 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Flatten: Video Action Recognition is an Image Classification task
Aug 17, 2024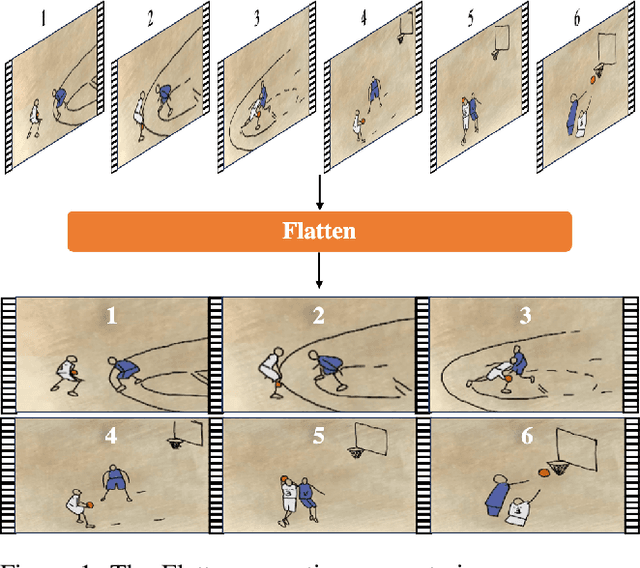
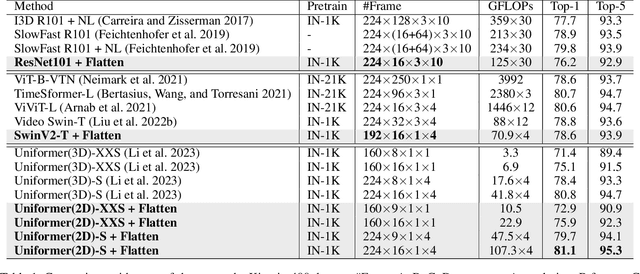
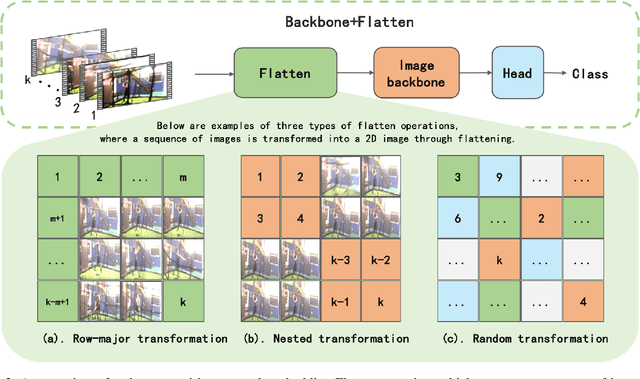
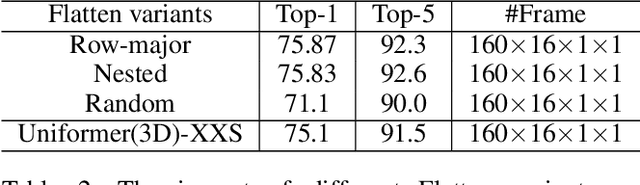
In recent years, video action recognition, as a fundamental task in the field of video understanding, has been deeply explored by numerous researchers.Most traditional video action recognition methods typically involve converting videos into three-dimensional data that encapsulates both spatial and temporal information, subsequently leveraging prevalent image understanding models to model and analyze these data. However,these methods have significant drawbacks. Firstly, when delving into video action recognition tasks, image understanding models often need to be adapted accordingly in terms of model architecture and preprocessing for these spatiotemporal tasks; Secondly, dealing with high-dimensional data often poses greater challenges and incurs higher time costs compared to its lower-dimensional counterparts.To bridge the gap between image-understanding and video-understanding tasks while simplifying the complexity of video comprehension, we introduce a novel video representation architecture, Flatten, which serves as a plug-and-play module that can be seamlessly integrated into any image-understanding network for efficient and effective 3D temporal data modeling.Specifically, by applying specific flattening operations (e.g., row-major transform), 3D spatiotemporal data is transformed into 2D spatial information, and then ordinary image understanding models are used to capture temporal dynamic and spatial semantic information, which in turn accomplishes effective and efficient video action recognition. Extensive experiments on commonly used datasets (Kinetics-400, Something-Something v2, and HMDB-51) and three classical image classification models (Uniformer, SwinV2, and ResNet), have demonstrated that embedding Flatten provides a significant performance improvements over original model.
Are LLMs Effective Backbones for Fine-tuning? An Experimental Investigation of Supervised LLMs on Chinese Short Text Matching
Mar 29, 2024



The recent success of Large Language Models (LLMs) has garnered significant attention in both academia and industry. Prior research on LLMs has primarily focused on enhancing or leveraging their generalization capabilities in zero- and few-shot settings. However, there has been limited investigation into effectively fine-tuning LLMs for a specific natural language understanding task in supervised settings. In this study, we conduct an experimental analysis by fine-tuning LLMs for the task of Chinese short text matching. We explore various factors that influence performance when fine-tuning LLMs, including task modeling methods, prompt formats, and output formats.
UniTSA: A Universal Reinforcement Learning Framework for V2X Traffic Signal Control
Dec 08, 2023



Traffic congestion is a persistent problem in urban areas, which calls for the development of effective traffic signal control (TSC) systems. While existing Reinforcement Learning (RL)-based methods have shown promising performance in optimizing TSC, it is challenging to generalize these methods across intersections of different structures. In this work, a universal RL-based TSC framework is proposed for Vehicle-to-Everything (V2X) environments. The proposed framework introduces a novel agent design that incorporates a junction matrix to characterize intersection states, making the proposed model applicable to diverse intersections. To equip the proposed RL-based framework with enhanced capability of handling various intersection structures, novel traffic state augmentation methods are tailor-made for signal light control systems. Finally, extensive experimental results derived from multiple intersection configurations confirm the effectiveness of the proposed framework. The source code in this work is available at https://github.com/wmn7/Universal_Light
Rate-Splitting Multiple Access for Simultaneous Multi-User Communication and Multi-Target Sensing
Jun 10, 2023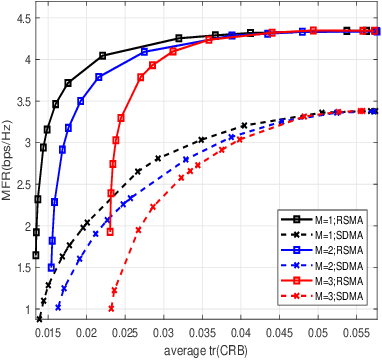
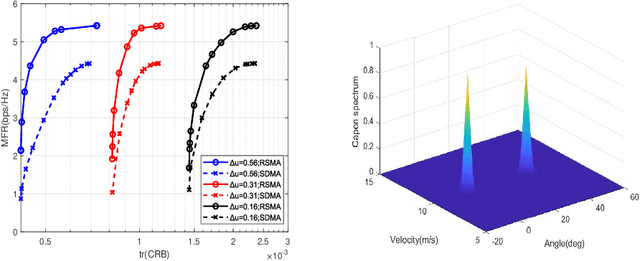
In this paper, we initiate the study of rate-splitting multiple access (RSMA) for a mono-static integrated sensing and communication (ISAC) system, where the dual-functional base station (BS) simultaneously communicates with multiple users and detects multiple moving targets. We aim at optimizing the ISAC waveform to jointly maximize the max-min fairness (MMF) rate of the communication users and minimize the largest eigenvalue of the Cram\'er-Rao bound (CRB) matrix for unbiased estimation. The CRB matrix considered in this work is general as it involves the estimation of angular direction, complex reflection coefficient, and Doppler frequency for multiple moving targets. Simulation results demonstrate that RSMA maintains a larger communication and sensing trade-off than conventional space-division multiple access (SDMA) and it is capable of detecting multiple targets with a high detection accuracy. The finding highlights the potential of RSMA as an effective and powerful strategy for interference management in the general multi-user multi-target ISAC systems.
ADLight: A Universal Approach of Traffic Signal Control with Augmented Data Using Reinforcement Learning
Oct 24, 2022



Traffic signal control has the potential to reduce congestion in dynamic networks. Recent studies show that traffic signal control with reinforcement learning (RL) methods can significantly reduce the average waiting time. However, a shortcoming of existing methods is that they require model retraining for new intersections with different structures. In this paper, we propose a novel reinforcement learning approach with augmented data (ADLight) to train a universal model for intersections with different structures. We propose a new agent design incorporating features on movements and actions with set current phase duration to allow the generalized model to have the same structure for different intersections. A new data augmentation method named \textit{movement shuffle} is developed to improve the generalization performance. We also test the universal model with new intersections in Simulation of Urban MObility (SUMO). The results show that the performance of our approach is close to the models trained in a single environment directly (only a 5% loss of average waiting time), and we can reduce more than 80% of training time, which saves a lot of computational resources in scalable operations of traffic lights.
Rate-Splitting Multiple Access for Multi-Antenna Joint Radar and Communications
Mar 14, 2021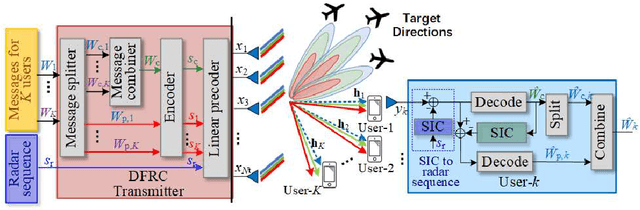
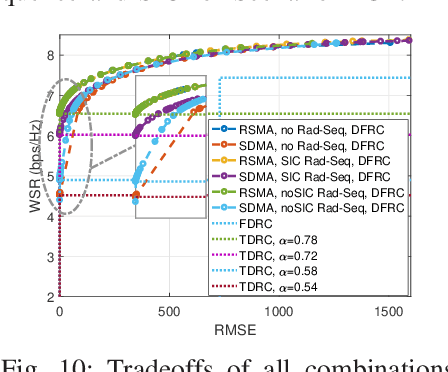
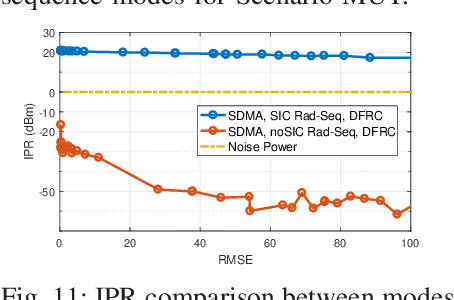
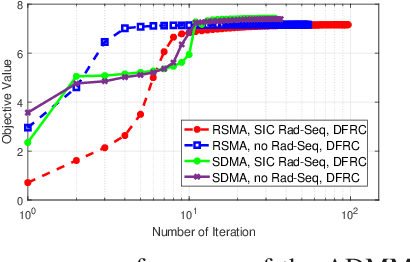
Dual-Functional Radar-Communication (DFRC) system is an essential and promising technique for beyond 5G. In this work, we propose a powerful and unified multi-antenna DFRC transmission framework, where an additional radar sequence is transmitted apart from communication streams to enhance radar beampattern matching capability, and Rate-Splitting Multiple Access (RSMA) is adopted to better manage the interference. RSMA relies on multi-antenna Rate-Splitting (RS) with Successive Interference Cancellation (SIC) receivers, and the split and encoding of messages into common and private streams. We design the message split and the precoders of the radar sequence and communication streams to jointly maximize the Weighted Sum Rate (WSR) and minimize the radar beampattern approximation Mean Square Error (MSE) subject to the per antenna power constraint. An iterative algorithm based on Alternating Direction Method of Multipliers (ADMM) is developed to solve the problem. Numerical results first show that RSMA-assisted DFRC achieves a better tradeoff between WSR and beampattern approximation than Space-Division Multiple Access (SDMA)-assisted DFRC with or without radar sequence, and other simpler radar-communication strategies using orthogonal resources. We also show that the RSMA-assisted DFRC frameworks with and without radar sequence achieve the same tradeoff performance. This is because that the common stream is better exploited in the proposed framework. The common stream of RSMA fulfils the triple function of managing interference among communication users, managing interference between communication and radar, and beampattern approximation. Therefore, by enabling RSMA in DFRC, the system performance is enhanced while the system architecture is simplified since there is no need to use additional radar sequence and SIC. We conclude that RSMA is a more powerful multiple access for DFRC.
Multi-Antenna Joint Radar and Communications: Precoder Optimization and Weighted Sum-Rate vs Probing Power Tradeoff
Jan 28, 2021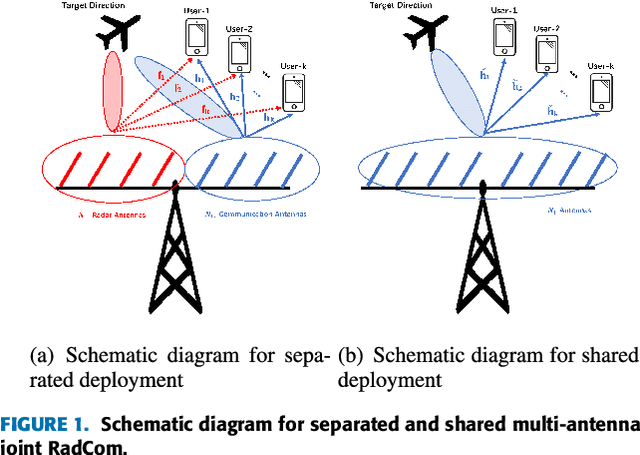
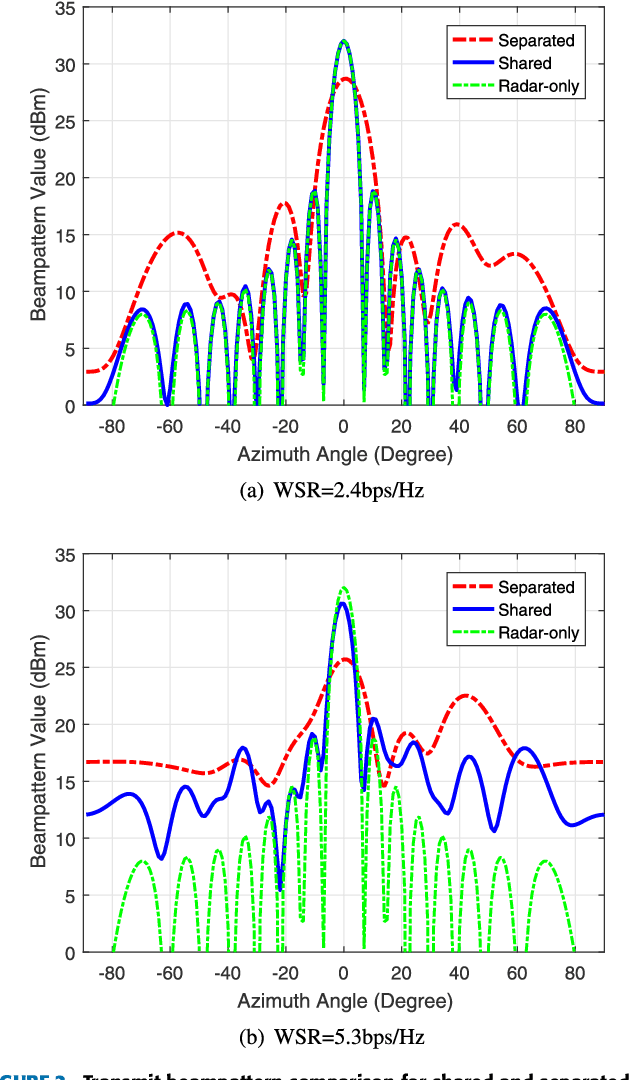
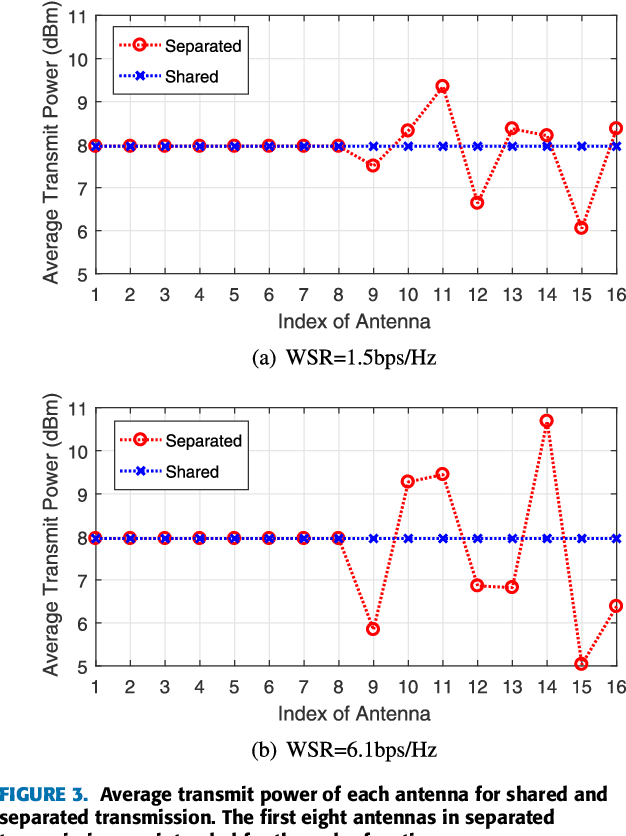
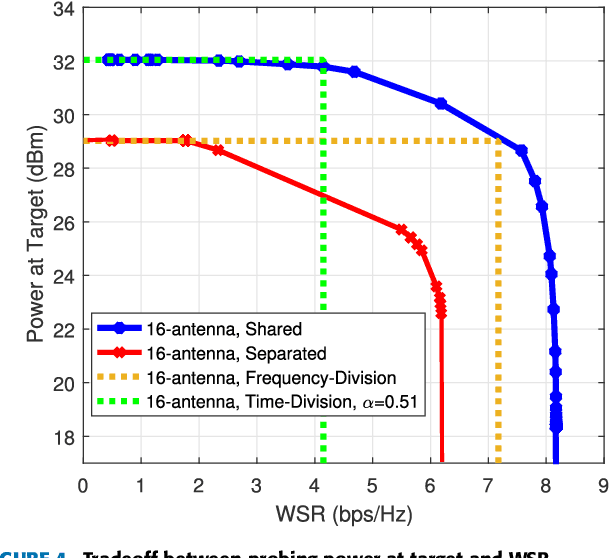
In order to further exploit the potential of joint multi-antenna radar-communication (RadCom) system, we propose two transmission techniques respectively based on separated and shared antenna deployments. Both techniques are designed to maximize the weighted sum rate (WSR) and the probing power at target's location under average power constraints at the antennas such that the system can simultaneously communicate with downlink users and detect the target within the same frequency band. Based on a Weighted Minimized Mean Square Errors (WMMSE) method, the separated deployment transmission is designed via semidefinite programming (SDP) while the shared deployment problem is solved by majorization-minimization (MM) algorithm. Numerical results show that the shared deployment outperforms the separated deployment in radar beamforming. The tradeoffs between WSR and probing power at target are compared among both proposed transmissions and two practically simpler dual-function implementations i.e., time division and frequency division. Results show that although the separated deployment enables spectrum sharing, it experiences a performance loss compared with frequency division, while the shared deployment outperforms both and surpasses time division in certain conditions.