 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pixel-Level Semantic Left-Right Understanding of In-the-Wild Images
Jul 06, 2026While various works address reflective symmetry understanding in 3D data and images, pixel-level semantic left-right prediction of in-the-wild images remains challenging, due to certain difficulties including the lack of 3D information, occlusion, object pose variation, partiality, etc. In this work, we propose an unsupervised learning framework to tackle this challenge. Leveraging recent advances in vertex-wise semantic left-right understanding of 3D data, our unsupervised learning method jointly utilises 3D shape and image datasets to infer pixel-wise semantic left-right predictions in single-view images. In particular, we show that a medium-scale 3D shape dataset comprising mainly of human- and quadruped animal-like shapes, combined with diverse in-the-wild image data, are sufficient to achieve high-quality semantic left-right prediction in images, even for entirely unseen 3D object categories, such as cars or trains. Overall, our approach achieves superior performance in dense pixel-wise semantic left-right predictions on both rendered and in-the-wild image datasets when compared to existing state-of-the-art methods.
Response time of lateral predictive coding and benefits of modular structures
Apr 22, 2026Lateral predictive coding (LPC) is a simple theoretical framework to appreciate feature detection in biological neural circuits. Recent theoretical work [Huang et al., Phys.Rev.E 112, 034304 (2025)] has successfully constructed optimal LPC networks capable of extracting non-Gaussian hidden input features by imposing the tradeoff between energetic cost and information robustness, but the resulting dynamical systems of recurrent interactions can be very slow in responding to external inputs. We investigate response-time reduction in the present paper. We find that the characteristic response time of the LPC system can be minimized to closely approaching the lower-bound value without compromising the mean predictive error (energetic cost) and the information robustness of signal transmission. We further demonstrate that optimal LPC networks taking a modular structural organization with extensively reduced number of lateral interactions are equally excellent as all-to-all completely connected networks, in terms of feature detection performance, response time, energetic cost and information robustness.
SPAGBias: Uncovering and Tracing Structured Spatial Gender Bias in Large Language Models
Apr 16, 2026Large language models (LLMs) are being increasingly used in urban planning, but since gendered space theory highlights how gender hierarchies are embedded in spatial organization, there is concern that LLMs may reproduce or amplify such biases. We introduce SPAGBias - the first systematic framework to evaluate spatial gender bias in LLMs. It combines a taxonomy of 62 urban micro-spaces, a prompt library, and three diagnostic layers: explicit (forced-choice resampling), probabilistic (token-level asymmetry), and constructional (semantic and narrative role analysis). Testing six representative models, we identify structured gender-space associations that go beyond the public-private divide, forming nuanced micro-level mappings. Story generation reveals how emotion, wording, and social roles jointly shape "spatial gender narratives". We also examine how prompt design, temperature, and model scale influence bias expression. Tracing experiments indicate that these patterns are embedded and reinforced across the model pipeline (pre-training, instruction tuning, and reward modeling), with model associations found to substantially exceed real-world distributions. Downstream experiments further reveal that such biases produce concrete failures in both normative and descriptive application settings. This work connects sociological theory with computational analysis, extending bias research into the spatial domain and uncovering how LLMs encode social gender cognition through language.
Symmetry Informative and Agnostic Feature Disentanglement for 3D Shapes
Jan 21, 2026Shape descriptors, i.e., per-vertex features of 3D meshes or point clouds, are fundamental to shape analysis. Historically, various handcrafted geometry-aware descriptors and feature refinement techniques have been proposed. Recently, several studies have initiated a new research direction by leveraging features from image foundation models to create semantics-aware descriptors, demonstrating advantages across tasks like shape matching, editing, and segmentation. Symmetry, another key concept in shape analysis, has also attracted increasing attention. Consequently, constructing symmetry-aware shape descriptors is a natural progression. Although the recent method $χ$ (Wang et al., 2025) successfully extracted symmetry-informative features from semantic-aware descriptors, its features are only one-dimensional, neglecting other valuable semantic information. Furthermore, the extracted symmetry-informative feature is usually noisy and yields small misclassified patches. To address these gaps, we propose a feature disentanglement approach which is simultaneously symmetry informative and symmetry agnostic. Further, we propose a feature refinement technique to improve the robustness of predicted symmetry informative features. Extensive experiments, including intrinsic symmetry detection, left/right classification, and shape matching, demonstrate the effectiveness of our proposed framework compared to various state-of-the-art methods, both qualitatively and quantitatively.
Symmetry Understanding of 3D Shapes via Chirality Disentanglement
Aug 07, 2025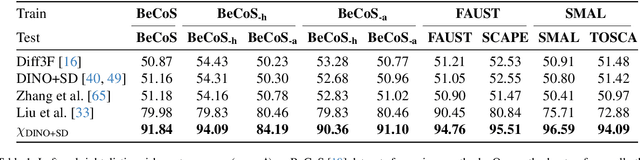
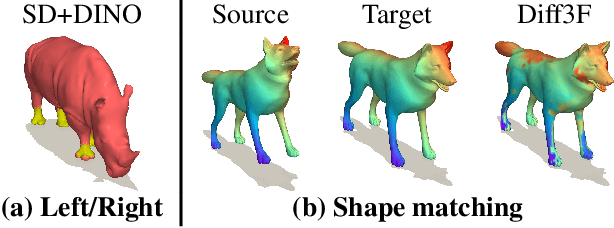
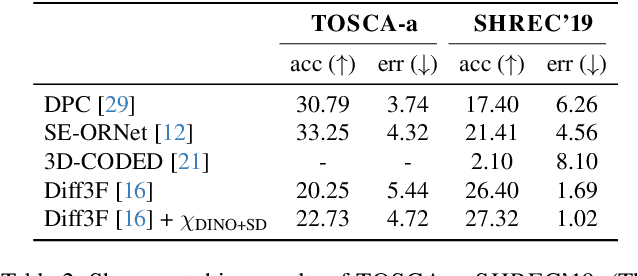
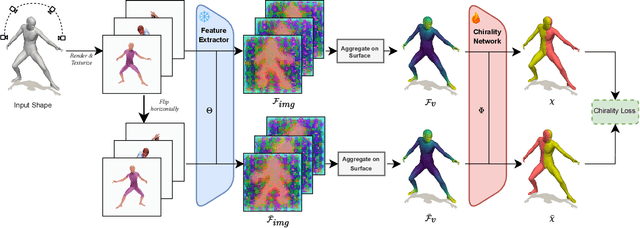
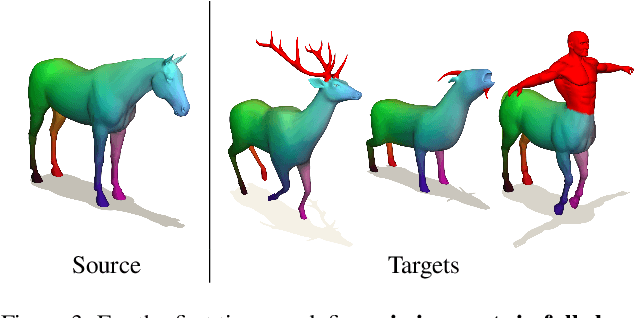
Chirality information (i.e. information that allows distinguishing left from right) is ubiquitous for various data modes in computer vision, including images, videos, point clouds, and meshes. While chirality has been extensively studied in the image domain, its exploration in shape analysis (such as point clouds and meshes) remains underdeveloped. Although many shape vertex descriptors have shown appealing properties (e.g. robustness to rigid-body transformations), they are often not able to disambiguate between left and right symmetric parts. Considering the ubiquity of chirality information in different shape analysis problems and the lack of chirality-aware features within current shape descriptors, developing a chirality feature extractor becomes necessary and urgent. Based on the recent Diff3F framework, we propose an unsupervised chirality feature extraction pipeline to decorate shape vertices with chirality-aware information, extracted from 2D foundation models. We evaluated the extracted chirality features through quantitative and qualitative experiments across diverse datasets. Results from downstream tasks including left-right disentanglement, shape matching, and part segmentation demonstrate their effectiveness and practical utility. Project page: https://wei-kang-wang.github.io/chirality/
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
HUNYUANPROVER: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving
Dec 30, 2024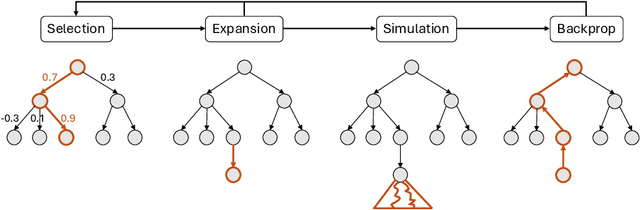
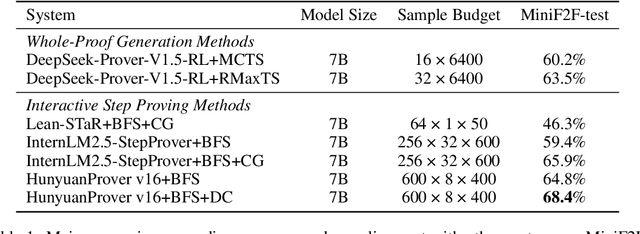

We introduce HunyuanProver, an language model finetuned from the Hunyuan 7B for interactive automatic theorem proving with LEAN4. To alleviate the data sparsity issue, we design a scalable framework to iterative synthesize data with low cost. Besides, guided tree search algorithms are designed to enable effective ``system 2 thinking`` of the prover. HunyuanProver achieves state-of-the-art (SOTA) performances on major benchmarks. Specifically, it achieves a pass of 68.4% on the miniF2F-test compared to 65.9%, the current SOTA results. It proves 4 IMO statements (imo_1960_p2, imo_1962_p2}, imo_1964_p2 and imo_1983_p6) in miniF2F-test. To benefit the community, we will open-source a dataset of 30k synthesized instances, where each instance contains the original question in natural language, the converted statement by autoformalization, and the proof by HunyuanProver.
Beyond Complete Shapes: A quantitative Evaluation of 3D Shape Matching Algorithms
Nov 05, 2024

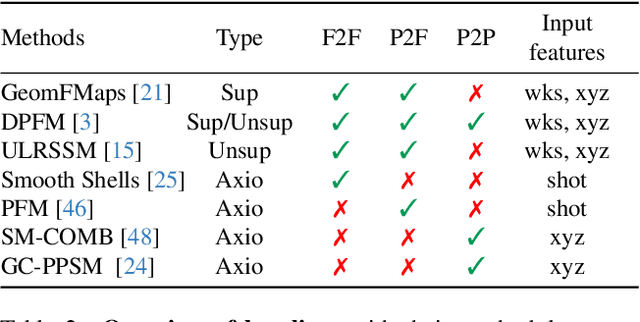
Finding correspondences between 3D shapes is an important and long-standing problem in computer vision, graphics and beyond. While approaches based on machine learning dominate modern 3D shape matching, almost all existing (learning-based) methods require that at least one of the involved shapes is complete. In contrast, the most challenging and arguably most practically relevant setting of matching partially observed shapes, is currently underexplored. One important factor is that existing datasets contain only a small number of shapes (typically below 100), which are unable to serve data-hungry machine learning approaches, particularly in the unsupervised regime. In addition, the type of partiality present in existing datasets is often artificial and far from realistic. To address these limitations and to encourage research on these relevant settings, we provide a generic and flexible framework for the procedural generation of challenging partial shape matching scenarios. Our framework allows for a virtually infinite generation of partial shape matching instances from a finite set of shapes with complete geometry. Further, we manually create cross-dataset correspondences between seven existing (complete geometry) shape matching datasets, leading to a total of 2543 shapes. Based on this, we propose several challenging partial benchmark settings, for which we evaluate respective state-of-the-art methods as baselines.
Taking a Deep Breath: Enhancing Language Modeling of Large Language Models with Sentinel Tokens
Jun 16, 2024



Large language models (LLMs) have shown promising efficacy across various tasks, becoming powerful tools in numerous aspects of human life. However, Transformer-based LLMs suffer a performance degradation when modeling long-term contexts due to they discard some information to reduce computational overhead. In this work, we propose a simple yet effective method to enable LLMs to take a deep breath, encouraging them to summarize information contained within discrete text chunks. Specifically, we segment the text into multiple chunks and insert special token <SR> at the end of each chunk. We then modify the attention mask to integrate the chunk's information into the corresponding <SR> token. This facilitates LLMs to interpret information not only from historical individual tokens but also from the <SR> token, aggregating the chunk's semantic information. Experiments on language modeling and out-of-domain downstream tasks validate the superiority of our approach.
Quite Good, but Not Enough: Nationality Bias in Large Language Models -- A Case Study of ChatGPT
May 11, 2024



While nationality is a pivotal demographic element that enhances the performance of language models, it has received far less scrutiny regarding inherent biases. This study investigates nationality bias in ChatGPT (GPT-3.5), a large language model (LLM) designed for text generation. The research covers 195 countries, 4 temperature settings, and 3 distinct prompt types, generating 4,680 discourses about nationality descriptions in Chinese and English. Automated metrics were used to analyze the nationality bias, and expert annotators alongside ChatGPT itself evaluated the perceived bias. The results show that ChatGPT's generated discourses are predominantly positive, especially compared to its predecessor, GPT-2. However, when prompted with negative inclinations, it occasionally produces negative content. Despite ChatGPT considering its generated text as neutral, it shows consistent self-awareness about nationality bias when subjected to the same pair-wise comparison annotation framework used by human annotators. In conclusion, while ChatGPT's generated texts seem friendly and positive, they reflect the inherent nationality biases in the real world. This bias may vary across different language versions of ChatGPT, indicating diverse cultural perspectives. The study highlights the subtle and pervasive nature of biases within LLMs, emphasizing the need for further scrutiny.