 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMPR: A Unified Framework for Multimodal Place Recognition with Heterogeneous Sensor Configurations
Dec 23, 2025Place recognition is a critical component of autonomous vehicles and robotics, enabling global localization in GPS-denied environments. Recent advances have spurred significant interest in multimodal place recognition (MPR), which leverages complementary strengths of multiple modalities. Despite its potential, most existing MPR methods still face three key challenges: (1) dynamically adapting to various modality inputs within a unified framework, (2) maintaining robustness with missing or degraded modalities, and (3) generalizing across diverse sensor configurations and setups. In this paper, we propose UniMPR, a unified framework for multimodal place recognition. Using only one trained model, it can seamlessly adapt to any combination of common perceptual modalities (e.g., camera, LiDAR, radar). To tackle the data heterogeneity, we unify all inputs within a polar BEV feature space. Subsequently, the polar BEVs are fed into a multi-branch network to exploit discriminative intra-model and inter-modal features from any modality combinations. To fully exploit the network's generalization capability and robustness, we construct a large-scale training set from multiple datasets and introduce an adaptive label assignment strategy for extensive pre-training. Experiments on seven datasets demonstrate that UniMPR achieves state-of-the-art performance under varying sensor configurations, modality combinations, and environmental conditions. Our code will be released at https://github.com/QiZS-BIT/UniMPR.
LRFusionPR: A Polar BEV-Based LiDAR-Radar Fusion Network for Place Recognition
Apr 27, 2025In autonomous driving, place recognition is critical for global localization in GPS-denied environments. LiDAR and radar-based place recognition methods have garnered increasing attention, as LiDAR provides precise ranging, whereas radar excels in adverse weather resilience. However, effectively leveraging LiDAR-radar fusion for place recognition remains challenging. The noisy and sparse nature of radar data limits its potential to further improve recognition accuracy. In addition, heterogeneous radar configurations complicate the development of unified cross-modality fusion frameworks. In this paper, we propose LRFusionPR, which improves recognition accuracy and robustness by fusing LiDAR with either single-chip or scanning radar. Technically, a dual-branch network is proposed to fuse different modalities within the unified polar coordinate bird's eye view (BEV) representation. In the fusion branch, cross-attention is utilized to perform cross-modality feature interactions. The knowledge from the fusion branch is simultaneously transferred to the distillation branch, which takes radar as its only input to further improve the robustness. Ultimately, the descriptors from both branches are concatenated, producing the multimodal global descriptor for place retrieval. Extensive evaluations on multiple datasets demonstrate that our LRFusionPR achieves accurate place recognition, while maintaining robustness under varying weather conditions. Our open-source code will be released at https://github.com/QiZS-BIT/LRFusionPR.
SegLocNet: Multimodal Localization Network for Autonomous Driving via Bird's-Eye-View Segmentation
Feb 28, 2025Robust and accurate localization is critical for autonomous driving. Traditional GNSS-based localization methods suffer from signal occlusion and multipath effects in urban environments. Meanwhile, methods relying on high-definition (HD) maps are constrained by the high costs associated with the construction and maintenance of HD maps. Standard-definition (SD) maps-based methods, on the other hand, often exhibit unsatisfactory performance or poor generalization ability due to overfitting. To address these challenges, we propose SegLocNet, a multimodal GNSS-free localization network that achieves precise localization using bird's-eye-view (BEV) semantic segmentation. SegLocNet employs a BEV segmentation network to generate semantic maps from multiple sensor inputs, followed by an exhaustive matching process to estimate the vehicle's ego pose. This approach avoids the limitations of regression-based pose estimation and maintains high interpretability and generalization. By introducing a unified map representation, our method can be applied to both HD and SD maps without any modifications to the network architecture, thereby balancing localization accuracy and area coverage. Extensive experiments on the nuScenes and Argoverse datasets demonstrate that our method outperforms the current state-of-the-art methods, and that our method can accurately estimate the ego pose in urban environments without relying on GNSS, while maintaining strong generalization ability. Our code and pre-trained model will be released publicly.
PC-NeRF: Parent-Child Neural Radiance Fields Using Sparse LiDAR Frames in Autonomous Driving Environments
Feb 14, 2024



Large-scale 3D scene reconstruction and novel view synthesis are vital for autonomous vehicles, especially utilizing temporally sparse LiDAR frames. However, conventional explicit representations remain a significant bottleneck towards representing the reconstructed and synthetic scenes at unlimited resolution. Although the recently developed neural radiance fields (NeRF) have shown compelling results in implicit representations, the problem of large-scale 3D scene reconstruction and novel view synthesis using sparse LiDAR frames remains unexplored. To bridge this gap, we propose a 3D scene reconstruction and novel view synthesis framework called parent-child neural radiance field (PC-NeRF). Based on its two modules, parent NeRF and child NeRF, the framework implements hierarchical spatial partitioning and multi-level scene representation, including scene, segment, and point levels. The multi-level scene representation enhances the efficient utilization of sparse LiDAR point cloud data and enables the rapid acquisition of an approximate volumetric scene representation. With extensive experiments, PC-NeRF is proven to achieve high-precision novel LiDAR view synthesis and 3D reconstruction in large-scale scenes. Moreover, PC-NeRF can effectively handle situations with sparse LiDAR frames and demonstrate high deployment efficiency with limited training epochs. Our approach implementation and the pre-trained models are available at https://github.com/biter0088/pc-nerf.
LCPR: A Multi-Scale Attention-Based LiDAR-Camera Fusion Network for Place Recognition
Nov 06, 2023Place recognition is one of the most crucial modules for autonomous vehicles to identify places that were previously visited in GPS-invalid environments. Sensor fusion is considered an effective method to overcome the weaknesses of individual sensors. In recent years, multimodal place recognition fusing information from multiple sensors has gathered increasing attention. However, most existing multimodal place recognition methods only use limited field-of-view camera images, which leads to an imbalance between features from different modalities and limits the effectiveness of sensor fusion. In this paper, we present a novel neural network named LCPR for robust multimodal place recognition, which fuses LiDAR point clouds with multi-view RGB images to generate discriminative and yaw-rotation invariant representations of the environment. A multi-scale attention-based fusion module is proposed to fully exploit the panoramic views from different modalities of the environment and their correlations. We evaluate our method on the nuScenes dataset, and the experimental results show that our method can effectively utilize multi-view camera and LiDAR data to improve the place recognition performance while maintaining strong robustness to viewpoint changes. Our open-source code and pre-trained models are available at https://github.com/ZhouZijie77/LCPR .
PC-NeRF: Parent-Child Neural Radiance Fields under Partial Sensor Data Loss in Autonomous Driving Environments
Oct 02, 2023



Reconstructing large-scale 3D scenes is essential for autonomous vehicles, especially when partial sensor data is lost. Although the recently developed neural radiance fields (NeRF) have shown compelling results in implicit representations, the large-scale 3D scene reconstruction using partially lost LiDAR point cloud data still needs to be explored. To bridge this gap, we propose a novel 3D scene reconstruction framework called parent-child neural radiance field (PC-NeRF). The framework comprises two modules, the parent NeRF and the child NeRF, to simultaneously optimize scene-level, segment-level, and point-level scene representations. Sensor data can be utilized more efficiently by leveraging the segment-level representation capabilities of child NeRFs, and an approximate volumetric representation of the scene can be quickly obtained even with limited observations. With extensive experiments, our proposed PC-NeRF is proven to achieve high-precision 3D reconstruction in large-scale scenes. Moreover, PC-NeRF can effectively tackle situations where partial sensor data is lost and has high deployment efficiency with limited training time. Our approach implementation and the pre-trained models will be available at https://github.com/biter0088/pc-nerf.
PCPNet: An Efficient and Semantic-Enhanced Transformer Network for Point Cloud Prediction
Apr 16, 2023



The ability to predict future structure features of environments based on past perception information is extremely needed by autonomous vehicles, which helps to make the following decision-making and path planning more reasonable. Recently, point cloud prediction (PCP) is utilized to predict and describe future environmental structures by the point cloud form. In this letter, we propose a novel efficient Transformer-based network to predict the future LiDAR point clouds exploiting the past point cloud sequences. We also design a semantic auxiliary training strategy to make the predicted LiDAR point cloud sequence semantically similar to the ground truth and thus improves the significance of the deployment for more tasks in real-vehicle applications. Our approach is completely self-supervised, which means it does not require any manual labeling and has a solid generalization ability toward different environments. The experimental results show that our method outperforms the state-of-the-art PCP methods on the prediction results and semantic similarity, and has a good real-time performance. Our open-source code and pre-trained models are available at https://github.com/Blurryface0814/PCPNet.
CVTNet: A Cross-View Transformer Network for Place Recognition Using LiDAR Data
Feb 03, 2023LiDAR-based place recognition (LPR) is one of the most crucial components of autonomous vehicles to identify previously visited places in GPS-denied environments. Most existing LPR methods use mundane representations of the input point cloud without considering different views, which may not fully exploit the information from LiDAR sensors. In this paper, we propose a cross-view transformer-based network, dubbed CVTNet, to fuse the range image views (RIVs) and bird's eye views (BEVs) generated from the LiDAR data. It extracts correlations within the views themselves using intra-transformers and between the two different views using inter-transformers. Based on that, our proposed CVTNet generates a yaw-angle-invariant global descriptor for each laser scan end-to-end online and retrieves previously seen places by descriptor matching between the current query scan and the pre-built database. We evaluate our approach on three datasets collected with different sensor setups and environmental conditions. The experimental results show that our method outperforms the state-of-the-art LPR methods with strong robustness to viewpoint changes and long-time spans. Furthermore, our approach has a good real-time performance that can run faster than the typical LiDAR frame rate. The implementation of our method is released as open source at: https://github.com/BIT-MJY/CVTNet.
SeqOT: A Spatial-Temporal Transformer Network for Place Recognition Using Sequential LiDAR Data
Sep 16, 2022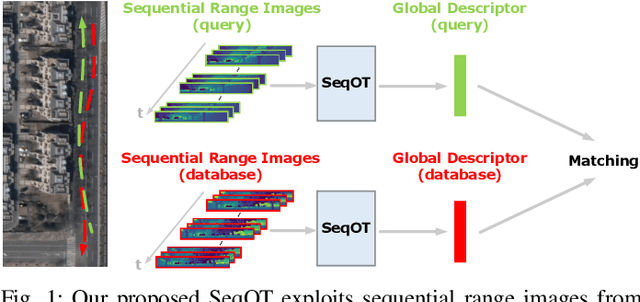

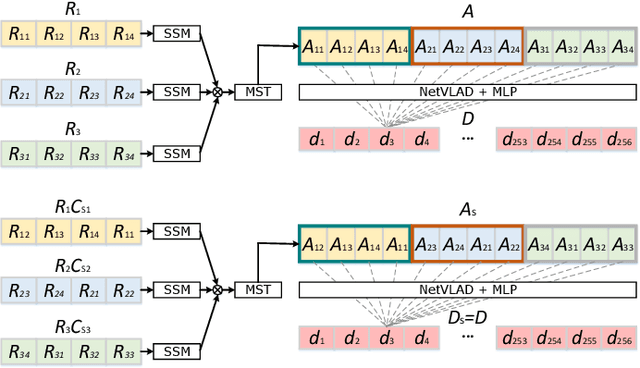

Place recognition is an important component for autonomous vehicles to achieve loop closing or global localization. In this paper, we tackle the problem of place recognition based on sequential 3D LiDAR scans obtained by an onboard LiDAR sensor. We propose a transformer-based network named SeqOT to exploit the temporal and spatial information provided by sequential range images generated from the LiDAR data. It uses multi-scale transformers to generate a global descriptor for each sequence of LiDAR range images in an end-to-end fashion. During online operation, our SeqOT finds similar places by matching such descriptors between the current query sequence and those stored in the map. We evaluate our approach on four datasets collected with different types of LiDAR sensors in different environments. The experimental results show that our method outperforms the state-of-the-art LiDAR-based place recognition methods and generalizes well across different environments. Furthermore, our method operates online faster than the frame rate of the sensor. The implementation of our method is released as open source at: https://github.com/BIT-MJY/SeqOT.