 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEAR: Geography-knowledge Enhanced Analog Recognition Framework in Extreme Environments
Mar 19, 2026The Mariana Trench and the Qinghai-Tibet Plateau exhibit significant similarities in geological origins and microbial metabolic functions. Given that deep-sea biological sampling faces prohibitive costs, recognizing structurally homologous terrestrial analogs of the Mariana Trench on the Qinghai-Tibet Plateau is of great significance. Yet, no existing model adequately addresses cross-domain topographic similarity retrieval, either neglecting geographical knowledge or sacrificing computational efficiency. To address these challenges, we present \underline{\textbf{G}}eography-knowledge \underline{\textbf{E}}nhanced \underline{\textbf{A}}nalog \underline{\textbf{R}}ecognition (\textbf{GEAR}) Framework, a three-stage pipeline designed to efficiently retrieve analogs from 2.5 million square kilometers of the Qinghai-Tibet Plateau: (1) Skeleton guided Screening and Clipping: Recognition of candidate valleys and initial screening based on size and linear morphological criteria. (2) Physics aware Filtering: The Topographic Waveform Comparator (TWC) and Morphological Texture Module (MTM) evaluate the waveform and texture and filter out inconsistent candidate valleys. (3) Graph based Fine Recognition: We design a \underline{\textbf{M}}orphology-integrated \underline{\textbf{S}}iamese \underline{\textbf{G}}raph \underline{\textbf{N}}etwork (\textbf{MSG-Net}) based on geomorphological metrics. Correspondingly, we release an expert-annotated topographic similarity dataset targeting tectonic collision zones. Experiments demonstrate the effectiveness of every stage. Besides, MSG-Net achieved an F1-Score 1.38 percentage points higher than the SOTA baseline. Using features extracted by MSG-Net, we discovered a significant correlation with biological data, providing evidence for future biological analysis.
ArtiWorld: LLM-Driven Articulation of 3D Objects in Scenes
Nov 18, 2025Building interactive simulators and scalable robot-learning environments requires a large number of articulated assets. However, most existing 3D assets in simulation are rigid, and manually converting them into articulated objects is extremely labor- and cost-intensive. This raises a natural question: can we automatically identify articulable objects in a scene and convert them into articulated assets directly? In this paper, we present ArtiWorld, a scene-aware pipeline that localizes candidate articulable objects from textual scene descriptions and reconstructs executable URDF models that preserve the original geometry. At the core of this pipeline is Arti4URDF, which leverages 3D point cloud, prior knowledge of a large language model (LLM), and a URDF-oriented prompt design to rapidly convert rigid objects into interactive URDF-based articulated objects while maintaining their 3D shape. We evaluate ArtiWorld at three levels: 3D simulated objects, full 3D simulated scenes, and real-world scan scenes. Across all three settings, our method consistently outperforms existing approaches and achieves state-of-the-art performance, while preserving object geometry and correctly capturing object interactivity to produce usable URDF-based articulated models. This provides a practical path toward building interactive, robot-ready simulation environments directly from existing 3D assets. Code and data will be released.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
Advancing Video Anomaly Detection: A Bi-Directional Hybrid Framework for Enhanced Single- and Multi-Task Approaches
Apr 20, 2025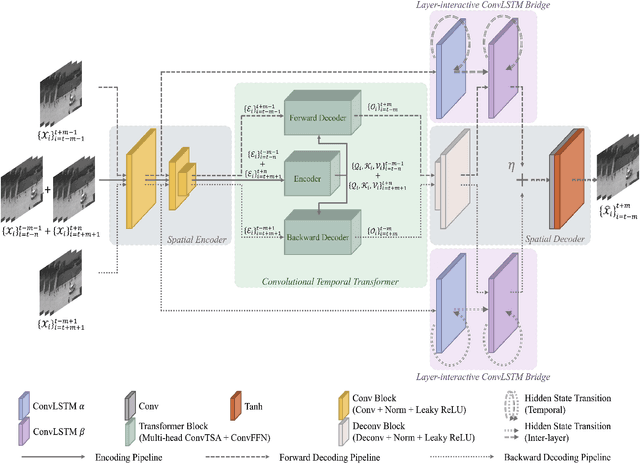
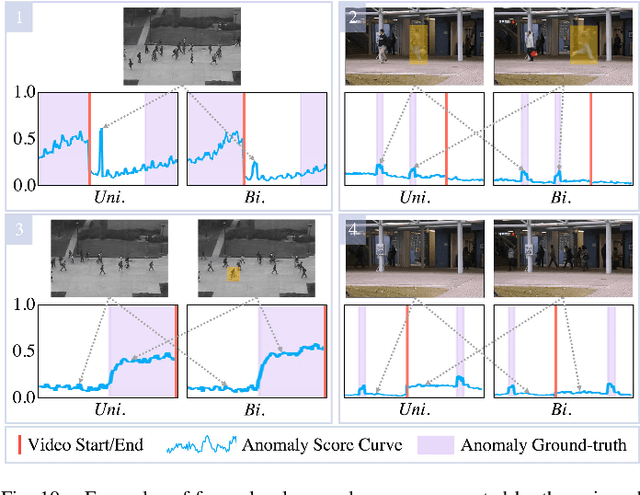
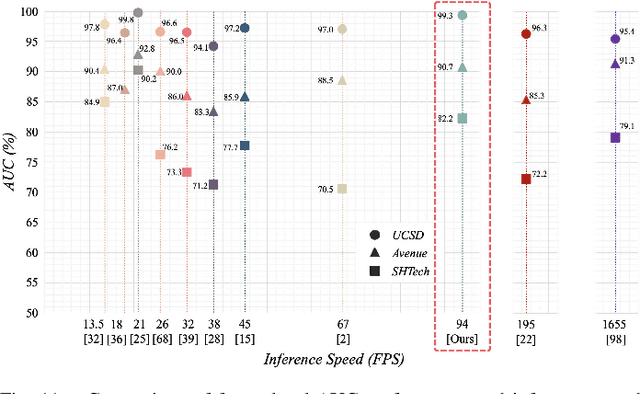
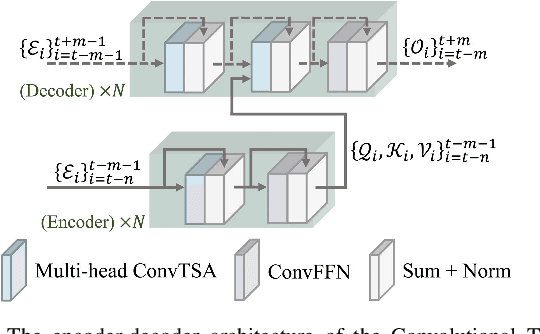
Despite the prevailing transition from single-task to multi-task approaches in video anomaly detection, we observe that many adopt sub-optimal frameworks for individual proxy tasks. Motivated by this, we contend that optimizing single-task frameworks can advance both single- and multi-task approaches. Accordingly, we leverage middle-frame prediction as the primary proxy task, and introduce an effective hybrid framework designed to generate accurate predictions for normal frames and flawed predictions for abnormal frames. This hybrid framework is built upon a bi-directional structure that seamlessly integrates both vision transformers and ConvLSTMs. Specifically, we utilize this bi-directional structure to fully analyze the temporal dimension by predicting frames in both forward and backward directions, significantly boosting the detection stability. Given the transformer's capacity to model long-range contextual dependencies, we develop a convolutional temporal transformer that efficiently associates feature maps from all context frames to generate attention-based predictions for target frames. Furthermore, we devise a layer-interactive ConvLSTM bridge that facilitates the smooth flow of low-level features across layers and time-steps, thereby strengthening predictions with fine details. Anomalies are eventually identified by scrutinizing the discrepancies between target frames and their corresponding predictions. Several experiments conducted on public benchmarks affirm the efficacy of our hybrid framework, whether used as a standalone single-task approach or integrated as a branch in a multi-task approach. These experiments also underscore the advantages of merging vision transformers and ConvLSTMs for video anomaly detection.
* Accepted by IEEE Transactions on Image Processing (TIP)
RefComp: A Reference-guided Unified Framework for Unpaired Point Cloud Completion
Apr 18, 2025The unpaired point cloud completion task aims to complete a partial point cloud by using models trained with no ground truth. Existing unpaired point cloud completion methods are class-aware, i.e., a separate model is needed for each object class. Since they have limited generalization capabilities, these methods perform poorly in real-world scenarios when confronted with a wide range of point clouds of generic 3D objects. In this paper, we propose a novel unpaired point cloud completion framework, namely the Reference-guided Completion (RefComp) framework, which attains strong performance in both the class-aware and class-agnostic training settings. The RefComp framework transforms the unpaired completion problem into a shape translation problem, which is solved in the latent feature space of the partial point clouds. To this end, we introduce the use of partial-complete point cloud pairs, which are retrieved by using the partial point cloud to be completed as a template. These point cloud pairs are used as reference data to guide the completion process. Our RefComp framework uses a reference branch and a target branch with shared parameters for shape fusion and shape translation via a Latent Shape Fusion Module (LSFM) to enhance the structural features along the completion pipeline. Extensive experiments demonstrate that the RefComp framework achieves not only state-of-the-art performance in the class-aware training setting but also competitive results in the class-agnostic training setting on both virtual scans and real-world datasets.
RoboReflect: Robotic Reflective Reasoning for Grasping Ambiguous-Condition Objects
Jan 16, 2025



As robotic technology rapidly develops, robots are being employed in an increasing number of fields. However, due to the complexity of deployment environments or the prevalence of ambiguous-condition objects, the practical application of robotics still faces many challenges, leading to frequent errors. Traditional methods and some LLM-based approaches, although improved, still require substantial human intervention and struggle with autonomous error correction in complex scenarios.In this work, we propose RoboReflect, a novel framework leveraging large vision-language models (LVLMs) to enable self-reflection and autonomous error correction in robotic grasping tasks. RoboReflect allows robots to automatically adjust their strategies based on unsuccessful attempts until successful execution is achieved.The corrected strategies are saved in a memory for future task reference.We evaluate RoboReflect through extensive testing on eight common objects prone to ambiguous conditions of three categories.Our results demonstrate that RoboReflect not only outperforms existing grasp pose estimation methods like AnyGrasp and high-level action planning techniques using GPT-4V but also significantly enhances the robot's ability to adapt and correct errors independently. These findings underscore the critical importance of autonomous selfreflection in robotic systems while effectively addressing the challenges posed by ambiguous environments.
EquiBoost: An Equivariant Boosting Approach to Molecular Conformation Generation
Jan 09, 2025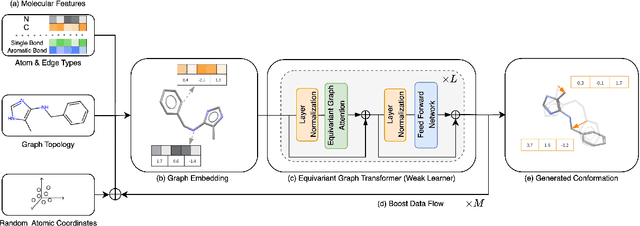
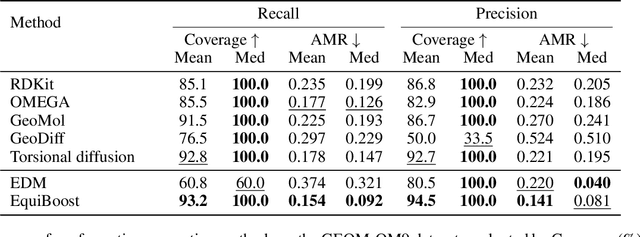
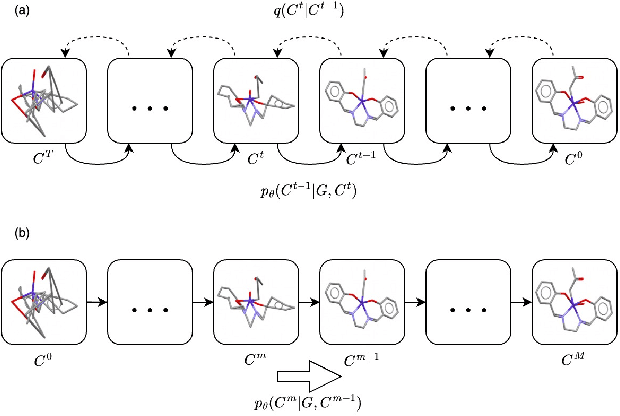
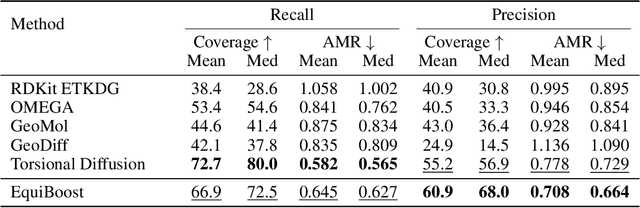
Molecular conformation generation plays key roles in computational drug design. Recently developed deep learning methods, particularly diffusion models have reached competitive performance over traditional cheminformatical approaches. However, these methods are often time-consuming or require extra support from traditional methods. We propose EquiBoost, a boosting model that stacks several equivariant graph transformers as weak learners, to iteratively refine 3D conformations of molecules. Without relying on diffusion techniques, EquiBoost balances accuracy and efficiency more effectively than diffusion-based methods. Notably, compared to the previous state-of-the-art diffusion method, EquiBoost improves generation quality and preserves diversity, achieving considerably better precision of Average Minimum RMSD (AMR) on the GEOM datasets. This work rejuvenates boosting and sheds light on its potential to be a robust alternative to diffusion models in certain scenarios.
EquiFlow: Equivariant Conditional Flow Matching with Optimal Transport for 3D Molecular Conformation Prediction
Dec 15, 2024
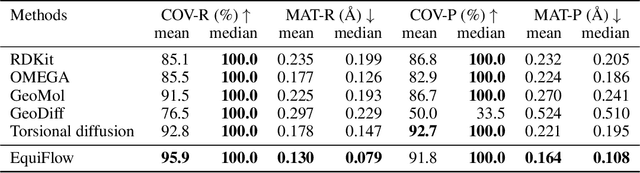


Molecular 3D conformations play a key role in determining how molecules interact with other molecules or protein surfaces. Recent deep learning advancements have improved conformation prediction, but slow training speeds and difficulties in utilizing high-degree features limit performance. We propose EquiFlow, an equivariant conditional flow matching model with optimal transport. EquiFlow uniquely applies conditional flow matching in molecular 3D conformation prediction, leveraging simulation-free training to address slow training speeds. It uses a modified Equiformer model to encode Cartesian molecular conformations along with their atomic and bond properties into higher-degree embeddings. Additionally, EquiFlow employs an ODE solver, providing faster inference speeds compared to diffusion models with SDEs. Experiments on the QM9 dataset show that EquiFlow predicts small molecule conformations more accurately than current state-of-the-art models.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024


Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
SniffySquad: Patchiness-Aware Gas Source Localization with Multi-Robot Collaboration
Nov 09, 2024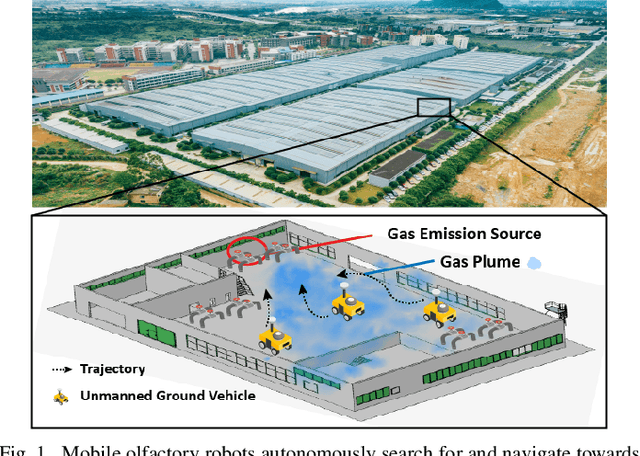
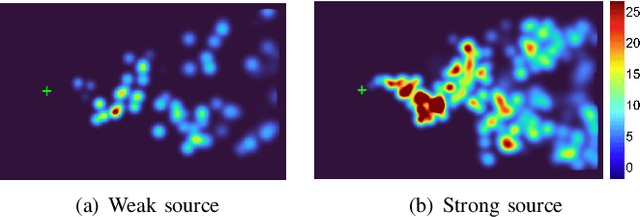
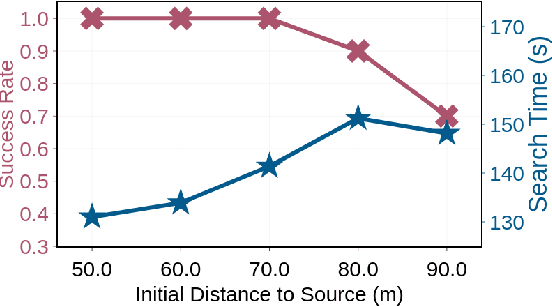
Gas source localization is pivotal for the rapid mitigation of gas leakage disasters, where mobile robots emerge as a promising solution. However, existing methods predominantly schedule robots' movements based on reactive stimuli or simplified gas plume models. These approaches typically excel in idealized, simulated environments but fall short in real-world gas environments characterized by their patchy distribution. In this work, we introduce SniffySquad, a multi-robot olfaction-based system designed to address the inherent patchiness in gas source localization. SniffySquad incorporates a patchiness-aware active sensing approach that enhances the quality of data collection and estimation. Moreover, it features an innovative collaborative role adaptation strategy to boost the efficiency of source-seeking endeavors. Extensive evaluations demonstrate that our system achieves an increase in the success rate by $20\%+$ and an improvement in path efficiency by $30\%+$, outperforming state-of-the-art gas source localization solutions.