 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrashSight: A Phase-Aware, Infrastructure-Centric Video Benchmark for Traffic Crash Scene Understanding and Reasoning
Apr 09, 2026Cooperative autonomous driving requires traffic scene understanding from both vehicle and infrastructure perspectives. While vision-language models (VLMs) show strong general reasoning capabilities, their performance in safety-critical traffic scenarios remains insufficiently evaluated due to the ego-vehicle focus of existing benchmarks. To bridge this gap, we present \textbf{CrashSight}, a large-scale vision-language benchmark for roadway crash understanding using real-world roadside camera data. The dataset comprises 250 crash videos, annotated with 13K multiple-choice question-answer pairs organized under a two-tier taxonomy. Tier 1 evaluates the visual grounding of scene context and involved parties, while Tier 2 probes higher-level reasoning, including crash mechanics, causal attribution, temporal progression, and post-crash outcomes. We benchmark 8 state-of-the-art VLMs and show that, despite strong scene description capabilities, current models struggle with temporal and causal reasoning in safety-critical scenarios. We provide a detailed analysis of failure scenarios and discuss directions for improving VLM crash understanding. The benchmark provides a standardized evaluation framework for infrastructure-assisted perception in cooperative autonomous driving. The CrashSight benchmark, including the full dataset and code, is accessible at https://mcgrche.github.io/crashsight.
Uni-Hand: Universal Hand Motion Forecasting in Egocentric Views
Nov 18, 2025Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.
EgoLoc: A Generalizable Solution for Temporal Interaction Localization in Egocentric Videos
Aug 17, 2025Analyzing hand-object interaction in egocentric vision facilitates VR/AR applications and human-robot policy transfer. Existing research has mostly focused on modeling the behavior paradigm of interactive actions (i.e., ``how to interact''). However, the more challenging and fine-grained problem of capturing the critical moments of contact and separation between the hand and the target object (i.e., ``when to interact'') is still underexplored, which is crucial for immersive interactive experiences in mixed reality and robotic motion planning. Therefore, we formulate this problem as temporal interaction localization (TIL). Some recent works extract semantic masks as TIL references, but suffer from inaccurate object grounding and cluttered scenarios. Although current temporal action localization (TAL) methods perform well in detecting verb-noun action segments, they rely on category annotations during training and exhibit limited precision in localizing hand-object contact/separation moments. To address these issues, we propose a novel zero-shot approach dubbed EgoLoc to localize hand-object contact and separation timestamps in egocentric videos. EgoLoc introduces hand-dynamics-guided sampling to generate high-quality visual prompts. It exploits the vision-language model to identify contact/separation attributes, localize specific timestamps, and provide closed-loop feedback for further refinement. EgoLoc eliminates the need for object masks and verb-noun taxonomies, leading to generalizable zero-shot implementation. Comprehensive experiments on the public dataset and our novel benchmarks demonstrate that EgoLoc achieves plausible TIL for egocentric videos. It is also validated to effectively facilitate multiple downstream applications in egocentric vision and robotic manipulation tasks. Code and relevant data will be released at https://github.com/IRMVLab/EgoLoc.
Novel Diffusion Models for Multimodal 3D Hand Trajectory Prediction
Apr 10, 2025Predicting hand motion is critical for understanding human intentions and bridging the action space between human movements and robot manipulations. Existing hand trajectory prediction (HTP) methods forecast the future hand waypoints in 3D space conditioned on past egocentric observations. However, such models are only designed to accommodate 2D egocentric video inputs. There is a lack of awareness of multimodal environmental information from both 2D and 3D observations, hindering the further improvement of 3D HTP performance. In addition, these models overlook the synergy between hand movements and headset camera egomotion, either predicting hand trajectories in isolation or encoding egomotion only from past frames. To address these limitations, we propose novel diffusion models (MMTwin) for multimodal 3D hand trajectory prediction. MMTwin is designed to absorb multimodal information as input encompassing 2D RGB images, 3D point clouds, past hand waypoints, and text prompt. Besides, two latent diffusion models, the egomotion diffusion and the HTP diffusion as twins, are integrated into MMTwin to predict camera egomotion and future hand trajectories concurrently. We propose a novel hybrid Mamba-Transformer module as the denoising model of the HTP diffusion to better fuse multimodal features. The experimental results on three publicly available datasets and our self-recorded data demonstrate that our proposed MMTwin can predict plausible future 3D hand trajectories compared to the state-of-the-art baselines, and generalizes well to unseen environments. The code and pretrained models will be released at https://github.com/IRMVLab/MMTwin.
EADReg: Probabilistic Correspondence Generation with Efficient Autoregressive Diffusion Model for Outdoor Point Cloud Registration
Nov 22, 2024



Diffusion models have shown the great potential in the point cloud registration (PCR) task, especially for enhancing the robustness to challenging cases. However, existing diffusion-based PCR methods primarily focus on instance-level scenarios and struggle with outdoor LiDAR points, where the sparsity, irregularity, and huge point scale inherent in LiDAR points pose challenges to establishing dense global point-to-point correspondences. To address this issue, we propose a novel framework named EADReg for efficient and robust registration of LiDAR point clouds based on autoregressive diffusion models. EADReg follows a coarse-to-fine registration paradigm. In the coarse stage, we employ a Bi-directional Gaussian Mixture Model (BGMM) to reject outlier points and obtain purified point cloud pairs. BGMM establishes correspondences between the Gaussian Mixture Models (GMMs) from the source and target frames, enabling reliable coarse registration based on filtered features and geometric information. In the fine stage, we treat diffusion-based PCR as an autoregressive process to generate robust point correspondences, which are then iteratively refined on upper layers. Despite common criticisms of diffusion-based methods regarding inference speed, EADReg achieves runtime comparable to convolutional-based methods. Extensive experiments on the KITTI and NuScenes benchmark datasets highlight the state-of-the-art performance of our proposed method. Codes will be released upon publication.
Spatiotemporal Decoupling for Efficient Vision-Based Occupancy Forecasting
Nov 21, 2024



The task of occupancy forecasting (OCF) involves utilizing past and present perception data to predict future occupancy states of autonomous vehicle surrounding environments, which is critical for downstream tasks such as obstacle avoidance and path planning. Existing 3D OCF approaches struggle to predict plausible spatial details for movable objects and suffer from slow inference speeds due to neglecting the bias and uneven distribution of changing occupancy states in both space and time. In this paper, we propose a novel spatiotemporal decoupling vision-based paradigm to explicitly tackle the bias and achieve both effective and efficient 3D OCF. To tackle spatial bias in empty areas, we introduce a novel spatial representation that decouples the conventional dense 3D format into 2D bird's-eye view (BEV) occupancy with corresponding height values, enabling 3D OCF derived only from 2D predictions thus enhancing efficiency. To reduce temporal bias on static voxels, we design temporal decoupling to improve end-to-end OCF by temporally associating instances via predicted flows. We develop an efficient multi-head network EfficientOCF to achieve 3D OCF with our devised spatiotemporally decoupled representation. A new metric, conditional IoU (C-IoU), is also introduced to provide a robust 3D OCF performance assessment, especially in datasets with missing or incomplete annotations. The experimental results demonstrate that EfficientOCF surpasses existing baseline methods on accuracy and efficiency, achieving state-of-the-art performance with a fast inference time of 82.33ms with a single GPU. Our code will be released as open source.
MADiff: Motion-Aware Mamba Diffusion Models for Hand Trajectory Prediction on Egocentric Videos
Sep 04, 2024



Understanding human intentions and actions through egocentric videos is important on the path to embodied artificial intelligence. As a branch of egocentric vision techniques, hand trajectory prediction plays a vital role in comprehending human motion patterns, benefiting downstream tasks in extended reality and robot manipulation. However, capturing high-level human intentions consistent with reasonable temporal causality is challenging when only egocentric videos are available. This difficulty is exacerbated under camera egomotion interference and the absence of affordance labels to explicitly guide the optimization of hand waypoint distribution. In this work, we propose a novel hand trajectory prediction method dubbed MADiff, which forecasts future hand waypoints with diffusion models. The devised denoising operation in the latent space is achieved by our proposed motion-aware Mamba, where the camera wearer's egomotion is integrated to achieve motion-driven selective scan (MDSS). To discern the relationship between hands and scenarios without explicit affordance supervision, we leverage a foundation model that fuses visual and language features to capture high-level semantics from video clips. Comprehensive experiments conducted on five public datasets with the existing and our proposed new evaluation metrics demonstrate that MADiff predicts comparably reasonable hand trajectories compared to the state-of-the-art baselines, and achieves real-time performance. We will release our code and pretrained models of MADiff at the project page: https://irmvlab.github.io/madiff.github.io.
Diff-IP2D: Diffusion-Based Hand-Object Interaction Prediction on Egocentric Videos
May 07, 2024



Understanding how humans would behave during hand-object interaction is vital for applications in service robot manipulation and extended reality. To achieve this, some recent works have been proposed to simultaneously predict hand trajectories and object affordances on human egocentric videos. They are regarded as the representation of future hand-object interactions, indicating potential human motion and motivation. However, the existing approaches mostly adopt the autoregressive paradigm for unidirectional prediction, which lacks mutual constraints within the holistic future sequence, and accumulates errors along the time axis. Meanwhile, these works basically overlook the effect of camera egomotion on first-person view predictions. To address these limitations, we propose a novel diffusion-based interaction prediction method, namely Diff-IP2D, to forecast future hand trajectories and object affordances concurrently in an iterative non-autoregressive manner. We transform the sequential 2D images into latent feature space and design a denoising diffusion model to predict future latent interaction features conditioned on past ones. Motion features are further integrated into the conditional denoising process to enable Diff-IP2D aware of the camera wearer's dynamics for more accurate interaction prediction. The experimental results show that our method significantly outperforms the state-of-the-art baselines on both the off-the-shelf metrics and our proposed new evaluation protocol. This highlights the efficacy of leveraging a generative paradigm for 2D hand-object interaction prediction. The code of Diff-IP2D will be released at https://github.com/IRMVLab/Diff-IP2D.
Explicit Interaction for Fusion-Based Place Recognition
Feb 27, 2024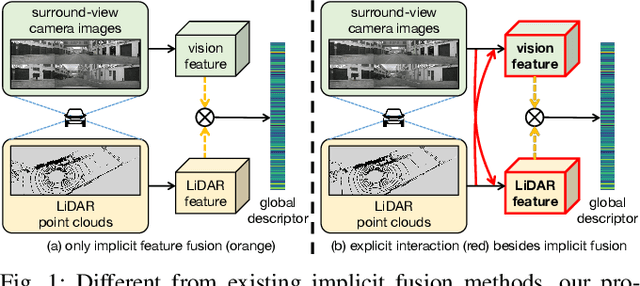
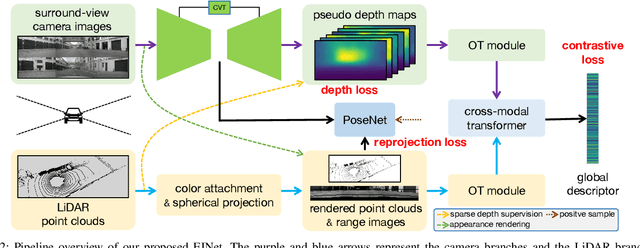

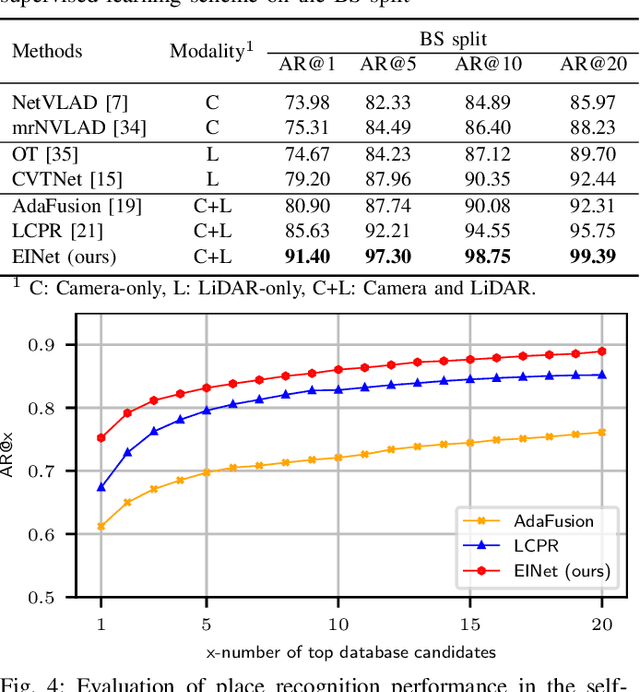
Fusion-based place recognition is an emerging technique jointly utilizing multi-modal perception data, to recognize previously visited places in GPS-denied scenarios for robots and autonomous vehicles. Recent fusion-based place recognition methods combine multi-modal features in implicit manners. While achieving remarkable results, they do not explicitly consider what the individual modality affords in the fusion system. Therefore, the benefit of multi-modal feature fusion may not be fully explored. In this paper, we propose a novel fusion-based network, dubbed EINet, to achieve explicit interaction of the two modalities. EINet uses LiDAR ranges to supervise more robust vision features for long time spans, and simultaneously uses camera RGB data to improve the discrimination of LiDAR point clouds. In addition, we develop a new benchmark for the place recognition task based on the nuScenes dataset. To establish this benchmark for future research with comprehensive comparisons, we introduce both supervised and self-supervised training schemes alongside evaluation protocols. We conduct extensive experiments on the proposed benchmark, and the experimental results show that our EINet exhibits better recognition performance as well as solid generalization ability compared to the state-of-the-art fusion-based place recognition approaches. Our open-source code and benchmark are released at: https://github.com/BIT-XJY/EINet.
PC-NeRF: Parent-Child Neural Radiance Fields Using Sparse LiDAR Frames in Autonomous Driving Environments
Feb 14, 2024



Large-scale 3D scene reconstruction and novel view synthesis are vital for autonomous vehicles, especially utilizing temporally sparse LiDAR frames. However, conventional explicit representations remain a significant bottleneck towards representing the reconstructed and synthetic scenes at unlimited resolution. Although the recently developed neural radiance fields (NeRF) have shown compelling results in implicit representations, the problem of large-scale 3D scene reconstruction and novel view synthesis using sparse LiDAR frames remains unexplored. To bridge this gap, we propose a 3D scene reconstruction and novel view synthesis framework called parent-child neural radiance field (PC-NeRF). Based on its two modules, parent NeRF and child NeRF, the framework implements hierarchical spatial partitioning and multi-level scene representation, including scene, segment, and point levels. The multi-level scene representation enhances the efficient utilization of sparse LiDAR point cloud data and enables the rapid acquisition of an approximate volumetric scene representation. With extensive experiments, PC-NeRF is proven to achieve high-precision novel LiDAR view synthesis and 3D reconstruction in large-scale scenes. Moreover, PC-NeRF can effectively handle situations with sparse LiDAR frames and demonstrate high deployment efficiency with limited training epochs. Our approach implementation and the pre-trained models are available at https://github.com/biter0088/pc-nerf.