 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiSAR-Net++: A Large-Scale Benchmark and Transformer-Free Framework for Cross-Domain Remote Sensing Visual Grounding
Mar 25, 2026Remote sensing visual grounding (RSVG) aims to localize specific targets in remote sensing images using natural language expressions. However, existing methods are restricted to single-sensor domains, i.e., either optical or synthetic aperture radar (SAR), limiting their real-world applicability. In this paper, we introduce the Cross-Domain RSVG (CD-RSVG) task and construct OptSAR-RSVG, the first large-scale benchmark dataset for this setting. To tackle the challenges of cross-domain feature modeling, computational inefficiency, and fine-grained semantic discrimination, we propose OptiSAR-Net++. Our framework features a patch-level Low-Rank Adaptation Mixture of Experts (PL-MoE) for efficient cross-domain feature decoupling. To mitigate the substantial computational overhead of Transformer decoding frameworks, we adopt a CLIP-based contrastive paradigm and further incorporate dynamic adversarial negative sampling, thereby transforming generative regression into an efficient cross-modal matching process. Additionally, a text-guided dual-gate fusion module (TGDF-SSA) and a region-aware auxiliary head are introduced to enhance semantic-visual alignment and spatial modeling. Extensive experiments demonstrate that OptiSAR-Net++ achieves SOTA performance on both OptSAR-RSVG and DIOR-RSVG benchmarks, offering significant advantages in localization accuracy and efficiency. Our code and dataset will be made publicly available.
VLA-IAP: Training-Free Visual Token Pruning via Interaction Alignment for Vision-Language-Action Models
Mar 24, 2026Vision-Language-Action (VLA) models have rapidly advanced embodied intelligence, enabling robots to execute complex, instruction-driven tasks. However, as model capacity and visual context length grow, the inference cost of VLA systems becomes a major bottleneck for real-world deployment on resource-constrained platforms. Existing visual token pruning methods mainly rely on semantic saliency or simple temporal cues, overlooking the continuous physical interaction, a fundamental property of VLA tasks. Consequently, current approaches often prune visually sparse yet structurally critical regions that support manipulation, leading to unstable behavior during early task phases. To overcome this, we propose a shift toward an explicit Interaction-First paradigm. Our proposed \textbf{training-free} method, VLA-IAP (Interaction-Aligned Pruning), introduces a geometric prior mechanism to preserve structural anchors and a dynamic scheduling strategy that adapts pruning intensity based on semantic-motion alignment. This enables a conservative-to-aggressive transition, ensuring robustness during early uncertainty and efficiency once interaction is locked. Extensive experiments show that VLA-IAP achieves a \textbf{97.8\% success rate} with a \textbf{$1.25\times$ speedup} on the LIBERO benchmark, and up to \textbf{$1.54\times$ speedup} while maintaining performance \textbf{comparable to the unpruned backbone}. Moreover, the method demonstrates superior and consistent performance across multiple model architectures and three different simulation environments, as well as a real robot platform, validating its strong generalization capability and practical applicability. Our project website is: \href{https://chengjt1999.github.io/VLA-IAP.github.io/}{VLA-IAP.com}.
Decoding Ambiguous Emotions with Test-Time Scaling in Audio-Language Models
Feb 01, 2026Emotion recognition from human speech is a critical enabler for socially aware conversational AI. However, while most prior work frames emotion recognition as a categorical classification problem, real-world affective states are often ambiguous, overlapping, and context-dependent, posing significant challenges for both annotation and automatic modeling. Recent large-scale audio language models (ALMs) offer new opportunities for nuanced affective reasoning without explicit emotion supervision, but their capacity to handle ambiguous emotions remains underexplored. At the same time, advances in inference-time techniques such as test-time scaling (TTS) have shown promise for improving generalization and adaptability in hard NLP tasks, but their relevance to affective computing is still largely unknown. In this work, we introduce the first benchmark for ambiguous emotion recognition in speech with ALMs under test-time scaling. Our evaluation systematically compares eight state-of-the-art ALMs and five TTS strategies across three prominent speech emotion datasets. We further provide an in-depth analysis of the interaction between model capacity, TTS, and affective ambiguity, offering new insights into the computational and representational challenges of ambiguous emotion understanding. Our benchmark establishes a foundation for developing more robust, context-aware, and emotionally intelligent speech-based AI systems, and highlights key future directions for bridging the gap between model assumptions and the complexity of real-world human emotion.
Device Association and Resource Allocation for Hierarchical Split Federated Learning in Space-Air-Ground Integrated Network
Jan 20, 20266G facilitates deployment of Federated Learning (FL) in the Space-Air-Ground Integrated Network (SAGIN), yet FL confronts challenges such as resource constrained and unbalanced data distribution. To address these issues, this paper proposes a Hierarchical Split Federated Learning (HSFL) framework and derives its upper bound of loss function. To minimize the weighted sum of training loss and latency, we formulate a joint optimization problem that integrates device association, model split layer selection, and resource allocation. We decompose the original problem into several subproblems, where an iterative optimization algorithm for device association and resource allocation based on brute-force split point search is proposed. Simulation results demonstrate that the proposed algorithm can effectively balance training efficiency and model accuracy for FL in SAGIN.
Diffusion-Based Restoration for Multi-Modal 3D Object Detection in Adverse Weather
Dec 18, 2025Multi-modal 3D object detection is important for reliable perception in robotics and autonomous driving. However, its effectiveness remains limited under adverse weather conditions due to weather-induced distortions and misalignment between different data modalities. In this work, we propose DiffFusion, a novel framework designed to enhance robustness in challenging weather through diffusion-based restoration and adaptive cross-modal fusion. Our key insight is that diffusion models possess strong capabilities for denoising and generating data that can adapt to various weather conditions. Building on this, DiffFusion introduces Diffusion-IR restoring images degraded by weather effects and Point Cloud Restoration (PCR) compensating for corrupted LiDAR data using image object cues. To tackle misalignments between two modalities, we develop Bidirectional Adaptive Fusion and Alignment Module (BAFAM). It enables dynamic multi-modal fusion and bidirectional bird's-eye view (BEV) alignment to maintain consistent spatial correspondence. Extensive experiments on three public datasets show that DiffFusion achieves state-of-the-art robustness under adverse weather while preserving strong clean-data performance. Zero-shot results on the real-world DENSE dataset further validate its generalization. The implementation of our DiffFusion will be released as open-source.
A Pseudo Global Fusion Paradigm-Based Cross-View Network for LiDAR-Based Place Recognition
Aug 12, 2025LiDAR-based Place Recognition (LPR) remains a critical task in Embodied Artificial Intelligence (AI) and Autonomous Driving, primarily addressing localization challenges in GPS-denied environments and supporting loop closure detection. Existing approaches reduce place recognition to a Euclidean distance-based metric learning task, neglecting the feature space's intrinsic structures and intra-class variances. Such Euclidean-centric formulation inherently limits the model's capacity to capture nonlinear data distributions, leading to suboptimal performance in complex environments and temporal-varying scenarios. To address these challenges, we propose a novel cross-view network based on an innovative fusion paradigm. Our framework introduces a pseudo-global information guidance mechanism that coordinates multi-modal branches to perform feature learning within a unified semantic space. Concurrently, we propose a Manifold Adaptation and Pairwise Variance-Locality Learning Metric that constructs a Symmetric Positive Definite (SPD) matrix to compute Mahalanobis distance, superseding traditional Euclidean distance metrics. This geometric formulation enables the model to accurately characterize intrinsic data distributions and capture complex inter-class dependencies within the feature space. Experimental results demonstrate that the proposed algorithm achieves competitive performance, particularly excelling in complex environmental conditions.
SpecCLIP: Aligning and Translating Spectroscopic Measurements for Stars
Jul 02, 2025In recent years, large language models (LLMs) have transformed natural language understanding through vast datasets and large-scale parameterization. Inspired by this success, we present SpecCLIP, a foundation model framework that extends LLM-inspired methodologies to stellar spectral analysis. Stellar spectra, akin to structured language, encode rich physical and chemical information about stars. By training foundation models on large-scale spectral datasets, our goal is to learn robust and informative embeddings that support diverse downstream applications. As a proof of concept, SpecCLIP involves pre-training on two spectral types--LAMOST low-resolution and Gaia XP--followed by contrastive alignment using the CLIP (Contrastive Language-Image Pre-training) framework, adapted to associate spectra from different instruments. This alignment is complemented by auxiliary decoders that preserve spectrum-specific information and enable translation (prediction) between spectral types, with the former achieved by maximizing mutual information between embeddings and input spectra. The result is a cross-spectrum framework enabling intrinsic calibration and flexible applications across instruments. We demonstrate that fine-tuning these models on moderate-sized labeled datasets improves adaptability to tasks such as stellar-parameter estimation and chemical-abundance determination. SpecCLIP also enhances the accuracy and precision of parameter estimates benchmarked against external survey data. Additionally, its similarity search and cross-spectrum prediction capabilities offer potential for anomaly detection. Our results suggest that contrastively trained foundation models enriched with spectrum-aware decoders can advance precision stellar spectroscopy.
KDMOS:Knowledge Distillation for Motion Segmentation
Jun 17, 2025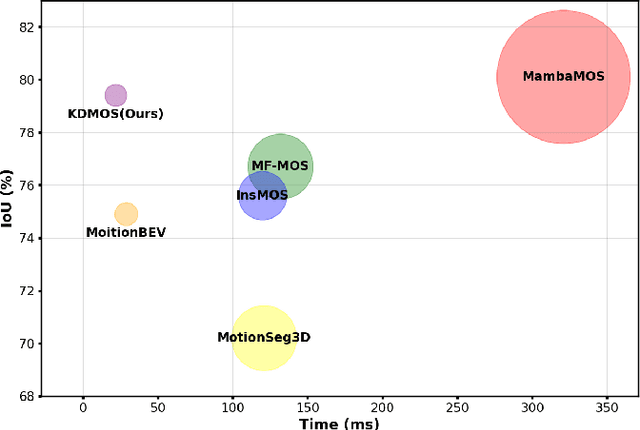
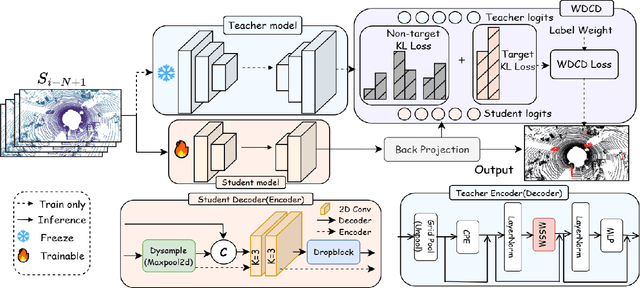
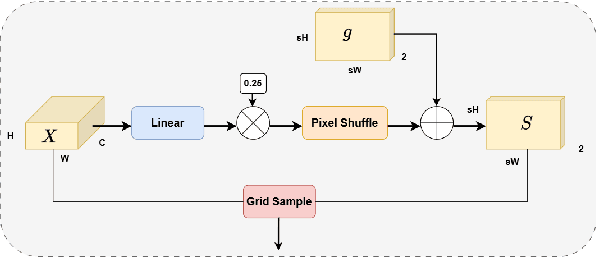
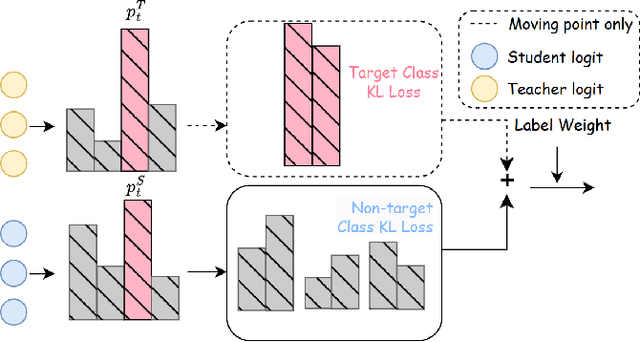
Motion Object Segmentation (MOS) is crucial for autonomous driving, as it enhances localization, path planning, map construction, scene flow estimation, and future state prediction. While existing methods achieve strong performance, balancing accuracy and real-time inference remains a challenge. To address this, we propose a logits-based knowledge distillation framework for MOS, aiming to improve accuracy while maintaining real-time efficiency. Specifically, we adopt a Bird's Eye View (BEV) projection-based model as the student and a non-projection model as the teacher. To handle the severe imbalance between moving and non-moving classes, we decouple them and apply tailored distillation strategies, allowing the teacher model to better learn key motion-related features. This approach significantly reduces false positives and false negatives. Additionally, we introduce dynamic upsampling, optimize the network architecture, and achieve a 7.69% reduction in parameter count, mitigating overfitting. Our method achieves a notable IoU of 78.8% on the hidden test set of the SemanticKITTI-MOS dataset and delivers competitive results on the Apollo dataset. The KDMOS implementation is available at https://github.com/SCNU-RISLAB/KDMOS.
DPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving
Apr 23, 2025



Modern robots must coexist with humans in dense urban environments. A key challenge is the ghost probe problem, where pedestrians or objects unexpectedly rush into traffic paths. This issue affects both autonomous vehicles and human drivers. Existing works propose vehicle-to-everything (V2X) strategies and non-line-of-sight (NLOS) imaging for ghost probe zone detection. However, most require high computational power or specialized hardware, limiting real-world feasibility. Additionally, many methods do not explicitly address this issue. To tackle this, we propose DPGP, a hybrid 2D-3D fusion framework for ghost probe zone prediction using only a monocular camera during training and inference. With unsupervised depth prediction, we observe ghost probe zones align with depth discontinuities, but different depth representations offer varying robustness. To exploit this, we fuse multiple feature embeddings to improve prediction. To validate our approach, we created a 12K-image dataset annotated with ghost probe zones, carefully sourced and cross-checked for accuracy. Experimental results show our framework outperforms existing methods while remaining cost-effective. To our knowledge, this is the first work extending ghost probe zone prediction beyond vehicles, addressing diverse non-vehicle objects. We will open-source our code and dataset for community benefit.
You Sense Only Once Beneath: Ultra-Light Real-Time Underwater Object Detection
Apr 22, 2025Despite the remarkable achievements in object detection, the model's accuracy and efficiency still require further improvement under challenging underwater conditions, such as low image quality and limited computational resources. To address this, we propose an Ultra-Light Real-Time Underwater Object Detection framework, You Sense Only Once Beneath (YSOOB). Specifically, we utilize a Multi-Spectrum Wavelet Encoder (MSWE) to perform frequency-domain encoding on the input image, minimizing the semantic loss caused by underwater optical color distortion. Furthermore, we revisit the unique characteristics of even-sized and transposed convolutions, allowing the model to dynamically select and enhance key information during the resampling process, thereby improving its generalization ability. Finally, we eliminate model redundancy through a simple yet effective channel compression and reconstructed large kernel convolution (RLKC) to achieve model lightweight. As a result, forms a high-performance underwater object detector YSOOB with only 1.2 million parameters. Extensive experimental results demonstrate that, with the fewest parameters, YSOOB achieves mAP50 of 83.1% and 82.9% on the URPC2020 and DUO datasets, respectively, comparable to the current SOTA detectors. The inference speed reaches 781.3 FPS and 57.8 FPS on the T4 GPU (TensorRT FP16) and the edge computing device Jetson Xavier NX (TensorRT FP16), surpassing YOLOv12-N by 28.1% and 22.5%, respectively.