 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization from Low- to Moderate-Resolution Spectra with Neural Networks for Stellar Parameter Estimation: A Case Study with DESI
Feb 16, 2026Cross-survey generalization is a critical challenge in stellar spectral analysis, particularly in cases such as transferring from low- to moderate-resolution surveys. We investigate this problem using pre-trained models, focusing on simple neural networks such as multilayer perceptrons (MLPs), with a case study transferring from LAMOST low-resolution spectra (LRS) to DESI medium-resolution spectra (MRS). Specifically, we pre-train MLPs on either LRS or their embeddings and fine-tune them for application to DESI stellar spectra. We compare MLPs trained directly on spectra with those trained on embeddings derived from transformer-based models (self-supervised foundation models pre-trained for multiple downstream tasks). We also evaluate different fine-tuning strategies, including residual-head adapters, LoRA, and full fine-tuning. We find that MLPs pre-trained on LAMOST LRS achieve strong performance, even without fine-tuning, and that modest fine-tuning with DESI spectra further improves the results. For iron abundance, embeddings from a transformer-based model yield advantages in the metal-rich ([Fe/H] > -1.0) regime, but underperform in the metal-poor regime compared to MLPs trained directly on LRS. We also show that the optimal fine-tuning strategy depends on the specific stellar parameter under consideration. These results highlight that simple pre-trained MLPs can provide competitive cross-survey generalization, while the role of spectral foundation models for cross-survey stellar parameter estimation requires further exploration.
OpAgent: Operator Agent for Web Navigation
Feb 14, 2026To fulfill user instructions, autonomous web agents must contend with the inherent complexity and volatile nature of real-world websites. Conventional paradigms predominantly rely on Supervised Fine-Tuning (SFT) or Offline Reinforcement Learning (RL) using static datasets. However, these methods suffer from severe distributional shifts, as offline trajectories fail to capture the stochastic state transitions and real-time feedback of unconstrained wide web environments. In this paper, we propose a robust Online Reinforcement Learning WebAgent, designed to optimize its policy through direct, iterative interactions with unconstrained wide websites. Our approach comprises three core innovations: 1) Hierarchical Multi-Task Fine-tuning: We curate a comprehensive mixture of datasets categorized by functional primitives -- Planning, Acting, and Grounding -- establishing a Vision-Language Model (VLM) with strong instruction-following capabilities for Web GUI tasks. 2) Online Agentic RL in the Wild: We develop an online interaction environment and fine-tune the VLM using a specialized RL pipeline. We introduce a Hybrid Reward Mechanism that combines a ground-truth-agnostic WebJudge for holistic outcome assessment with a Rule-based Decision Tree (RDT) for progress reward. This system effectively mitigates the credit assignment challenge in long-horizon navigation. Notably, our RL-enhanced model achieves a 38.1\% success rate (pass@5) on WebArena, outperforming all existing monolithic baselines. 3) Operator Agent: We introduce a modular agentic framework, namely \textbf{OpAgent}, orchestrating a Planner, Grounder, Reflector, and Summarizer. This synergy enables robust error recovery and self-correction, elevating the agent's performance to a new State-of-the-Art (SOTA) success rate of \textbf{71.6\%}.
SpecCLIP: Aligning and Translating Spectroscopic Measurements for Stars
Jul 02, 2025In recent years, large language models (LLMs) have transformed natural language understanding through vast datasets and large-scale parameterization. Inspired by this success, we present SpecCLIP, a foundation model framework that extends LLM-inspired methodologies to stellar spectral analysis. Stellar spectra, akin to structured language, encode rich physical and chemical information about stars. By training foundation models on large-scale spectral datasets, our goal is to learn robust and informative embeddings that support diverse downstream applications. As a proof of concept, SpecCLIP involves pre-training on two spectral types--LAMOST low-resolution and Gaia XP--followed by contrastive alignment using the CLIP (Contrastive Language-Image Pre-training) framework, adapted to associate spectra from different instruments. This alignment is complemented by auxiliary decoders that preserve spectrum-specific information and enable translation (prediction) between spectral types, with the former achieved by maximizing mutual information between embeddings and input spectra. The result is a cross-spectrum framework enabling intrinsic calibration and flexible applications across instruments. We demonstrate that fine-tuning these models on moderate-sized labeled datasets improves adaptability to tasks such as stellar-parameter estimation and chemical-abundance determination. SpecCLIP also enhances the accuracy and precision of parameter estimates benchmarked against external survey data. Additionally, its similarity search and cross-spectrum prediction capabilities offer potential for anomaly detection. Our results suggest that contrastively trained foundation models enriched with spectrum-aware decoders can advance precision stellar spectroscopy.
UAV-Aided Progressive Interference Source Localization Based on Improved Trust Region Optimization
Apr 27, 2025



Trust region optimization-based received signal strength indicator (RSSI) interference source localization methods have been widely used in low-altitude research. However, these methods often converge to local optima in complex environments, degrading the positioning performance. This paper presents a novel unmanned aerial vehicle (UAV)-aided progressive interference source localization method based on improved trust region optimization. By combining the Levenberg-Marquardt (LM) algorithm with particle swarm optimization (PSO), our proposed method can effectively enhance the success rate of localization. We also propose a confidence quantification approach based on the UAV-to-ground channel model. This approach considers the surrounding environmental information of the sampling points and dynamically adjusts the weight of the sampling data during the data fusion. As a result, the overall positioning accuracy can be significantly improved. Experimental results demonstrate the proposed method can achieve high-precision interference source localization in noisy and interference-prone environments.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
The Scaling Law in Stellar Light Curves
May 27, 2024Analyzing time series of fluxes from stars, known as stellar light curves, can reveal valuable information about stellar properties. However, most current methods rely on extracting summary statistics, and studies using deep learning have been limited to supervised approaches. In this research, we investigate the scaling law properties that emerge when learning from astronomical time series data using self-supervised techniques. By employing the GPT-2 architecture, we show the learned representation improves as the number of parameters increases from $10^4$ to $10^9$, with no signs of performance plateauing. We demonstrate that a self-supervised Transformer model achieves 3-10 times the sample efficiency compared to the state-of-the-art supervised learning model when inferring the surface gravity of stars as a downstream task. Our research lays the groundwork for analyzing stellar light curves by examining them through large-scale auto-regressive generative models.
Distributed Multi-Objective Dynamic Offloading Scheduling for Air-Ground Cooperative MEC
Mar 16, 2024



Utilizing unmanned aerial vehicles (UAVs) with edge server to assist terrestrial mobile edge computing (MEC) has attracted tremendous attention. Nevertheless, state-of-the-art schemes based on deterministic optimizations or single-objective reinforcement learning (RL) cannot reduce the backlog of task bits and simultaneously improve energy efficiency in highly dynamic network environments, where the design problem amounts to a sequential decision-making problem. In order to address the aforementioned problems, as well as the curses of dimensionality introduced by the growing number of terrestrial terrestrial users, this paper proposes a distributed multi-objective (MO) dynamic trajectory planning and offloading scheduling scheme, integrated with MORL and the kernel method. The design of n-step return is also applied to average fluctuations in the backlog. Numerical results reveal that the n-step return can benefit the proposed kernel-based approach, achieving significant improvement in the long-term average backlog performance, compared to the conventional 1-step return design. Due to such design and the kernel-based neural network, to which decision-making features can be continuously added, the kernel-based approach can outperform the approach based on fully-connected deep neural network, yielding improvement in energy consumption and the backlog performance, as well as a significant reduction in decision-making and online learning time.
Rate-Splitting Multiple Access for Simultaneous Multi-User Communication and Multi-Target Sensing
Jun 10, 2023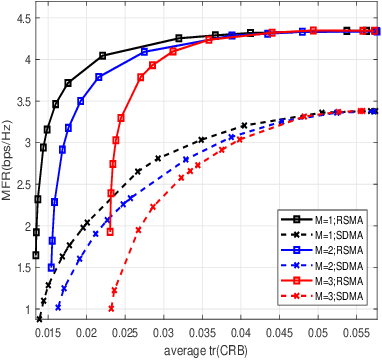
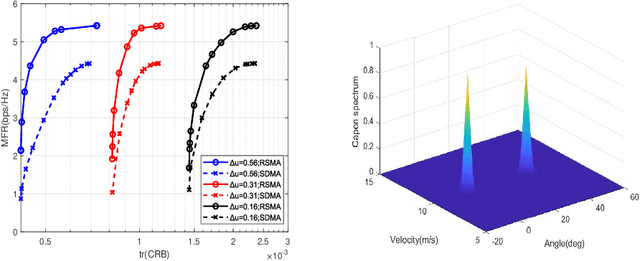
In this paper, we initiate the study of rate-splitting multiple access (RSMA) for a mono-static integrated sensing and communication (ISAC) system, where the dual-functional base station (BS) simultaneously communicates with multiple users and detects multiple moving targets. We aim at optimizing the ISAC waveform to jointly maximize the max-min fairness (MMF) rate of the communication users and minimize the largest eigenvalue of the Cram\'er-Rao bound (CRB) matrix for unbiased estimation. The CRB matrix considered in this work is general as it involves the estimation of angular direction, complex reflection coefficient, and Doppler frequency for multiple moving targets. Simulation results demonstrate that RSMA maintains a larger communication and sensing trade-off than conventional space-division multiple access (SDMA) and it is capable of detecting multiple targets with a high detection accuracy. The finding highlights the potential of RSMA as an effective and powerful strategy for interference management in the general multi-user multi-target ISAC systems.
FAN: Fatigue-Aware Network for Click-Through Rate Prediction in E-commerce Recommendation
Apr 10, 2023Since clicks usually contain heavy noise, increasing research efforts have been devoted to modeling implicit negative user behaviors (i.e., non-clicks). However, they either rely on explicit negative user behaviors (e.g., dislikes) or simply treat non-clicks as negative feedback, failing to learn negative user interests comprehensively. In such situations, users may experience fatigue because of seeing too many similar recommendations. In this paper, we propose Fatigue-Aware Network (FAN), a novel CTR model that directly perceives user fatigue from non-clicks. Specifically, we first apply Fourier Transformation to the time series generated from non-clicks, obtaining its frequency spectrum which contains comprehensive information about user fatigue. Then the frequency spectrum is modulated by category information of the target item to model the bias that both the upper bound of fatigue and users' patience is different for different categories. Moreover, a gating network is adopted to model the confidence of user fatigue and an auxiliary task is designed to guide the learning of user fatigue, so we can obtain a well-learned fatigue representation and combine it with user interests for the final CTR prediction. Experimental results on real-world datasets validate the superiority of FAN and online A/B tests also show FAN outperforms representative CTR models significantly.
Sparse Bayesian Learning-Based 3D Spectrum Environment Map Construction-Sampling Optimization, Scenario-Dependent Dictionary Construction and Sparse Recovery
Feb 25, 2023



The spectrum environment map (SEM), which can visualize the information of invisible electromagnetic spectrum, is vital for monitoring, management, and security of spectrum resources in cognitive radio (CR) networks. In view of a limited number of spectrum sensors and constrained sampling time, this paper presents a new three-dimensional (3D) SEM construction scheme based on sparse Bayesian learning (SBL). Firstly, we construct a scenario-dependent channel dictionary matrix by considering the propagation characteristic of the interested scenario. To improve sampling efficiency, a maximum mutual information (MMI)-based optimization algorithm is developed for the layout of sampling sensors. Then, a maximum and minimum distance (MMD) clustering-based SBL algorithm is proposed to recover the spectrum data at the unsampled positions and construct the whole 3D SEM. We finally use the simulation data of the campus scenario to construct the 3D SEMs and compare the proposed method with the state-of-the-art. The recovery performance and the impact of different sparsity on the constructed SEMs are also analyzed. Numerical results show that the proposed scheme can reduce the required spectrum sensor number and has higher accuracy under the low sampling rate.