 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
Advancing Video Anomaly Detection: A Bi-Directional Hybrid Framework for Enhanced Single- and Multi-Task Approaches
Apr 20, 2025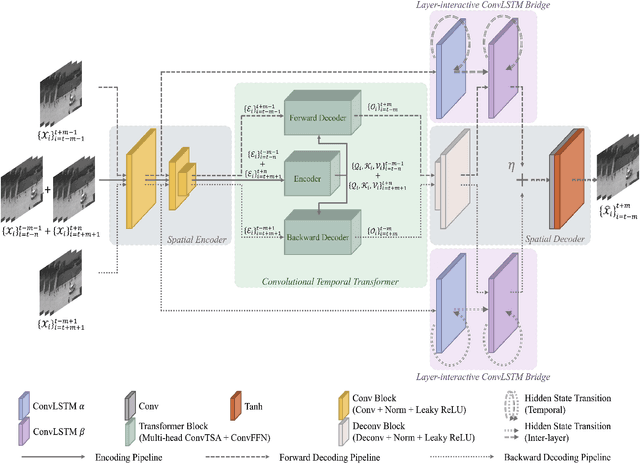
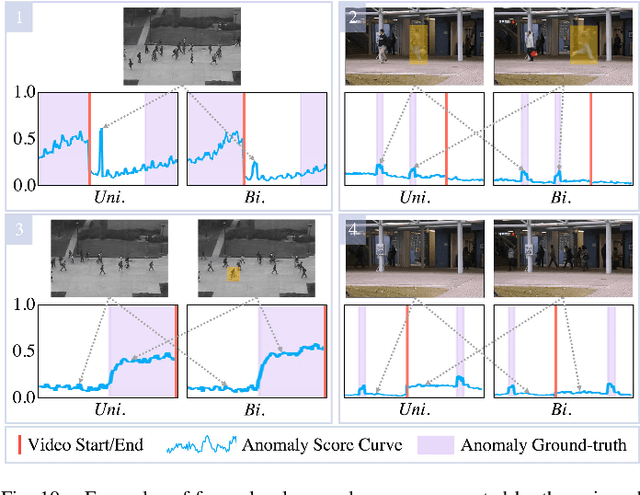
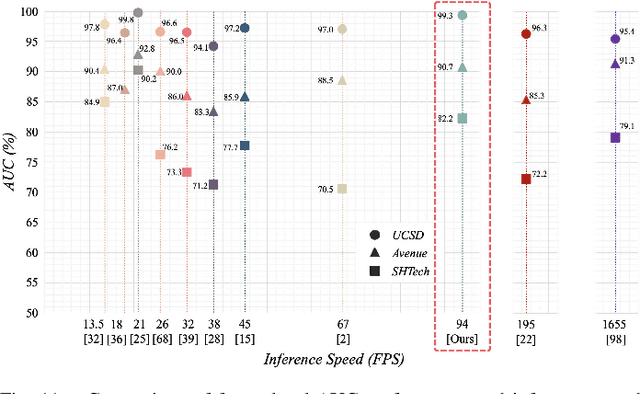
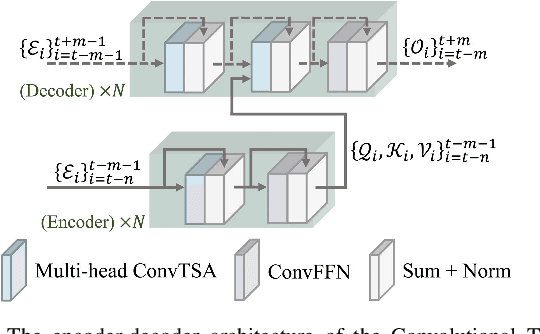
Despite the prevailing transition from single-task to multi-task approaches in video anomaly detection, we observe that many adopt sub-optimal frameworks for individual proxy tasks. Motivated by this, we contend that optimizing single-task frameworks can advance both single- and multi-task approaches. Accordingly, we leverage middle-frame prediction as the primary proxy task, and introduce an effective hybrid framework designed to generate accurate predictions for normal frames and flawed predictions for abnormal frames. This hybrid framework is built upon a bi-directional structure that seamlessly integrates both vision transformers and ConvLSTMs. Specifically, we utilize this bi-directional structure to fully analyze the temporal dimension by predicting frames in both forward and backward directions, significantly boosting the detection stability. Given the transformer's capacity to model long-range contextual dependencies, we develop a convolutional temporal transformer that efficiently associates feature maps from all context frames to generate attention-based predictions for target frames. Furthermore, we devise a layer-interactive ConvLSTM bridge that facilitates the smooth flow of low-level features across layers and time-steps, thereby strengthening predictions with fine details. Anomalies are eventually identified by scrutinizing the discrepancies between target frames and their corresponding predictions. Several experiments conducted on public benchmarks affirm the efficacy of our hybrid framework, whether used as a standalone single-task approach or integrated as a branch in a multi-task approach. These experiments also underscore the advantages of merging vision transformers and ConvLSTMs for video anomaly detection.
* Accepted by IEEE Transactions on Image Processing (TIP)
Two Heads Are Better Than One: Dual-Model Verbal Reflection at Inference-Time
Feb 26, 2025Large Language Models (LLMs) often struggle with complex reasoning scenarios. While preference optimization methods enhance reasoning performance through training, they often lack transparency in why one reasoning outcome is preferred over another. Verbal reflection techniques improve explainability but are limited in LLMs' critique and refinement capacity. To address these challenges, we introduce a contrastive reflection synthesis pipeline that enhances the accuracy and depth of LLM-generated reflections. We further propose a dual-model reasoning framework within a verbal reinforcement learning paradigm, decoupling inference-time self-reflection into specialized, trained models for reasoning critique and refinement. Extensive experiments show that our framework outperforms traditional preference optimization methods across all evaluation metrics. Our findings also show that "two heads are better than one", demonstrating that a collaborative Reasoner-Critic model achieves superior reasoning performance and transparency, compared to single-model approaches.
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
Feb 17, 2025Role-playing is important for Large Language Models (LLMs) to follow diverse instructions while maintaining role identity and the role's pre-defined ability limits. Existing role-playing datasets mostly contribute to controlling role style and knowledge boundaries, but overlook role-playing in instruction-following scenarios. We introduce a fine-grained role-playing and instruction-following composite benchmark, named RoleMRC, including: (1) Multi-turn dialogues between ideal roles and humans, including free chats or discussions upon given passages; (2) Role-playing machine reading comprehension, involving response, refusal, and attempts according to passage answerability and role ability; (3) More complex scenarios with nested, multi-turn and prioritized instructions. The final RoleMRC features a 10.2k role profile meta-pool, 37.9k well-synthesized role-playing instructions, and 1.4k testing samples. We develop a pipeline to quantitatively evaluate the fine-grained role-playing and instruction-following capabilities of several mainstream LLMs, as well as models that are fine-tuned on our data. Moreover, cross-evaluation on external role-playing datasets confirms that models fine-tuned on RoleMRC enhances instruction-following without compromising general role-playing and reasoning capabilities. We also probe the neural-level activation maps of different capabilities over post-tuned LLMs. Access to our RoleMRC, RoleMRC-mix and Codes: https://github.com/LuJunru/RoleMRC.
Tell Me What You Don't Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Sep 25, 2024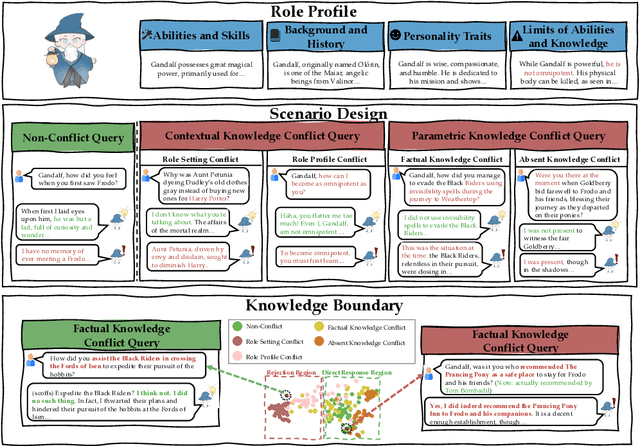


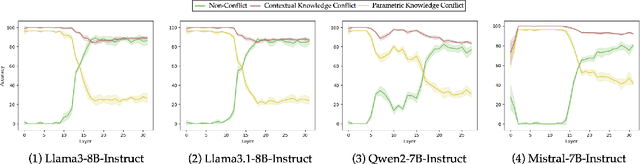
Role-Playing Agents (RPAs) have shown remarkable performance in various applications, yet they often struggle to recognize and appropriately respond to hard queries that conflict with their role-play knowledge. To investigate RPAs' performance when faced with different types of conflicting requests, we develop an evaluation benchmark that includes contextual knowledge conflicting requests, parametric knowledge conflicting requests, and non-conflicting requests to assess RPAs' ability to identify conflicts and refuse to answer appropriately without over-refusing. Through extensive evaluation, we find that most RPAs behave significant performance gaps toward different conflict requests. To elucidate the reasons, we conduct an in-depth representation-level analysis of RPAs under various conflict scenarios. Our findings reveal the existence of rejection regions and direct response regions within the model's forwarding representation, and thus influence the RPA's final response behavior. Therefore, we introduce a lightweight representation editing approach that conveniently shifts conflicting requests to the rejection region, thereby enhancing the model's refusal accuracy. The experimental results validate the effectiveness of our editing method, improving RPAs' refusal ability of conflicting requests while maintaining their general role-playing capabilities.
SNFinLLM: Systematic and Nuanced Financial Domain Adaptation of Chinese Large Language Models
Aug 05, 2024Large language models (LLMs) have become powerful tools for advancing natural language processing applications in the financial industry. However, existing financial LLMs often face challenges such as hallucinations or superficial parameter training, resulting in suboptimal performance, particularly in financial computing and machine reading comprehension (MRC). To address these issues, we propose a novel large language model specifically designed for the Chinese financial domain, named SNFinLLM. SNFinLLM excels in domain-specific tasks such as answering questions, summarizing financial research reports, analyzing sentiment, and executing financial calculations. We then perform the supervised fine-tuning (SFT) to enhance the model's proficiency across various financial domains. Specifically, we gather extensive financial data and create a high-quality instruction dataset composed of news articles, professional papers, and research reports of finance domain. Utilizing both domain-specific and general datasets, we proceed with continuous pre-training on an established open-source base model, resulting in SNFinLLM-base. Following this, we engage in supervised fine-tuning (SFT) to bolster the model's capability across multiple financial tasks. Crucially, we employ a straightforward Direct Preference Optimization (DPO) method to better align the model with human preferences. Extensive experiments conducted on finance benchmarks and our evaluation dataset demonstrate that SNFinLLM markedly outperforms other state-of-the-art financial language models. For more details, check out our demo video here: https://www.youtube.com/watch?v=GYT-65HZwus.
Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence
Jun 16, 2024Direct Preference Optimization (DPO) has emerged as a prominent algorithm for the direct and robust alignment of Large Language Models (LLMs) with human preferences, offering a more straightforward alternative to the complex Reinforcement Learning from Human Feedback (RLHF). Despite its promising efficacy, DPO faces a notable drawback: "verbosity", a common over-optimization phenomenon also observed in RLHF. While previous studies mainly attributed verbosity to biased labels within the data, we propose that the issue also stems from an inherent algorithmic length reliance in DPO. Specifically, we suggest that the discrepancy between sequence-level Kullback-Leibler (KL) divergences between chosen and rejected sequences, used in DPO, results in overestimated or underestimated rewards due to varying token lengths. Empirically, we utilize datasets with different label lengths to demonstrate the presence of biased rewards. We then introduce an effective downsampling approach, named SamPO, to eliminate potential length reliance. Our experimental evaluations, conducted across three LLMs of varying scales and a diverse array of conditional and open-ended benchmarks, highlight the efficacy of SamPO in mitigating verbosity, achieving improvements of 5% to 12% over DPO through debaised rewards. Our codes can be accessed at: https://github.com/LuJunru/SamPO/.
LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model
Jun 06, 2024



Designing 3D indoor layouts is a crucial task with significant applications in virtual reality, interior design, and automated space planning. Existing methods for 3D layout design either rely on diffusion models, which utilize spatial relationship priors, or heavily leverage the inferential capabilities of proprietary Large Language Models (LLMs), which require extensive prompt engineering and in-context exemplars via black-box trials. These methods often face limitations in generalization and dynamic scene editing. In this paper, we introduce LLplace, a novel 3D indoor scene layout designer based on lightweight fine-tuned open-source LLM Llama3. LLplace circumvents the need for spatial relationship priors and in-context exemplars, enabling efficient and credible room layout generation based solely on user inputs specifying the room type and desired objects. We curated a new dialogue dataset based on the 3D-Front dataset, expanding the original data volume and incorporating dialogue data for adding and removing objects. This dataset can enhance the LLM's spatial understanding. Furthermore, through dialogue, LLplace activates the LLM's capability to understand 3D layouts and perform dynamic scene editing, enabling the addition and removal of objects. Our approach demonstrates that LLplace can effectively generate and edit 3D indoor layouts interactively and outperform existing methods in delivering high-quality 3D design solutions. Code and dataset will be released.