 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark^2: Systematic Evaluation of LLM Benchmarks
Jan 07, 2026The rapid proliferation of benchmarks for evaluating large language models (LLMs) has created an urgent need for systematic methods to assess benchmark quality itself. We propose Benchmark^2, a comprehensive framework comprising three complementary metrics: (1) Cross-Benchmark Ranking Consistency, measuring whether a benchmark produces model rankings aligned with peer benchmarks; (2) Discriminability Score, quantifying a benchmark's ability to differentiate between models; and (3) Capability Alignment Deviation, identifying problematic instances where stronger models fail but weaker models succeed within the same model family. We conduct extensive experiments across 15 benchmarks spanning mathematics, reasoning, and knowledge domains, evaluating 11 LLMs across four model families. Our analysis reveals significant quality variations among existing benchmarks and demonstrates that selective benchmark construction based on our metrics can achieve comparable evaluation performance with substantially reduced test sets.
RECAST: Strengthening LLMs' Complex Instruction Following with Constraint-Verifiable Data
May 25, 2025Large language models (LLMs) are increasingly expected to tackle complex tasks, driven by their expanding applications and users' growing proficiency in crafting sophisticated prompts. However, as the number of explicitly stated requirements increases (particularly more than 10 constraints), LLMs often struggle to accurately follow such complex instructions. To address this challenge, we propose RECAST, a novel framework for synthesizing datasets where each example incorporates far more constraints than those in existing benchmarks. These constraints are extracted from real-world prompt-response pairs to ensure practical relevance. RECAST enables automatic verification of constraint satisfaction via rule-based validators for quantitative constraints and LLM-based validators for qualitative ones. Using this framework, we construct RECAST-30K, a large-scale, high-quality dataset comprising 30k instances spanning 15 constraint types. Experimental results demonstrate that models fine-tuned on RECAST-30K show substantial improvements in following complex instructions. Moreover, the verifiability provided by RECAST enables the design of reward functions for reinforcement learning, which further boosts model performance on complex and challenging tasks.
Spiking Convolutional Neural Networks for Text Classification
Jun 27, 2024



Spiking neural networks (SNNs) offer a promising pathway to implement deep neural networks (DNNs) in a more energy-efficient manner since their neurons are sparsely activated and inferences are event-driven. However, there have been very few works that have demonstrated the efficacy of SNNs in language tasks partially because it is non-trivial to represent words in the forms of spikes and to deal with variable-length texts by SNNs. This work presents a "conversion + fine-tuning" two-step method for training SNNs for text classification and proposes a simple but effective way to encode pre-trained word embeddings as spike trains. We show empirically that after fine-tuning with surrogate gradients, the converted SNNs achieve comparable results to their DNN counterparts with much less energy consumption across multiple datasets for both English and Chinese. We also show that such SNNs are more robust to adversarial attacks than DNNs.
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
Oct 12, 2023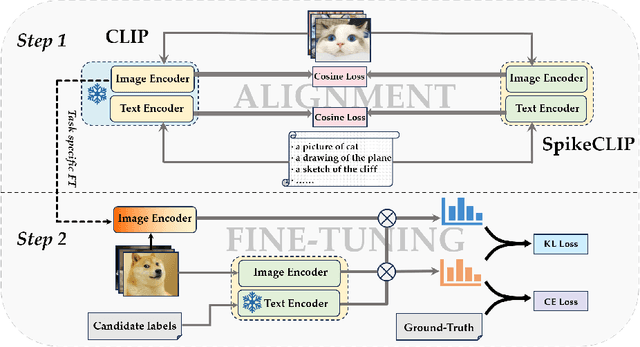
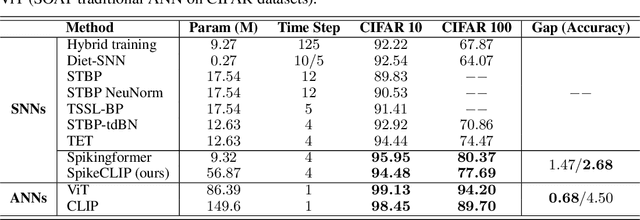
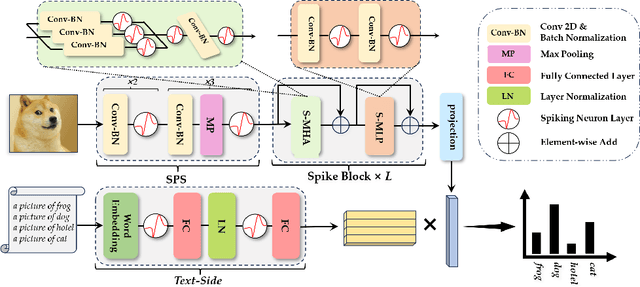

Spiking neural networks (SNNs) have demonstrated the capability to achieve comparable performance to deep neural networks (DNNs) in both visual and linguistic domains while offering the advantages of improved energy efficiency and adherence to biological plausibility. However, the extension of such single-modality SNNs into the realm of multimodal scenarios remains an unexplored territory. Drawing inspiration from the concept of contrastive language-image pre-training (CLIP), we introduce a novel framework, named SpikeCLIP, to address the gap between two modalities within the context of spike-based computing through a two-step recipe involving ``Alignment Pre-training + Dual-Loss Fine-tuning". Extensive experiments demonstrate that SNNs achieve comparable results to their DNN counterparts while significantly reducing energy consumption across a variety of datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust performance in image classification tasks that involve class labels not predefined within specific categories.
SpikeBERT: A Language Spikformer Trained with Two-Stage Knowledge Distillation from BERT
Aug 30, 2023
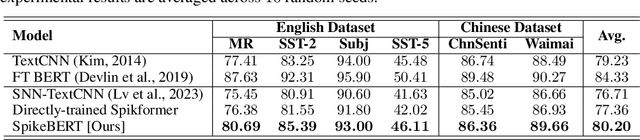


Spiking neural networks (SNNs) offer a promising avenue to implement deep neural networks in a more energy-efficient way. However, the network architectures of existing SNNs for language tasks are too simplistic, and deep architectures have not been fully explored, resulting in a significant performance gap compared to mainstream transformer-based networks such as BERT. To this end, we improve a recently-proposed spiking transformer (i.e., Spikformer) to make it possible to process language tasks and propose a two-stage knowledge distillation method for training it, which combines pre-training by distilling knowledge from BERT with a large collection of unlabelled texts and fine-tuning with task-specific instances via knowledge distillation again from the BERT fine-tuned on the same training examples. Through extensive experimentation, we show that the models trained with our method, named SpikeBERT, outperform state-of-the-art SNNs and even achieve comparable results to BERTs on text classification tasks for both English and Chinese with much less energy consumption.
Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution
Aug 29, 2021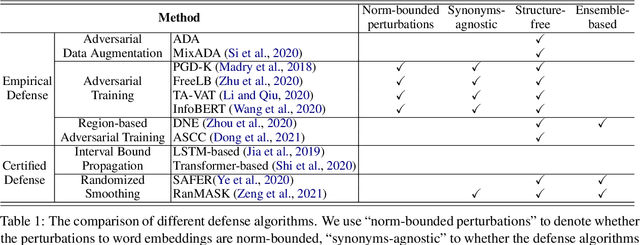
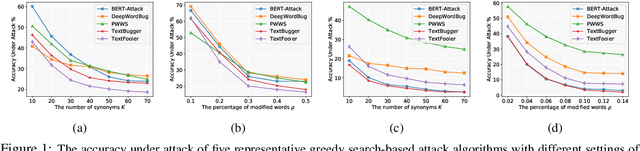
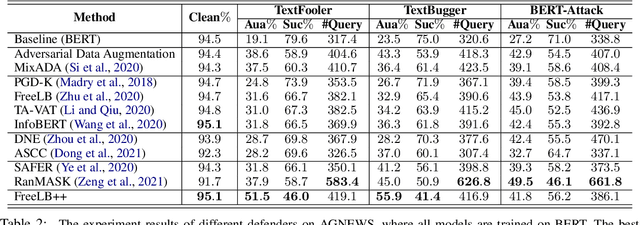
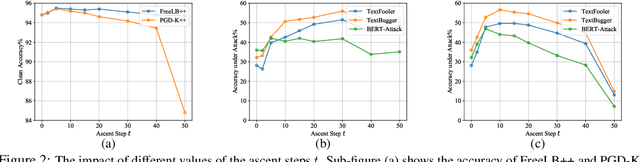
Recent studies have shown that deep neural networks are vulnerable to intentionally crafted adversarial examples, and various methods have been proposed to defend against adversarial word-substitution attacks for neural NLP models. However, there is a lack of systematic study on comparing different defense approaches under the same attacking setting. In this paper, we seek to fill the gap of systematic studies through comprehensive researches on understanding the behavior of neural text classifiers trained by various defense methods under representative adversarial attacks. In addition, we propose an effective method to further improve the robustness of neural text classifiers against such attacks and achieved the highest accuracy on both clean and adversarial examples on AGNEWS and IMDB datasets by a significant margin.
Certified Robustness to Text Adversarial Attacks by Randomized [MASK]
May 08, 2021![Figure 1 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table1-1.png&w=640&q=75)
![Figure 3 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Certified Robustness to Text Adversarial Attacks by Randomized [MASK]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa2a0c319bacecf0eb6e1e875a40ce652e32daef6%2F7-Table2-1.png&w=640&q=75)
Recently, few certified defense methods have been developed to provably guarantee the robustness of a text classifier to adversarial synonym substitutions. However, all existing certified defense methods assume that the defenders are informed of how the adversaries generate synonyms, which is not a realistic scenario. In this paper, we propose a certifiably robust defense method by randomly masking a certain proportion of the words in an input text, in which the above unrealistic assumption is no longer necessary. The proposed method can defend against not only word substitution-based attacks, but also character-level perturbations. We can certify the classifications of over 50% texts to be robust to any perturbation of 5 words on AGNEWS, and 2 words on SST2 dataset. The experimental results show that our randomized smoothing method significantly outperforms recently proposed defense methods across multiple datasets.