 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatCoder: Self-Supervised Bidirectional Code-Documentation Learning via Back-Translation
Jan 30, 2026Training LLMs for code-related tasks typically depends on high-quality code-documentation pairs, which are costly to curate and often scarce for niche programming languages. We introduce BatCoder, a self-supervised reinforcement learning framework designed to jointly optimize code generation and documentation production. BatCoder employs a back-translation strategy: a documentation is first generated from code, and then the generated documentation is used to reconstruct the original code. The semantic similarity between the original and reconstructed code serves as an implicit reward, enabling reinforcement learning to improve the model's performance both in generating code from documentation and vice versa. This approach allows models to be trained using only code, substantially increasing the available training examples. Evaluated on HumanEval and MBPP with a 7B model, BatCoder achieved 83.5% and 81.0% pass@1, outperforming strong open-source baselines. Moreover, the framework demonstrates consistent scaling with respect to both training corpus size and model capacity.
Controllable Memory Usage: Balancing Anchoring and Innovation in Long-Term Human-Agent Interaction
Jan 08, 2026As LLM-based agents are increasingly used in long-term interactions, cumulative memory is critical for enabling personalization and maintaining stylistic consistency. However, most existing systems adopt an ``all-or-nothing'' approach to memory usage: incorporating all relevant past information can lead to \textit{Memory Anchoring}, where the agent is trapped by past interactions, while excluding memory entirely results in under-utilization and the loss of important interaction history. We show that an agent's reliance on memory can be modeled as an explicit and user-controllable dimension. We first introduce a behavioral metric of memory dependence to quantify the influence of past interactions on current outputs. We then propose \textbf{Stee}rable \textbf{M}emory Agent, \texttt{SteeM}, a framework that allows users to dynamically regulate memory reliance, ranging from a fresh-start mode that promotes innovation to a high-fidelity mode that closely follows interaction history. Experiments across different scenarios demonstrate that our approach consistently outperforms conventional prompting and rigid memory masking strategies, yielding a more nuanced and effective control for personalized human-agent collaboration.
Benchmark^2: Systematic Evaluation of LLM Benchmarks
Jan 07, 2026The rapid proliferation of benchmarks for evaluating large language models (LLMs) has created an urgent need for systematic methods to assess benchmark quality itself. We propose Benchmark^2, a comprehensive framework comprising three complementary metrics: (1) Cross-Benchmark Ranking Consistency, measuring whether a benchmark produces model rankings aligned with peer benchmarks; (2) Discriminability Score, quantifying a benchmark's ability to differentiate between models; and (3) Capability Alignment Deviation, identifying problematic instances where stronger models fail but weaker models succeed within the same model family. We conduct extensive experiments across 15 benchmarks spanning mathematics, reasoning, and knowledge domains, evaluating 11 LLMs across four model families. Our analysis reveals significant quality variations among existing benchmarks and demonstrates that selective benchmark construction based on our metrics can achieve comparable evaluation performance with substantially reduced test sets.
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025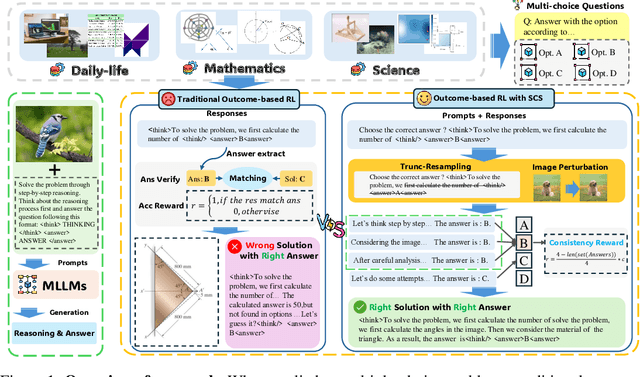
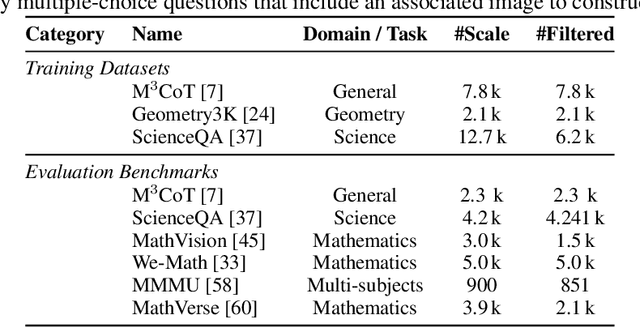
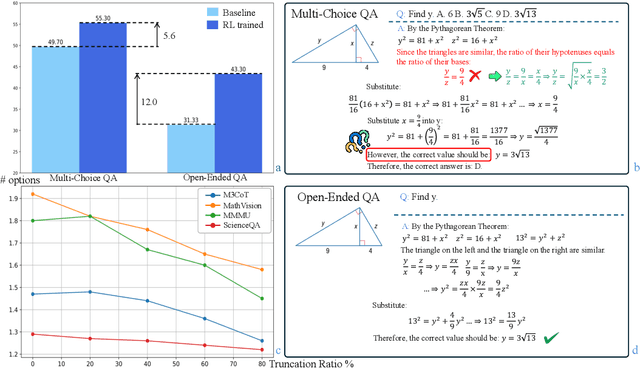
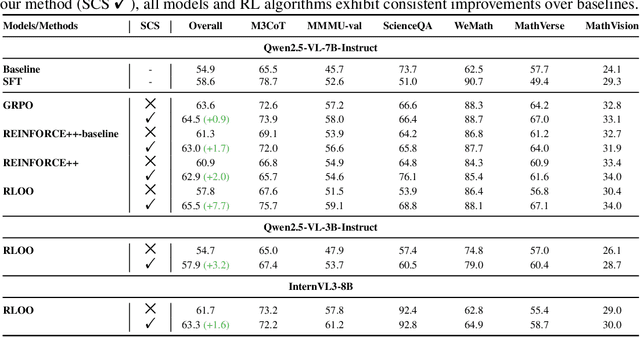
Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
Oct 16, 2025The edifice of native Vision-Language Models (VLMs) has emerged as a rising contender to typical modular VLMs, shaped by evolving model architectures and training paradigms. Yet, two lingering clouds cast shadows over its widespread exploration and promotion: (-) What fundamental constraints set native VLMs apart from modular ones, and to what extent can these barriers be overcome? (-) How to make research in native VLMs more accessible and democratized, thereby accelerating progress in the field. In this paper, we clarify these challenges and outline guiding principles for constructing native VLMs. Specifically, one native VLM primitive should: (i) effectively align pixel and word representations within a shared semantic space; (ii) seamlessly integrate the strengths of formerly separate vision and language modules; (iii) inherently embody various cross-modal properties that support unified vision-language encoding, aligning, and reasoning. Hence, we launch NEO, a novel family of native VLMs built from first principles, capable of rivaling top-tier modular counterparts across diverse real-world scenarios. With only 390M image-text examples, NEO efficiently develops visual perception from scratch while mitigating vision-language conflicts inside a dense and monolithic model crafted from our elaborate primitives. We position NEO as a cornerstone for scalable and powerful native VLMs, paired with a rich set of reusable components that foster a cost-effective and extensible ecosystem. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
Trade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025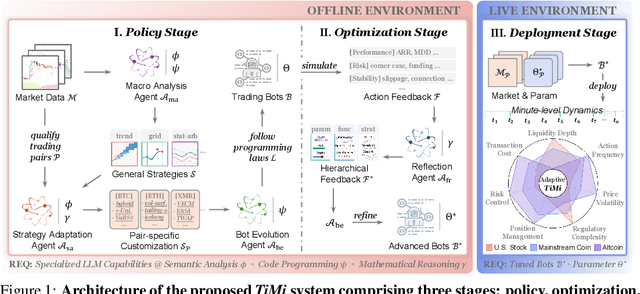
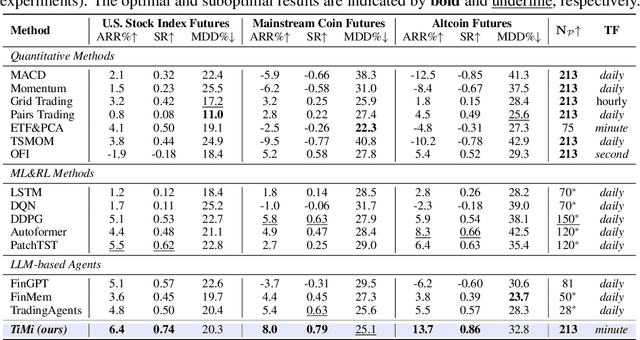
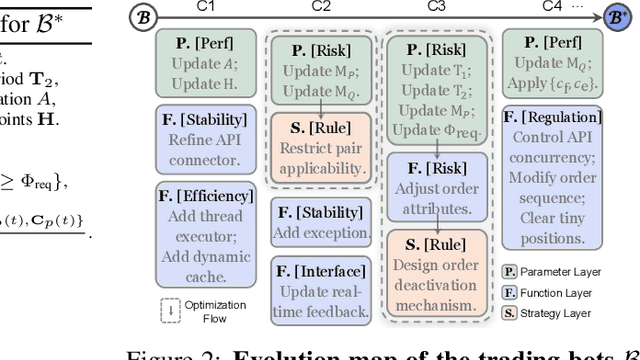
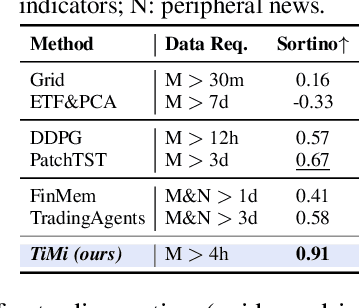
Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
Enhancing Model Privacy in Federated Learning with Random Masking and Quantization
Aug 27, 2025The primary goal of traditional federated learning is to protect data privacy by enabling distributed edge devices to collaboratively train a shared global model while keeping raw data decentralized at local clients. The rise of large language models (LLMs) has introduced new challenges in distributed systems, as their substantial computational requirements and the need for specialized expertise raise critical concerns about protecting intellectual property (IP). This highlights the need for a federated learning approach that can safeguard both sensitive data and proprietary models. To tackle this challenge, we propose FedQSN, a federated learning approach that leverages random masking to obscure a subnetwork of model parameters and applies quantization to the remaining parameters. Consequently, the server transmits only a privacy-preserving proxy of the global model to clients during each communication round, thus enhancing the model's confidentiality. Experimental results across various models and tasks demonstrate that our approach not only maintains strong model performance in federated learning settings but also achieves enhanced protection of model parameters compared to baseline methods.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
Improving Continual Pre-training Through Seamless Data Packing
May 29, 2025



Continual pre-training has demonstrated significant potential in enhancing model performance, particularly in domain-specific scenarios. The most common approach for packing data before continual pre-training involves concatenating input texts and splitting them into fixed-length sequences. While straightforward and efficient, this method often leads to excessive truncation and context discontinuity, which can hinder model performance. To address these issues, we explore the potential of data engineering to enhance continual pre-training, particularly its impact on model performance and efficiency. We propose Seamless Packing (SP), a novel data packing strategy aimed at preserving contextual information more effectively and enhancing model performance. Our approach employs a sliding window technique in the first stage that synchronizes overlapping tokens across consecutive sequences, ensuring better continuity and contextual coherence. In the second stage, we adopt a First-Fit-Decreasing algorithm to pack shorter texts into bins slightly larger than the target sequence length, thereby minimizing padding and truncation. Empirical evaluations across various model architectures and corpus domains demonstrate the effectiveness of our method, outperforming baseline method in 99% of all settings. Code is available at https://github.com/Infernus-WIND/Seamless-Packing.
RECAST: Strengthening LLMs' Complex Instruction Following with Constraint-Verifiable Data
May 25, 2025Large language models (LLMs) are increasingly expected to tackle complex tasks, driven by their expanding applications and users' growing proficiency in crafting sophisticated prompts. However, as the number of explicitly stated requirements increases (particularly more than 10 constraints), LLMs often struggle to accurately follow such complex instructions. To address this challenge, we propose RECAST, a novel framework for synthesizing datasets where each example incorporates far more constraints than those in existing benchmarks. These constraints are extracted from real-world prompt-response pairs to ensure practical relevance. RECAST enables automatic verification of constraint satisfaction via rule-based validators for quantitative constraints and LLM-based validators for qualitative ones. Using this framework, we construct RECAST-30K, a large-scale, high-quality dataset comprising 30k instances spanning 15 constraint types. Experimental results demonstrate that models fine-tuned on RECAST-30K show substantial improvements in following complex instructions. Moreover, the verifiability provided by RECAST enables the design of reward functions for reinforcement learning, which further boosts model performance on complex and challenging tasks.