map framework with classical surface deformation models to map shapes in both spectral and spatial domains. On the one hand, by incorporating spatial maps, our method obtains more accurate and smooth point-wise correspondences compared to previous functional map methods for shape matching. On the other hand, by introducing spectral maps, our method gets rid of commonly used but computationally expensive geodesic distance constraints that are only valid for near-isometric shape deformations. Furthermore, we propose a novel test-time adaptation scheme to capture both pose-dominant and shape-dominant deformations. Using different challenging datasets, we demonstrate that our method outperforms previous state-of-the-art methods for both shape matching and interpolation, even compared to supervised approaches.
Revisiting Map Relations for Unsupervised Non-Rigid Shape Matching
Oct 17, 2023
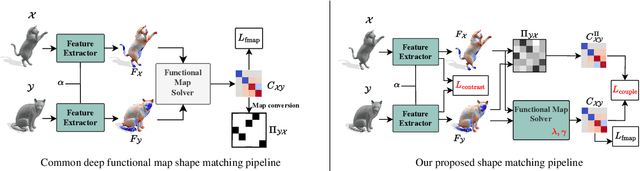
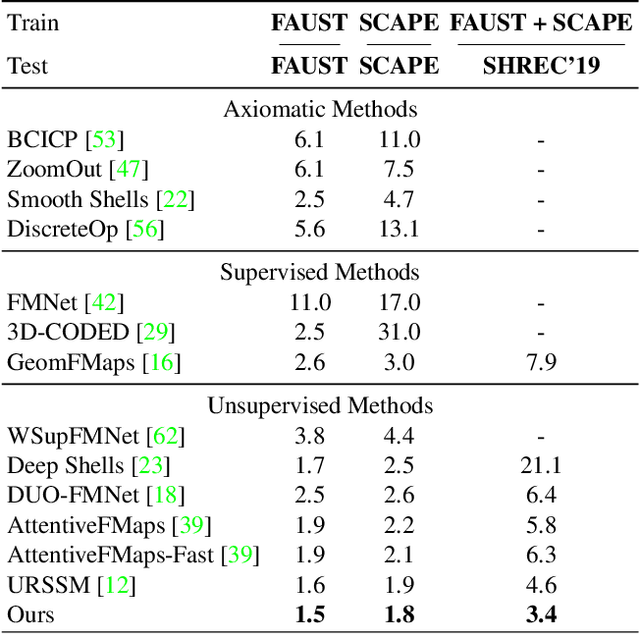
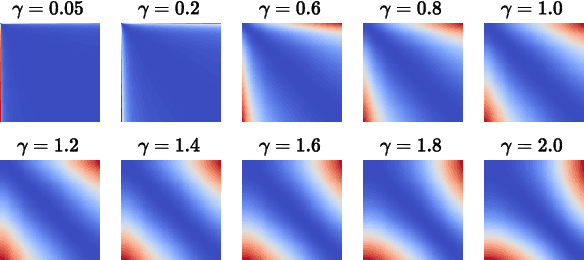
We propose a novel unsupervised learning approach for non-rigid 3D shape matching. Our approach improves upon recent state-of-the art deep functional map methods and can be applied to a broad range of different challenging scenarios. Previous deep functional map methods mainly focus on feature extraction and aim exclusively at obtaining more expressive features for functional map computation. However, the importance of the functional map computation itself is often neglected and the relationship between the functional map and point-wise map is underexplored. In this paper, we systematically investigate the coupling relationship between the functional map from the functional map solver and the point-wise map based on feature similarity. To this end, we propose a self-adaptive functional map solver to adjust the functional map regularisation for different shape matching scenarios, together with a vertex-wise contrastive loss to obtain more discriminative features. Using different challenging datasets (including non-isometry, topological noise and partiality), we demonstrate that our method substantially outperforms previous state-of-the-art methods.
Fast Discrete Optimisation for Geometrically Consistent 3D Shape Matching
Oct 12, 2023
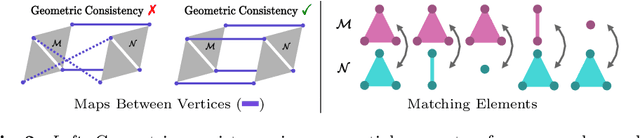
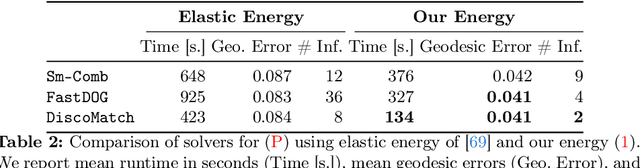
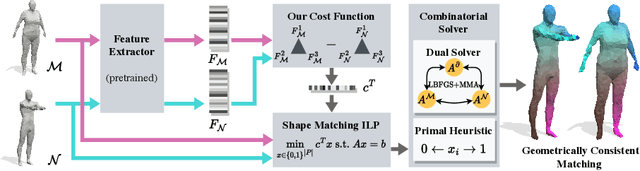
In this work we propose to combine the advantages of learning-based and combinatorial formalisms for 3D shape matching. While learning-based shape matching solutions lead to state-of-the-art matching performance, they do not ensure geometric consistency, so that obtained matchings are locally unsmooth. On the contrary, axiomatic methods allow to take geometric consistency into account by explicitly constraining the space of valid matchings. However, existing axiomatic formalisms are impractical since they do not scale to practically relevant problem sizes, or they require user input for the initialisation of non-convex optimisation problems. In this work we aim to close this gap by proposing a novel combinatorial solver that combines a unique set of favourable properties: our approach is (i) initialisation free, (ii) massively parallelisable powered by a quasi-Newton method, (iii) provides optimality gaps, and (iv) delivers decreased runtime and globally optimal results for many instances.