 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Compression-Precision Paradox: A Hybrid Architecture for Clinical EEG Report Generation with Guaranteed Measurement Accuracy
Feb 11, 2026Automated EEG monitoring requires clinician-level precision for seizure detection and reporting. Clinical EEG recordings exceed LLM context windows, requiring extreme compression (400:1+ ratios) that destroys fine-grained temporal precision. A 0.5 Hz error distinguishes absence epilepsy from Lennox-Gastaut syndrome. LLMs lack inherent time-series comprehension and rely on statistical associations from compressed representations. This dual limitation causes systems to hallucinate clinically incorrect measurement values. We separate measurement extraction from text generation. Our hybrid architecture computes exact clinical values via signal processing before compression, employs a cross-modal bridge for EEG-to-language translation, and uses parameter-efficient fine-tuning with constrained decoding around frozen slots. Multirate sampling maintains long-range context while preserving event-level precision. Evaluation on TUH and CHB-MIT datasets achieves 60% fewer false alarms, 50% faster detection, and sub-clinical measurement precision. This is the first system guaranteeing clinical measurement accuracy in automated EEG reports.
UltraEval-Audio: A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
Jan 04, 2026The development of audio foundation models has accelerated rapidly since the emergence of GPT-4o. However, the lack of comprehensive evaluation has become a critical bottleneck for further progress in the field, particularly in audio generation. Current audio evaluation faces three major challenges: (1) audio evaluation lacks a unified framework, with datasets and code scattered across various sources, hindering fair and efficient cross-model comparison;(2) audio codecs, as a key component of audio foundation models, lack a widely accepted and holistic evaluation methodology; (3) existing speech benchmarks are heavily reliant on English, making it challenging to objectively assess models' performance on Chinese. To address the first issue, we introduce UltraEval-Audio, a unified evaluation framework for audio foundation models, specifically designed for both audio understanding and generation tasks. UltraEval-Audio features a modular architecture, supporting 10 languages and 14 core task categories, while seamlessly integrating 24 mainstream models and 36 authoritative benchmarks. To enhance research efficiency, the framework provides a one-command evaluation feature, accompanied by real-time public leaderboards. For the second challenge, UltraEval-Audio adopts a novel comprehensive evaluation scheme for audio codecs, evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality. To address the third issue, we propose two new Chinese benchmarks, SpeechCMMLU and SpeechHSK, designed to assess Chinese knowledge proficiency and language fluency. We wish that UltraEval-Audio will provide both academia and industry with a transparent, efficient, and fair platform for comparison of audio models. Our code, benchmarks, and leaderboards are available at https://github.com/OpenBMB/UltraEval-Audio.
ArtiWorld: LLM-Driven Articulation of 3D Objects in Scenes
Nov 18, 2025Building interactive simulators and scalable robot-learning environments requires a large number of articulated assets. However, most existing 3D assets in simulation are rigid, and manually converting them into articulated objects is extremely labor- and cost-intensive. This raises a natural question: can we automatically identify articulable objects in a scene and convert them into articulated assets directly? In this paper, we present ArtiWorld, a scene-aware pipeline that localizes candidate articulable objects from textual scene descriptions and reconstructs executable URDF models that preserve the original geometry. At the core of this pipeline is Arti4URDF, which leverages 3D point cloud, prior knowledge of a large language model (LLM), and a URDF-oriented prompt design to rapidly convert rigid objects into interactive URDF-based articulated objects while maintaining their 3D shape. We evaluate ArtiWorld at three levels: 3D simulated objects, full 3D simulated scenes, and real-world scan scenes. Across all three settings, our method consistently outperforms existing approaches and achieves state-of-the-art performance, while preserving object geometry and correctly capturing object interactivity to produce usable URDF-based articulated models. This provides a practical path toward building interactive, robot-ready simulation environments directly from existing 3D assets. Code and data will be released.
SemanticForge: Repository-Level Code Generation through Semantic Knowledge Graphs and Constraint Satisfaction
Nov 10, 2025Large language models (LLMs) have transformed software development by enabling automated code generation, yet they frequently suffer from systematic errors that limit practical deployment. We identify two critical failure modes: \textit{logical hallucination} (incorrect control/data-flow reasoning) and \textit{schematic hallucination} (type mismatches, signature violations, and architectural inconsistencies). These errors stem from the absence of explicit, queryable representations of repository-wide semantics. This paper presents \textbf{SemanticForge}, which introduces four fundamental algorithmic advances for semantically-aware code generation: (1) a novel automatic reconciliation algorithm for dual static-dynamic knowledge graphs, unifying compile-time and runtime program semantics; (2) a neural approach that learns to generate structured graph queries from natural language, achieving 73\% precision versus 51\% for traditional retrieval; (3) a novel beam search algorithm with integrated SMT solving, enabling real-time constraint verification during generation rather than post-hoc validation; and (4) an incremental maintenance algorithm that updates knowledge graphs in $O(|ΔR| \cdot \log n)$ time while maintaining semantic equivalence.
MesaTask: Towards Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning
Sep 26, 2025
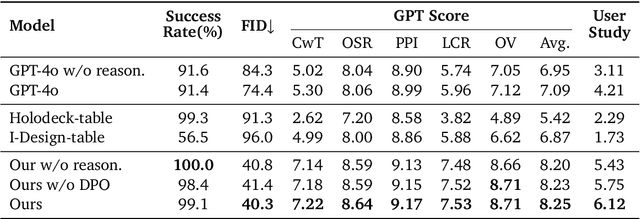
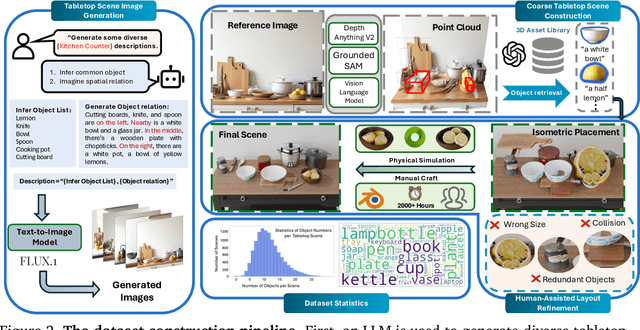
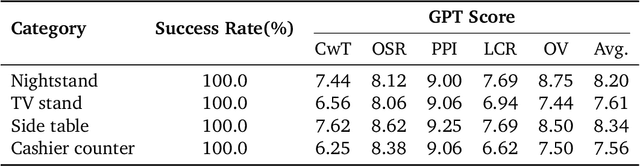
The ability of robots to interpret human instructions and execute manipulation tasks necessitates the availability of task-relevant tabletop scenes for training. However, traditional methods for creating these scenes rely on time-consuming manual layout design or purely randomized layouts, which are limited in terms of plausibility or alignment with the tasks. In this paper, we formulate a novel task, namely task-oriented tabletop scene generation, which poses significant challenges due to the substantial gap between high-level task instructions and the tabletop scenes. To support research on such a challenging task, we introduce MesaTask-10K, a large-scale dataset comprising approximately 10,700 synthetic tabletop scenes with manually crafted layouts that ensure realistic layouts and intricate inter-object relations. To bridge the gap between tasks and scenes, we propose a Spatial Reasoning Chain that decomposes the generation process into object inference, spatial interrelation reasoning, and scene graph construction for the final 3D layout. We present MesaTask, an LLM-based framework that utilizes this reasoning chain and is further enhanced with DPO algorithms to generate physically plausible tabletop scenes that align well with given task descriptions. Exhaustive experiments demonstrate the superior performance of MesaTask compared to baselines in generating task-conforming tabletop scenes with realistic layouts. Project page is at https://mesatask.github.io/
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
RoboReflect: Robotic Reflective Reasoning for Grasping Ambiguous-Condition Objects
Jan 16, 2025



As robotic technology rapidly develops, robots are being employed in an increasing number of fields. However, due to the complexity of deployment environments or the prevalence of ambiguous-condition objects, the practical application of robotics still faces many challenges, leading to frequent errors. Traditional methods and some LLM-based approaches, although improved, still require substantial human intervention and struggle with autonomous error correction in complex scenarios.In this work, we propose RoboReflect, a novel framework leveraging large vision-language models (LVLMs) to enable self-reflection and autonomous error correction in robotic grasping tasks. RoboReflect allows robots to automatically adjust their strategies based on unsuccessful attempts until successful execution is achieved.The corrected strategies are saved in a memory for future task reference.We evaluate RoboReflect through extensive testing on eight common objects prone to ambiguous conditions of three categories.Our results demonstrate that RoboReflect not only outperforms existing grasp pose estimation methods like AnyGrasp and high-level action planning techniques using GPT-4V but also significantly enhances the robot's ability to adapt and correct errors independently. These findings underscore the critical importance of autonomous selfreflection in robotic systems while effectively addressing the challenges posed by ambiguous environments.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024


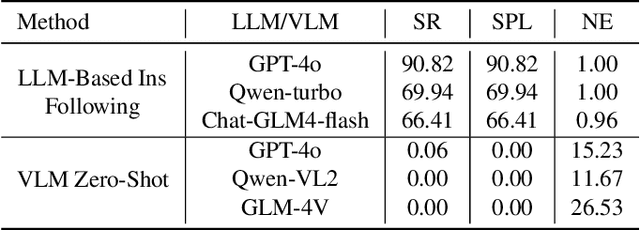
Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model
Jun 06, 2024



Designing 3D indoor layouts is a crucial task with significant applications in virtual reality, interior design, and automated space planning. Existing methods for 3D layout design either rely on diffusion models, which utilize spatial relationship priors, or heavily leverage the inferential capabilities of proprietary Large Language Models (LLMs), which require extensive prompt engineering and in-context exemplars via black-box trials. These methods often face limitations in generalization and dynamic scene editing. In this paper, we introduce LLplace, a novel 3D indoor scene layout designer based on lightweight fine-tuned open-source LLM Llama3. LLplace circumvents the need for spatial relationship priors and in-context exemplars, enabling efficient and credible room layout generation based solely on user inputs specifying the room type and desired objects. We curated a new dialogue dataset based on the 3D-Front dataset, expanding the original data volume and incorporating dialogue data for adding and removing objects. This dataset can enhance the LLM's spatial understanding. Furthermore, through dialogue, LLplace activates the LLM's capability to understand 3D layouts and perform dynamic scene editing, enabling the addition and removal of objects. Our approach demonstrates that LLplace can effectively generate and edit 3D indoor layouts interactively and outperform existing methods in delivering high-quality 3D design solutions. Code and dataset will be released.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.