 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long-Horizon Vision-Language Navigation: Platform, Benchmark and Method
Dec 12, 2024



Existing Vision-Language Navigation (VLN) methods primarily focus on single-stage navigation, limiting their effectiveness in multi-stage and long-horizon tasks within complex and dynamic environments. To address these limitations, we propose a novel VLN task, named Long-Horizon Vision-Language Navigation (LH-VLN), which emphasizes long-term planning and decision consistency across consecutive subtasks. Furthermore, to support LH-VLN, we develop an automated data generation platform NavGen, which constructs datasets with complex task structures and improves data utility through a bidirectional, multi-granularity generation approach. To accurately evaluate complex tasks, we construct the Long-Horizon Planning and Reasoning in VLN (LHPR-VLN) benchmark consisting of 3,260 tasks with an average of 150 task steps, serving as the first dataset specifically designed for the long-horizon vision-language navigation task. Furthermore, we propose Independent Success Rate (ISR), Conditional Success Rate (CSR), and CSR weight by Ground Truth (CGT) metrics, to provide fine-grained assessments of task completion. To improve model adaptability in complex tasks, we propose a novel Multi-Granularity Dynamic Memory (MGDM) module that integrates short-term memory blurring with long-term memory retrieval to enable flexible navigation in dynamic environments. Our platform, benchmark and method supply LH-VLN with a robust data generation pipeline, comprehensive model evaluation dataset, reasonable metrics, and a novel VLN model, establishing a foundational framework for advancing LH-VLN.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024


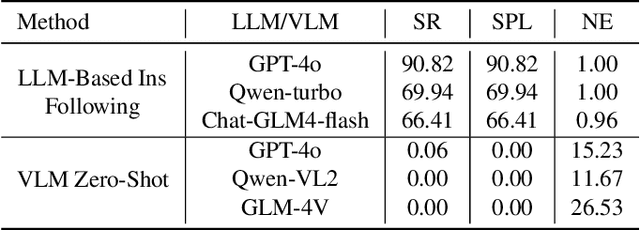
Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI
Jul 09, 2024



Embodied Artificial Intelligence (Embodied AI) is crucial for achieving Artificial General Intelligence (AGI) and serves as a foundation for various applications that bridge cyberspace and the physical world. Recently, the emergence of Multi-modal Large Models (MLMs) and World Models (WMs) have attracted significant attention due to their remarkable perception, interaction, and reasoning capabilities, making them a promising architecture for the brain of embodied agents. However, there is no comprehensive survey for Embodied AI in the era of MLMs. In this survey, we give a comprehensive exploration of the latest advancements in Embodied AI. Our analysis firstly navigates through the forefront of representative works of embodied robots and simulators, to fully understand the research focuses and their limitations. Then, we analyze four main research targets: 1) embodied perception, 2) embodied interaction, 3) embodied agent, and 4) sim-to-real adaptation, covering the state-of-the-art methods, essential paradigms, and comprehensive datasets. Additionally, we explore the complexities of MLMs in virtual and real embodied agents, highlighting their significance in facilitating interactions in dynamic digital and physical environments. Finally, we summarize the challenges and limitations of embodied AI and discuss their potential future directions. We hope this survey will serve as a foundational reference for the research community and inspire continued innovation. The associated project can be found at https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List.
Multimodal Embodied Interactive Agent for Cafe Scene
Feb 01, 2024With the surge in the development of large language models, embodied intelligence has attracted increasing attention. Nevertheless, prior works on embodied intelligence typically encode scene or historical memory in an unimodal manner, either visual or linguistic, which complicates the alignment of the model's action planning with embodied control. To overcome this limitation, we introduce the Multimodal Embodied Interactive Agent (MEIA), capable of translating high-level tasks expressed in natural language into a sequence of executable actions. Specifically, we propose a novel Multimodal Environment Memory (MEM) module, facilitating the integration of embodied control with large models through the visual-language memory of scenes. This capability enables MEIA to generate executable action plans based on diverse requirements and the robot's capabilities. We conduct experiments in a dynamic virtual cafe environment, utilizing multiple large models through zero-shot learning, and carefully design scenarios for various situations. The experimental results showcase the promising performance of our MEIA in various embodied interactive tasks.