 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDST-Calib: A Dual-Path, Self-Supervised, Target-Free LiDAR-Camera Extrinsic Calibration Network
Jan 03, 2026LiDAR-camera extrinsic calibration is essential for multi-modal data fusion in robotic perception systems. However, existing approaches typically rely on handcrafted calibration targets (e.g., checkerboards) or specific, static scene types, limiting their adaptability and deployment in real-world autonomous and robotic applications. This article presents the first self-supervised LiDAR-camera extrinsic calibration network that operates in an online fashion and eliminates the need for specific calibration targets. We first identify a significant generalization degradation problem in prior methods, caused by the conventional single-sided data augmentation strategy. To overcome this limitation, we propose a novel double-sided data augmentation technique that generates multi-perspective camera views using estimated depth maps, thereby enhancing robustness and diversity during training. Built upon this augmentation strategy, we design a dual-path, self-supervised calibration framework that reduces the dependence on high-precision ground truth labels and supports fully adaptive online calibration. Furthermore, to improve cross-modal feature association, we replace the traditional dual-branch feature extraction design with a difference map construction process that explicitly correlates LiDAR and camera features. This not only enhances calibration accuracy but also reduces model complexity. Extensive experiments conducted on five public benchmark datasets, as well as our own recorded dataset, demonstrate that the proposed method significantly outperforms existing approaches in terms of generalizability.
Diffusion-Based Restoration for Multi-Modal 3D Object Detection in Adverse Weather
Dec 18, 2025Multi-modal 3D object detection is important for reliable perception in robotics and autonomous driving. However, its effectiveness remains limited under adverse weather conditions due to weather-induced distortions and misalignment between different data modalities. In this work, we propose DiffFusion, a novel framework designed to enhance robustness in challenging weather through diffusion-based restoration and adaptive cross-modal fusion. Our key insight is that diffusion models possess strong capabilities for denoising and generating data that can adapt to various weather conditions. Building on this, DiffFusion introduces Diffusion-IR restoring images degraded by weather effects and Point Cloud Restoration (PCR) compensating for corrupted LiDAR data using image object cues. To tackle misalignments between two modalities, we develop Bidirectional Adaptive Fusion and Alignment Module (BAFAM). It enables dynamic multi-modal fusion and bidirectional bird's-eye view (BEV) alignment to maintain consistent spatial correspondence. Extensive experiments on three public datasets show that DiffFusion achieves state-of-the-art robustness under adverse weather while preserving strong clean-data performance. Zero-shot results on the real-world DENSE dataset further validate its generalization. The implementation of our DiffFusion will be released as open-source.
OMUDA: Omni-level Masking for Unsupervised Domain Adaptation in Semantic Segmentation
Dec 13, 2025Unsupervised domain adaptation (UDA) enables semantic segmentation models to generalize from a labeled source domain to an unlabeled target domain. However, existing UDA methods still struggle to bridge the domain gap due to cross-domain contextual ambiguity, inconsistent feature representations, and class-wise pseudo-label noise. To address these challenges, we propose Omni-level Masking for Unsupervised Domain Adaptation (OMUDA), a unified framework that introduces hierarchical masking strategies across distinct representation levels. Specifically, OMUDA comprises: 1) a Context-Aware Masking (CAM) strategy that adaptively distinguishes foreground from background to balance global context and local details; 2) a Feature Distillation Masking (FDM) strategy that enhances robust and consistent feature learning through knowledge transfer from pre-trained models; and 3) a Class Decoupling Masking (CDM) strategy that mitigates the impact of noisy pseudo-labels by explicitly modeling class-wise uncertainty. This hierarchical masking paradigm effectively reduces the domain shift at the contextual, representational, and categorical levels, providing a unified solution beyond existing approaches. Extensive experiments on multiple challenging cross-domain semantic segmentation benchmarks validate the effectiveness of OMUDA. Notably, on the SYNTHIA->Cityscapes and GTA5->Cityscapes tasks, OMUDA can be seamlessly integrated into existing UDA methods and consistently achieving state-of-the-art results with an average improvement of 7%.
Uni-Hand: Universal Hand Motion Forecasting in Egocentric Views
Nov 18, 2025Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.
Latent-Space Autoregressive World Model for Efficient and Robust Image-Goal Navigation
Nov 14, 2025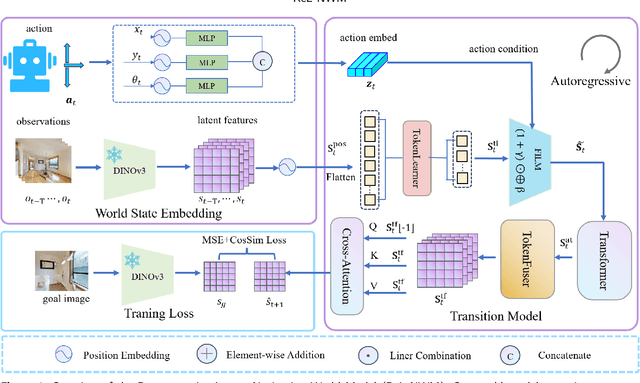
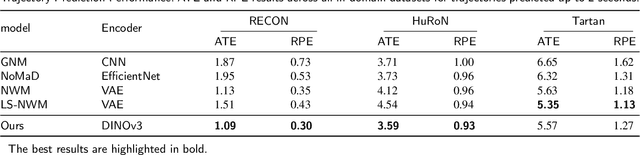

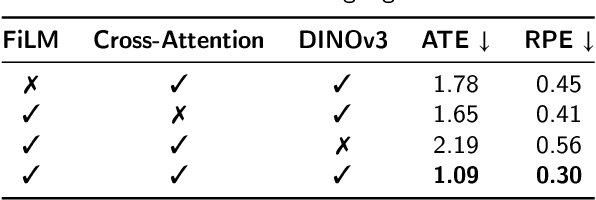
Traditional navigation methods rely heavily on accurate localization and mapping. In contrast, world models that capture environmental dynamics in latent space have opened up new perspectives for navigation tasks, enabling systems to move beyond traditional multi-module pipelines. However, world model often suffers from high computational costs in both training and inference. To address this, we propose LS-NWM - a lightweight latent space navigation world model that is trained and operates entirely in latent space, compared to the state-of-the-art baseline, our method reduces training time by approximately 3.2x and planning time by about 447x,while further improving navigation performance with a 35% higher SR and an 11% higher SPL. The key idea is that accurate pixel-wise environmental prediction is unnecessary for navigation. Instead, the model predicts future latent states based on current observational features and action inputs, then performs path planning and decision-making within this compact representation, significantly improving computational efficiency. By incorporating an autoregressive multi-frame prediction strategy during training, the model effectively captures long-term spatiotemporal dependencies, thereby enhancing navigation performance in complex scenarios. Experimental results demonstrate that our method achieves state-of-the-art navigation performance while maintaining a substantial efficiency advantage over existing approaches.
Grasp Like Humans: Learning Generalizable Multi-Fingered Grasping from Human Proprioceptive Sensorimotor Integration
Sep 10, 2025



Tactile and kinesthetic perceptions are crucial for human dexterous manipulation, enabling reliable grasping of objects via proprioceptive sensorimotor integration. For robotic hands, even though acquiring such tactile and kinesthetic feedback is feasible, establishing a direct mapping from this sensory feedback to motor actions remains challenging. In this paper, we propose a novel glove-mediated tactile-kinematic perception-prediction framework for grasp skill transfer from human intuitive and natural operation to robotic execution based on imitation learning, and its effectiveness is validated through generalized grasping tasks, including those involving deformable objects. Firstly, we integrate a data glove to capture tactile and kinesthetic data at the joint level. The glove is adaptable for both human and robotic hands, allowing data collection from natural human hand demonstrations across different scenarios. It ensures consistency in the raw data format, enabling evaluation of grasping for both human and robotic hands. Secondly, we establish a unified representation of multi-modal inputs based on graph structures with polar coordinates. We explicitly integrate the morphological differences into the designed representation, enhancing the compatibility across different demonstrators and robotic hands. Furthermore, we introduce the Tactile-Kinesthetic Spatio-Temporal Graph Networks (TK-STGN), which leverage multidimensional subgraph convolutions and attention-based LSTM layers to extract spatio-temporal features from graph inputs to predict node-based states for each hand joint. These predictions are then mapped to final commands through a force-position hybrid mapping.
A Pseudo Global Fusion Paradigm-Based Cross-View Network for LiDAR-Based Place Recognition
Aug 12, 2025LiDAR-based Place Recognition (LPR) remains a critical task in Embodied Artificial Intelligence (AI) and Autonomous Driving, primarily addressing localization challenges in GPS-denied environments and supporting loop closure detection. Existing approaches reduce place recognition to a Euclidean distance-based metric learning task, neglecting the feature space's intrinsic structures and intra-class variances. Such Euclidean-centric formulation inherently limits the model's capacity to capture nonlinear data distributions, leading to suboptimal performance in complex environments and temporal-varying scenarios. To address these challenges, we propose a novel cross-view network based on an innovative fusion paradigm. Our framework introduces a pseudo-global information guidance mechanism that coordinates multi-modal branches to perform feature learning within a unified semantic space. Concurrently, we propose a Manifold Adaptation and Pairwise Variance-Locality Learning Metric that constructs a Symmetric Positive Definite (SPD) matrix to compute Mahalanobis distance, superseding traditional Euclidean distance metrics. This geometric formulation enables the model to accurately characterize intrinsic data distributions and capture complex inter-class dependencies within the feature space. Experimental results demonstrate that the proposed algorithm achieves competitive performance, particularly excelling in complex environmental conditions.
Novel Diffusion Models for Multimodal 3D Hand Trajectory Prediction
Apr 10, 2025Predicting hand motion is critical for understanding human intentions and bridging the action space between human movements and robot manipulations. Existing hand trajectory prediction (HTP) methods forecast the future hand waypoints in 3D space conditioned on past egocentric observations. However, such models are only designed to accommodate 2D egocentric video inputs. There is a lack of awareness of multimodal environmental information from both 2D and 3D observations, hindering the further improvement of 3D HTP performance. In addition, these models overlook the synergy between hand movements and headset camera egomotion, either predicting hand trajectories in isolation or encoding egomotion only from past frames. To address these limitations, we propose novel diffusion models (MMTwin) for multimodal 3D hand trajectory prediction. MMTwin is designed to absorb multimodal information as input encompassing 2D RGB images, 3D point clouds, past hand waypoints, and text prompt. Besides, two latent diffusion models, the egomotion diffusion and the HTP diffusion as twins, are integrated into MMTwin to predict camera egomotion and future hand trajectories concurrently. We propose a novel hybrid Mamba-Transformer module as the denoising model of the HTP diffusion to better fuse multimodal features. The experimental results on three publicly available datasets and our self-recorded data demonstrate that our proposed MMTwin can predict plausible future 3D hand trajectories compared to the state-of-the-art baselines, and generalizes well to unseen environments. The code and pretrained models will be released at https://github.com/IRMVLab/MMTwin.
UGNA-VPR: A Novel Training Paradigm for Visual Place Recognition Based on Uncertainty-Guided NeRF Augmentation
Mar 27, 2025
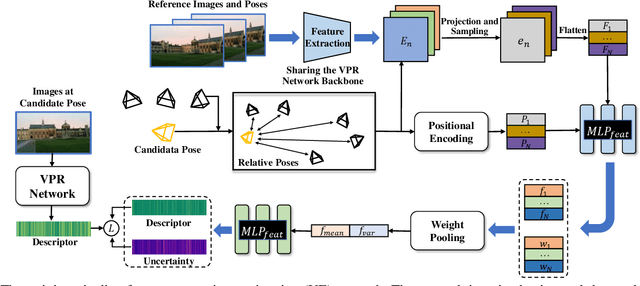
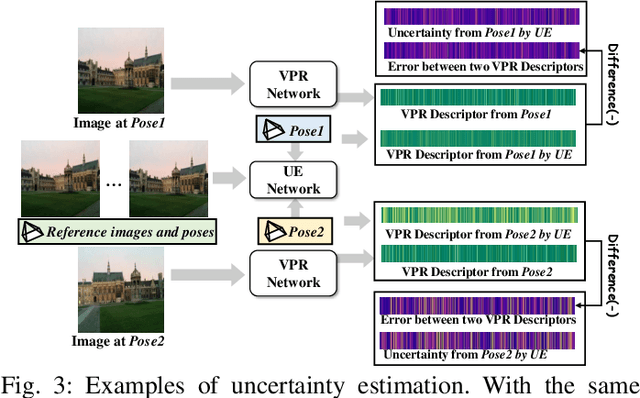
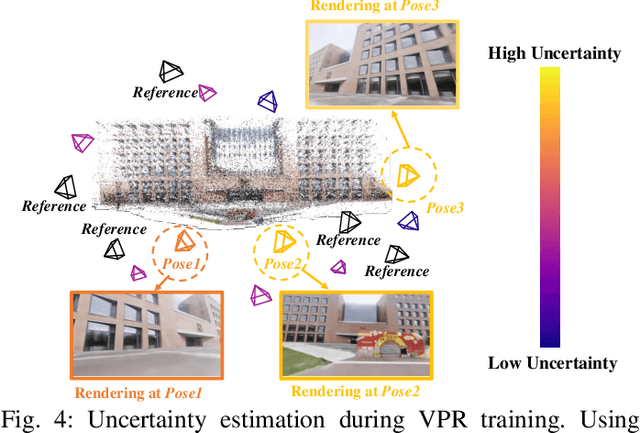
Visual place recognition (VPR) is crucial for robots to identify previously visited locations, playing an important role in autonomous navigation in both indoor and outdoor environments. However, most existing VPR datasets are limited to single-viewpoint scenarios, leading to reduced recognition accuracy, particularly in multi-directional driving or feature-sparse scenes. Moreover, obtaining additional data to mitigate these limitations is often expensive. This paper introduces a novel training paradigm to improve the performance of existing VPR networks by enhancing multi-view diversity within current datasets through uncertainty estimation and NeRF-based data augmentation. Specifically, we initially train NeRF using the existing VPR dataset. Then, our devised self-supervised uncertainty estimation network identifies places with high uncertainty. The poses of these uncertain places are input into NeRF to generate new synthetic observations for further training of VPR networks. Additionally, we propose an improved storage method for efficient organization of augmented and original training data. We conducted extensive experiments on three datasets and tested three different VPR backbone networks. The results demonstrate that our proposed training paradigm significantly improves VPR performance by fully utilizing existing data, outperforming other training approaches. We further validated the effectiveness of our approach on self-recorded indoor and outdoor datasets, consistently demonstrating superior results. Our dataset and code have been released at \href{https://github.com/nubot-nudt/UGNA-VPR}{https://github.com/nubot-nudt/UGNA-VPR}.
Efficient Multimodal 3D Object Detector via Instance-Level Contrastive Distillation
Mar 17, 2025Multimodal 3D object detectors leverage the strengths of both geometry-aware LiDAR point clouds and semantically rich RGB images to enhance detection performance. However, the inherent heterogeneity between these modalities, including unbalanced convergence and modal misalignment, poses significant challenges. Meanwhile, the large size of the detection-oriented feature also constrains existing fusion strategies to capture long-range dependencies for the 3D detection tasks. In this work, we introduce a fast yet effective multimodal 3D object detector, incorporating our proposed Instance-level Contrastive Distillation (ICD) framework and Cross Linear Attention Fusion Module (CLFM). ICD aligns instance-level image features with LiDAR representations through object-aware contrastive distillation, ensuring fine-grained cross-modal consistency. Meanwhile, CLFM presents an efficient and scalable fusion strategy that enhances cross-modal global interactions within sizable multimodal BEV features. Extensive experiments on the KITTI and nuScenes 3D object detection benchmarks demonstrate the effectiveness of our methods. Notably, our 3D object detector outperforms state-of-the-art (SOTA) methods while achieving superior efficiency. The implementation of our method has been released as open-source at: https://github.com/nubot-nudt/ICD-Fusion.